Self-training Large Language Models through Knowledge Detection
2406.11275
0
0
Abstract
Large language models (LLMs) often necessitate extensive labeled datasets and training compute to achieve impressive performance across downstream tasks. This paper explores a self-training paradigm, where the LLM autonomously curates its own labels and selectively trains on unknown data samples identified through a reference-free consistency method. Empirical evaluations demonstrate significant improvements in reducing hallucination in generation across multiple subjects. Furthermore, the selective training framework mitigates catastrophic forgetting in out-of-distribution benchmarks, addressing a critical limitation in training LLMs. Our findings suggest that such an approach can substantially reduce the dependency on large labeled datasets, paving the way for more scalable and cost-effective language model training.
Create account to get full access
Overview
- This paper explores a novel approach to self-training large language models (LLMs) without the need for external supervision.
- The key idea is to leverage the model's own knowledge detection capabilities to identify and learn from its own mistakes during the training process.
- The authors propose a self-training framework that enables LLMs to autonomously enhance their capabilities over time, potentially leading to more robust and capable models.
Plain English Explanation
The researchers in this paper have come up with a way for large language models (LLMs) to essentially teach themselves, without relying on external data or human oversight. LLMs are powerful AI systems that can generate human-like text, but they typically require a lot of labeled data to be trained effectively.
The researchers' approach is to have the LLM monitor its own behavior during training and identify areas where it's making mistakes or gaps in its knowledge. Then, it can use that self-awareness to figure out how to improve itself, without needing someone to point out its mistakes. This self-training process allows the LLM to gradually become more knowledgeable and capable over time, like a human learning and growing.
The key innovation here is that the LLM is essentially teaching itself, much like how children learn and develop without constant external guidance. This could lead to LLMs that are more robust, reliable, and adaptive, since they're not entirely reliant on the data they were initially trained on. However, the researchers also caution that self-training LLMs comes with its own risks that need to be carefully considered.
Technical Explanation
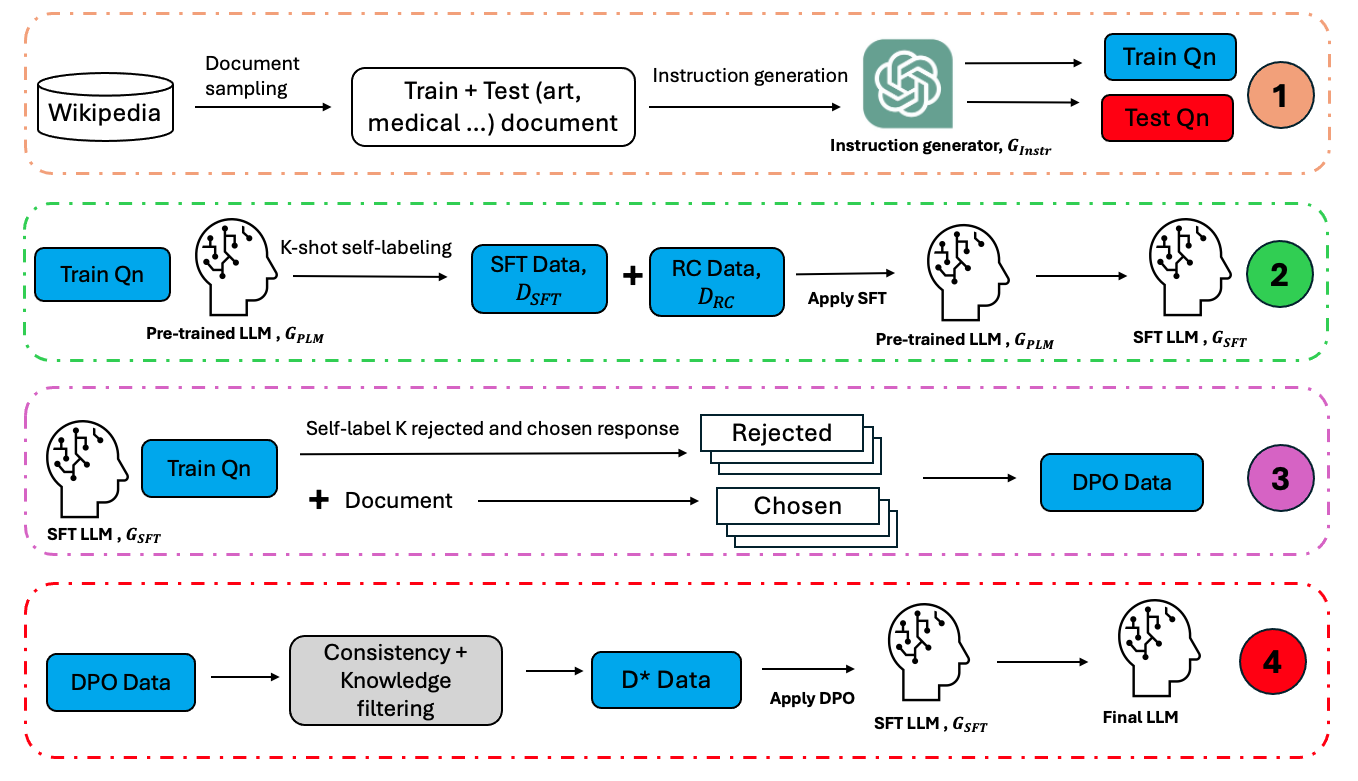
The paper proposes a self-training framework for large language models (LLMs) that enables them to autonomously enhance their capabilities over time. The core idea is to leverage the model's own knowledge detection capabilities to identify and learn from its own mistakes during the training process.
The authors introduce a two-stage training procedure. In the first stage, the LLM is trained on a traditional supervised task. In the second stage, the model is allowed to self-train by detecting its own knowledge gaps and generating additional training data to address them.
Specifically, the LLM is tasked with predicting whether its own generated tokens are correct or not. By monitoring its own performance on this self-evaluation task, the model can identify areas where it is making mistakes or lacks knowledge. It then uses this self-detected knowledge to generate new training examples, which are used to fine-tune the model and improve its capabilities.
The authors evaluate their approach on a diverse set of benchmarks, including language understanding, generation, and reasoning tasks. The results suggest that LLMs can indeed autonomously learn and enhance their capabilities through this self-training process, outperforming traditional supervised training approaches.
Critical Analysis
The proposed self-training framework represents an intriguing step towards more autonomous and self-improving large language models. By enabling LLMs to detect and learn from their own mistakes, the approach holds the promise of developing more robust and capable models that are less reliant on external supervision.
However, the researchers acknowledge that self-training LLMs also comes with potential risks and limitations that need to be carefully considered. For example, the model may reinforce its own biases or develop blind spots if its self-evaluation is not sufficiently reliable. There are also open questions about the scalability and generalizability of the approach across different types of LLMs and tasks.
Furthermore, the paper does not deeply explore the ethical implications of self-training LLMs, such as the potential for unintended consequences or the challenges of maintaining transparency and accountability. As these models become more autonomous, it will be crucial to develop robust safeguards and governance frameworks to ensure they are developed and deployed responsibly.
Overall, while the proposed self-training framework represents an exciting advancement in the field of large language models, further research and careful consideration of the associated risks and challenges will be necessary to unlock the full potential of this approach.
Conclusion
This paper introduces a novel self-training framework for large language models that enables them to autonomously enhance their capabilities over time. By leveraging the model's own knowledge detection capabilities, the approach allows LLMs to identify and learn from their own mistakes, reducing their reliance on external supervision.
The results demonstrate the potential of this self-training approach to produce more robust and capable language models, with implications for a wide range of applications. However, the researchers also highlight the need to carefully consider the risks and limitations of such autonomous systems, particularly around issues of reliability, bias, and ethical considerations.
As the field of large language models continues to evolve, approaches like the one proposed in this paper will be instrumental in driving progress towards more self-sufficient and adaptable AI systems. But this progress must be balanced with a deep understanding of the associated challenges and a commitment to developing these technologies responsibly and for the benefit of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LLMs Could Autonomously Learn Without External Supervision
Ke Ji, Junying Chen, Anningzhe Gao, Wenya Xie, Xiang Wan, Benyou Wang
0
0
In the quest for super-human performance, Large Language Models (LLMs) have traditionally been tethered to human-annotated datasets and predefined training objectives-a process that is both labor-intensive and inherently limited. This paper presents a transformative approach: Autonomous Learning for LLMs, a self-sufficient learning paradigm that frees models from the constraints of human supervision. This method endows LLMs with the ability to self-educate through direct interaction with text, akin to a human reading and comprehending literature. Our approach eliminates the reliance on annotated data, fostering an Autonomous Learning environment where the model independently identifies and reinforces its knowledge gaps. Empirical results from our comprehensive experiments, which utilized a diverse array of learning materials and were evaluated against standard public quizzes, reveal that Autonomous Learning outstrips the performance of both Pre-training and Supervised Fine-Tuning (SFT), as well as retrieval-augmented methods. These findings underscore the potential of Autonomous Learning to not only enhance the efficiency and effectiveness of LLM training but also to pave the way for the development of more advanced, self-reliant AI systems.
6/10/2024
💬
Into the Unknown: Self-Learning Large Language Models
Teddy Ferdinan, Jan Koco'n, Przemys{l}aw Kazienko
0
0
We address the main problem of self-learning LLM: the question of what to learn. We propose a self-learning LLM framework that enables an LLM to independently learn previously unknown knowledge through selfassessment of their own hallucinations. Using the hallucination score, we introduce a new concept of Points in the Unknown (PiUs), along with one extrinsic and three intrinsic methods for automatic PiUs identification. It facilitates the creation of a self-learning loop that focuses exclusively on the knowledge gap in Points in the Unknown, resulting in a reduced hallucination score. We also developed evaluation metrics for gauging an LLM's self-learning capability. Our experiments revealed that 7B-Mistral models that have been finetuned or aligned and RWKV5-Eagle are capable of self-learning considerably well. Our self-learning concept allows more efficient LLM updates and opens new perspectives for knowledge exchange. It may also increase public trust in AI.
6/5/2024

New!Self-Cognition in Large Language Models: An Exploratory Study
Dongping Chen, Jiawen Shi, Yao Wan, Pan Zhou, Neil Zhenqiang Gong, Lichao Sun
0
0
While Large Language Models (LLMs) have achieved remarkable success across various applications, they also raise concerns regarding self-cognition. In this paper, we perform a pioneering study to explore self-cognition in LLMs. Specifically, we first construct a pool of self-cognition instruction prompts to evaluate where an LLM exhibits self-cognition and four well-designed principles to quantify LLMs' self-cognition. Our study reveals that 4 of the 48 models on Chatbot Arena--specifically Command R, Claude3-Opus, Llama-3-70b-Instruct, and Reka-core--demonstrate some level of detectable self-cognition. We observe a positive correlation between model size, training data quality, and self-cognition level. Additionally, we also explore the utility and trustworthiness of LLM in the self-cognition state, revealing that the self-cognition state enhances some specific tasks such as creative writing and exaggeration. We believe that our work can serve as an inspiration for further research to study the self-cognition in LLMs.
7/2/2024
Think Twice Before Trusting: Self-Detection for Large Language Models through Comprehensive Answer Reflection
Moxin Li, Wenjie Wang, Fuli Feng, Fengbin Zhu, Qifan Wang, Tat-Seng Chua
0
0
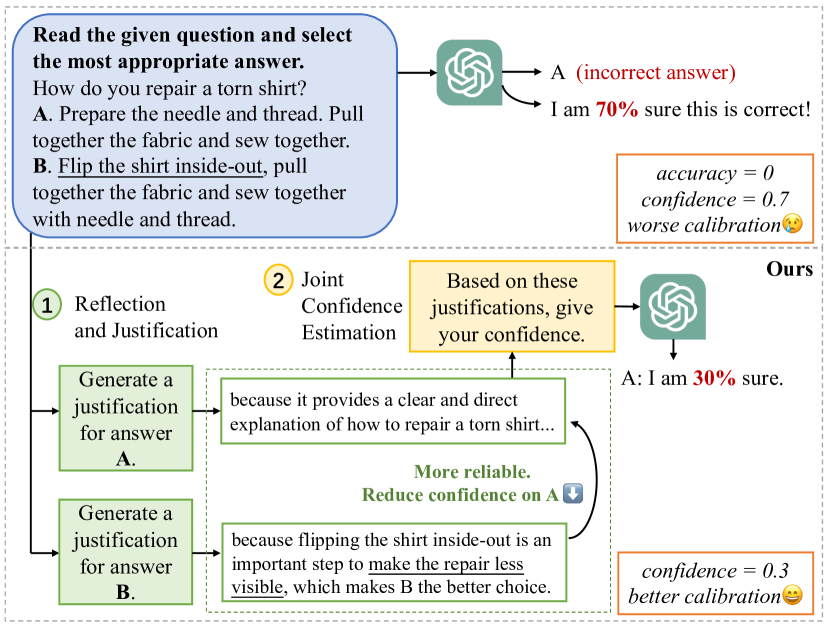
Self-detection for Large Language Model (LLM) seeks to evaluate the LLM output trustability by leveraging LLM's own capabilities, alleviating the output hallucination issue. However, existing self-detection approaches only retrospectively evaluate answers generated by LLM, typically leading to the over-trust in incorrectly generated answers. To tackle this limitation, we propose a novel self-detection paradigm that considers the comprehensive answer space beyond LLM-generated answers. It thoroughly compares the trustability of multiple candidate answers to mitigate the over-trust in LLM-generated incorrect answers. Building upon this paradigm, we introduce a two-step framework, which firstly instructs LLM to reflect and provide justifications for each candidate answer, and then aggregates the justifications for comprehensive target answer evaluation. This framework can be seamlessly integrated with existing approaches for superior self-detection. Extensive experiments on six datasets spanning three tasks demonstrate the effectiveness of the proposed framework.
6/5/2024