Self-Specialization: Uncovering Latent Expertise within Large Language Models
2310.00160
0
0
Abstract
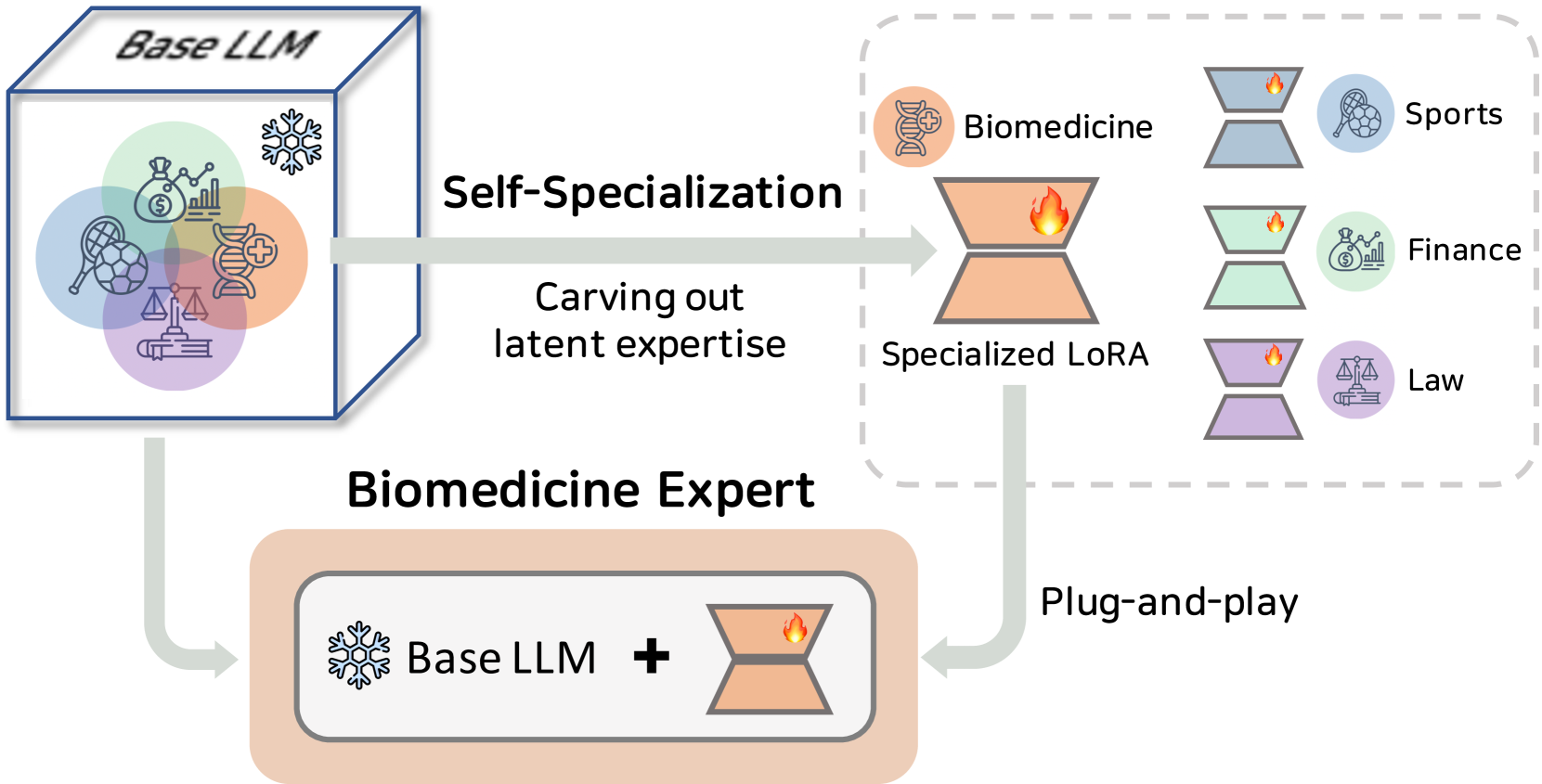
Recent works have demonstrated the effectiveness of self-alignment in which a large language model is aligned to follow general instructions using instructional data generated from the model itself starting from a handful of human-written seeds. Instead of general alignment, in this work, we focus on self-alignment for expert domain specialization (e.g., biomedicine, finance). As a preliminary, we quantitively show the marginal effect that generic instruction-following training has on downstream expert domains' performance. To remedy this, we propose self-specialization - allowing for effective model specialization while achieving cross-task generalization by leveraging only a few labeled seeds. Self-specialization offers a data- and parameter-efficient way of carving out an expert model out of a generalist pre-trained LLM. Exploring a variety of popular open large models as a base for specialization, our experimental results in both biomedical and financial domains show that our self-specialized models outperform their base models by a large margin, and even larger models that are generally instruction-tuned or that have been adapted to the target domain by other means.
Create account to get full access
Overview
- This paper explores a novel approach called "self-specialization" to uncover the latent expertise hidden within large language models (LLMs).
- The researchers propose a method to fine-tune LLMs on specialized tasks, allowing the models to self-specialize and develop expertise in various domains.
- The study benchmarks the performance of existing aligned models and then introduces the self-specialization technique as an alternative approach.
Plain English Explanation
Large language models (LLMs) like GPT-3 are incredibly powerful and can perform a wide variety of tasks. However, these models often lack specialized expertise in certain domains. The Self-Instruction: Aligning Language Models with their Own Thought Process and CodeCLM: Aligning Language Models to Tailored Synthetic Data papers have explored ways to align LLMs with specific tasks, but this paper proposes a different approach called "self-specialization."
The idea behind self-specialization is to fine-tune the LLM on specialized tasks, allowing the model to develop its own expertise in various domains. This is different from traditional fine-tuning, where the model is trained on a specific dataset for a particular task. With self-specialization, the model is encouraged to discover and cultivate its own latent expertise, rather than being explicitly trained on a narrow set of tasks.
The researchers first benchmark the performance of existing aligned models, which serve as a baseline for comparison. They then introduce the self-specialization technique and demonstrate its ability to uncover the hidden expertise within the LLM, allowing it to perform better on specialized tasks.
Technical Explanation
The researchers begin by benchmarking the performance of existing aligned models, such as those presented in the Matching Domain Experts by Training from Scratch and Survey of Self-Evolution in Large Language Models papers. This serves as a baseline for comparison and helps establish the current state of the art in task-specific LLM performance.
The core of the paper introduces the self-specialization technique. The researchers fine-tune the LLM on a diverse set of specialized tasks, allowing the model to self-discover and cultivate its own expertise in various domains. This is in contrast to traditional fine-tuning, where the model is explicitly trained on a specific dataset for a particular task.
The self-specialization process encourages the LLM to recognize and leverage its latent capabilities, resulting in improved performance on specialized tasks compared to the baseline aligned models. The researchers experiment with different fine-tuning strategies and task-specific datasets to demonstrate the effectiveness of their approach.
Critical Analysis
The paper presents a promising approach to enhancing the specialized capabilities of large language models. By allowing the models to self-specialize, the researchers unlock the models' hidden expertise, which can be valuable in real-world applications.
However, the paper does not delve into the potential limitations or challenges of the self-specialization approach. For example, it is unclear how the method scales to a larger number of specialized tasks or how it performs on tasks with limited training data. Additionally, the paper does not discuss the computational and memory requirements of the fine-tuning process, which could be a practical concern for deploying these models in resource-constrained environments.
Further research could explore the robustness and generalization capabilities of self-specialized models, as well as investigate potential ways to make the fine-tuning process more efficient and scalable. Additionally, a more comprehensive comparison with other alignment techniques, such as those presented in the Generation-Driven Contrastive Self-Training for Zero-Shot paper, could provide additional insights.
Conclusion
This paper introduces a novel approach called "self-specialization" to uncover the latent expertise within large language models. By fine-tuning the models on diverse specialized tasks, the researchers enable the models to self-discover and cultivate their own expertise, leading to improved performance on a range of specialized tasks.
The self-specialization technique offers a promising alternative to traditional fine-tuning approaches, as it allows language models to leverage their inherent capabilities in a more organic and efficient manner. While the paper presents compelling results, further research is needed to address potential limitations and explore the broader implications of this approach for enhancing the specialized capabilities of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Matching domain experts by training from scratch on domain knowledge
Xiaoliang Luo, Guangzhi Sun, Bradley C. Love
0
0
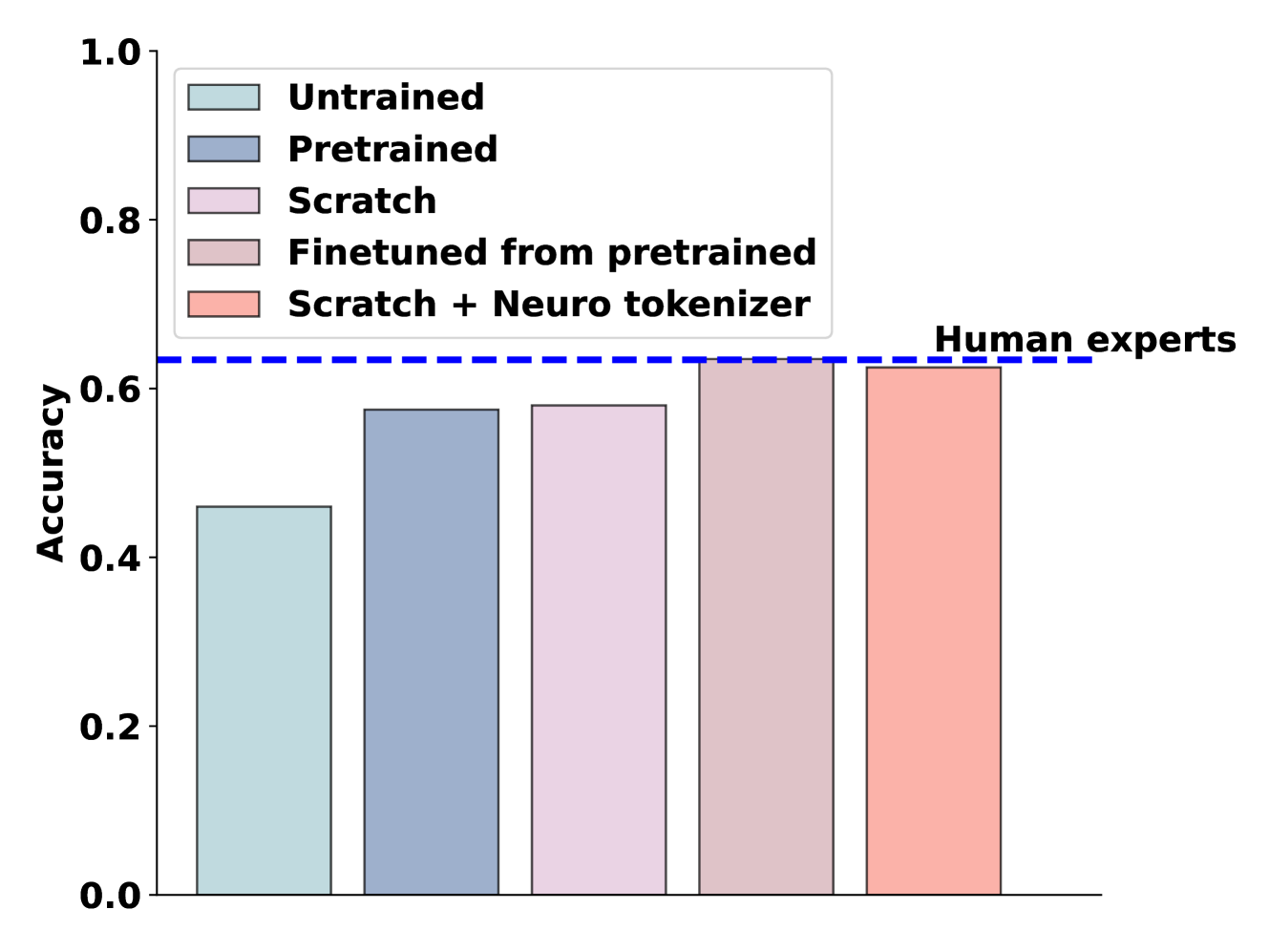
Recently, large language models (LLMs) have outperformed human experts in predicting the results of neuroscience experiments (Luo et al., 2024). What is the basis for this performance? One possibility is that statistical patterns in that specific scientific literature, as opposed to emergent reasoning abilities arising from broader training, underlie LLMs' performance. To evaluate this possibility, we trained (next word prediction) a relatively small 124M-parameter GPT-2 model on 1.3 billion tokens of domain-specific knowledge. Despite being orders of magnitude smaller than larger LLMs trained on trillions of tokens, small models achieved expert-level performance in predicting neuroscience results. Small models trained on the neuroscience literature succeeded when they were trained from scratch using a tokenizer specifically trained on neuroscience text or when the neuroscience literature was used to finetune a pretrained GPT-2. Our results indicate that expert-level performance may be attained by even small LLMs through domain-specific, auto-regressive training approaches.
5/16/2024
Self-training Large Language Models through Knowledge Detection
Wei Jie Yeo, Teddy Ferdinan, Przemyslaw Kazienko, Ranjan Satapathy, Erik Cambria
0
0
Large language models (LLMs) often necessitate extensive labeled datasets and training compute to achieve impressive performance across downstream tasks. This paper explores a self-training paradigm, where the LLM autonomously curates its own labels and selectively trains on unknown data samples identified through a reference-free consistency method. Empirical evaluations demonstrate significant improvements in reducing hallucination in generation across multiple subjects. Furthermore, the selective training framework mitigates catastrophic forgetting in out-of-distribution benchmarks, addressing a critical limitation in training LLMs. Our findings suggest that such an approach can substantially reduce the dependency on large labeled datasets, paving the way for more scalable and cost-effective language model training.
6/18/2024
A Survey on Self-Evolution of Large Language Models
Zhengwei Tao, Ting-En Lin, Xiancai Chen, Hangyu Li, Yuchuan Wu, Yongbin Li, Zhi Jin, Fei Huang, Dacheng Tao, Jingren Zhou
0
0
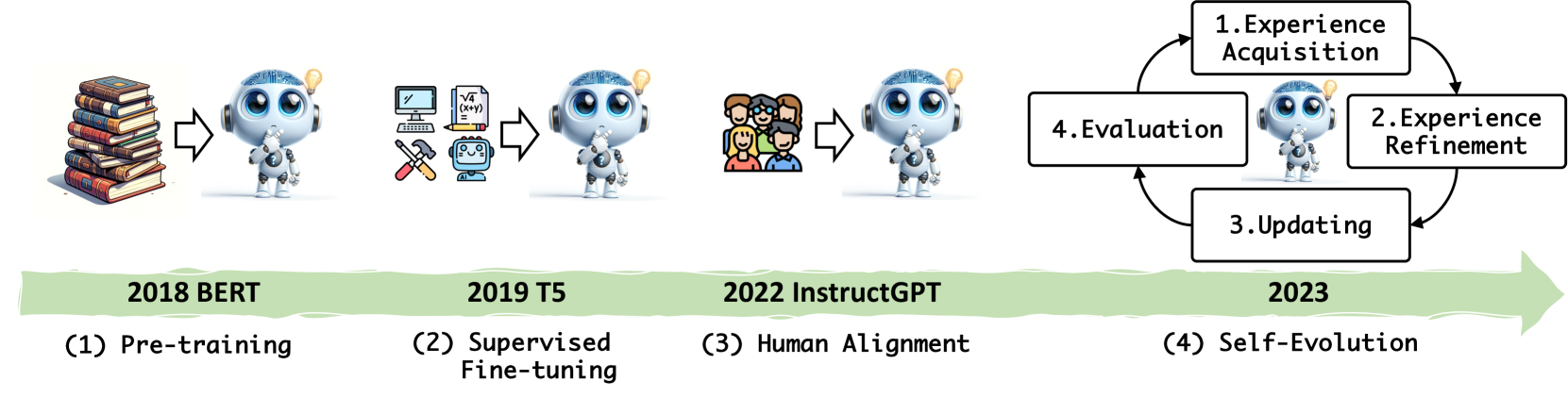
Large language models (LLMs) have significantly advanced in various fields and intelligent agent applications. However, current LLMs that learn from human or external model supervision are costly and may face performance ceilings as task complexity and diversity increase. To address this issue, self-evolution approaches that enable LLM to autonomously acquire, refine, and learn from experiences generated by the model itself are rapidly growing. This new training paradigm inspired by the human experiential learning process offers the potential to scale LLMs towards superintelligence. In this work, we present a comprehensive survey of self-evolution approaches in LLMs. We first propose a conceptual framework for self-evolution and outline the evolving process as iterative cycles composed of four phases: experience acquisition, experience refinement, updating, and evaluation. Second, we categorize the evolution objectives of LLMs and LLM-based agents; then, we summarize the literature and provide taxonomy and insights for each module. Lastly, we pinpoint existing challenges and propose future directions to improve self-evolution frameworks, equipping researchers with critical insights to fast-track the development of self-evolving LLMs. Our corresponding GitHub repository is available at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/Awesome-Self-Evolution-of-LLM
6/4/2024

X-Instruction: Aligning Language Model in Low-resource Languages with Self-curated Cross-lingual Instructions
Chong Li, Wen Yang, Jiajun Zhang, Jinliang Lu, Shaonan Wang, Chengqing Zong
0
0
Large language models respond well in high-resource languages like English but struggle in low-resource languages. It may arise from the lack of high-quality instruction following data in these languages. Directly translating English samples into these languages can be a solution but unreliable, leading to responses with translation errors and lacking language-specific or cultural knowledge. To address this issue, we propose a novel method to construct cross-lingual instruction following samples with instruction in English and response in low-resource languages. Specifically, the language model first learns to generate appropriate English instructions according to the natural web texts in other languages as responses. The candidate cross-lingual instruction tuning samples are further refined and diversified. We have employed this method to build a large-scale cross-lingual instruction tuning dataset on 10 languages, namely X-Instruction. The instruction data built using our method incorporate more language-specific knowledge compared with the naive translation method. Experimental results have shown that the response quality of the model tuned on X-Instruction greatly exceeds the model distilled from a powerful teacher model, reaching or even surpassing the ones of ChatGPT. In addition, we find that models tuned on cross-lingual instruction following samples can follow the instruction in the output language without further tuning.
5/31/2024