Self-supervised Adversarial Training of Monocular Depth Estimation against Physical-World Attacks
2406.05857
0
0

Abstract
Monocular Depth Estimation (MDE) plays a vital role in applications such as autonomous driving. However, various attacks target MDE models, with physical attacks posing significant threats to system security. Traditional adversarial training methods, which require ground-truth labels, are not directly applicable to MDE models that lack ground-truth depth. Some self-supervised model hardening techniques (e.g., contrastive learning) overlook the domain knowledge of MDE, resulting in suboptimal performance. In this work, we introduce a novel self-supervised adversarial training approach for MDE models, leveraging view synthesis without the need for ground-truth depth. We enhance adversarial robustness against real-world attacks by incorporating L_0-norm-bounded perturbation during training. We evaluate our method against supervised learning-based and contrastive learning-based approaches specifically designed for MDE. Our experiments with two representative MDE networks demonstrate improved robustness against various adversarial attacks, with minimal impact on benign performance.
Create account to get full access
Overview
- This paper presents a novel approach for making monocular depth estimation models more robust against adversarial attacks in the physical world.
- The key ideas are using self-supervised training and adversarial training to improve the model's performance and ability to withstand real-world disturbances.
- The authors demonstrate the effectiveness of their method through extensive experiments on various datasets and attack scenarios.
Plain English Explanation
Monocular depth estimation is the task of predicting the depth or distance of objects in a single 2D image. This is an important capability for applications like self-driving cars, robotics, and augmented reality. However, these depth estimation models can be vulnerable to adversarial attacks, where small, carefully crafted perturbations to the input image can cause the model to make incorrect depth predictions.
The researchers in this paper have developed a new training approach to make these depth estimation models more robust against such adversarial attacks in the real world. Their key insight is to leverage two powerful machine learning techniques - self-supervised learning and adversarial training.
Self-supervised learning allows the model to learn useful representations from the data itself, without the need for manual labeling. This helps the model capture the inherent structure and patterns in natural images, which makes it more generalizable.
Adversarial training is a technique where the model is intentionally exposed to adversarial examples during training. This forces the model to learn features that are more resilient to small perturbations, improving its robustness.
By combining these two approaches, the researchers were able to train depth estimation models that not only performed well on standard benchmarks, but were also much more resistant to physical-world attacks, like stickers or graffiti placed on objects. This is an important step towards making these computer vision systems more reliable and trustworthy in real-world applications.
Technical Explanation
The authors propose a self-supervised adversarial training framework for improving the robustness of monocular depth estimation models against physical-world attacks. Their key contributions are:
-
Self-supervised Depth Estimation: They use a self-supervised depth estimation approach, where the model learns to predict depth from unlabeled stereo image pairs, without requiring ground truth depth maps. This allows the model to learn rich visual representations from a large amount of unlabeled data.
-
Adversarial Training: To improve the model's robustness, the authors incorporate adversarial training. During training, they generate adversarial examples by applying small, carefully crafted perturbations to the input images. This forces the model to learn features that are more resilient to such disturbances.
-
Physical-world Attack Evaluation: The authors evaluate their model's performance under a variety of physical-world attack scenarios, such as applying stickers, graffiti, or other adversarial patches to objects. This is an important test of the model's real-world applicability.
-
Extensive Experiments: The proposed method is evaluated on multiple datasets, including indoor and outdoor scenes, and compared against state-of-the-art depth estimation and adversarial defense techniques. The results demonstrate the effectiveness of the self-supervised adversarial training approach.
The authors' work advances the field of self-supervised monocular depth estimation and adversarial robustness for computer vision systems. By making depth estimation models more resilient to physical-world attacks, this research brings us closer to deploying these technologies in safety-critical applications like autonomous vehicles and robotics.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed self-supervised adversarial training approach. However, there are a few potential limitations and areas for further research:
-
Generalization to Unseen Attacks: While the authors evaluate the model's performance under various physical-world attack scenarios, it's unclear how well it would generalize to completely novel, unseen types of attacks. Exploring the model's robustness to a wider range of disturbances could be an important next step.
-
Computational Efficiency: Adversarial training can be computationally expensive, as it requires generating and training on adversarial examples. The authors do not provide details on the computational cost of their approach, which could be a concern for real-time applications like autonomous navigation.
-
Potential Biases: As with any machine learning model, there is a risk of the depth estimation model learning biases present in the training data, which could lead to systematic errors or unfair predictions. Investigating and mitigating such biases would be an important direction for future research.
-
Applicability to Other Vision Tasks: While this paper focuses on monocular depth estimation, the self-supervised adversarial training approach could potentially be applicable to other computer vision tasks, such as object detection or semantic segmentation. Exploring the transferability of this technique could expand its impact.
Overall, this paper makes a significant contribution to improving the robustness of monocular depth estimation models, which is an important step towards the reliable deployment of these technologies in the real world.
Conclusion
This research presents a novel self-supervised adversarial training approach for making monocular depth estimation models more robust against physical-world attacks. By leveraging self-supervised learning and adversarial training, the authors were able to develop depth estimation models that not only performed well on standard benchmarks, but also demonstrated improved resilience to a variety of disturbances, such as stickers or graffiti applied to objects.
The paper's extensive experiments and analysis showcase the effectiveness of this approach, which represents an important advancement in the field of computer vision. By making depth estimation models more reliable and trustworthy, this research brings us closer to realizing the full potential of these technologies in safety-critical applications like autonomous vehicles and robotics.
While the paper identifies a few potential limitations and areas for further research, the overall work is a significant contribution to the ongoing efforts to make machine learning systems more robust and deployable in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
Enhanced Object Tracking by Self-Supervised Auxiliary Depth Estimation Learning
Zhenyu Wei, Yujie He, Zhanchuan Cai
0
0
RGB-D tracking significantly improves the accuracy of object tracking. However, its dependency on real depth inputs and the complexity involved in multi-modal fusion limit its applicability across various scenarios. The utilization of depth information in RGB-D tracking inspired us to propose a new method, named MDETrack, which trains a tracking network with an additional capability to understand the depth of scenes, through supervised or self-supervised auxiliary Monocular Depth Estimation learning. The outputs of MDETrack's unified feature extractor are fed to the side-by-side tracking head and auxiliary depth estimation head, respectively. The auxiliary module will be discarded in inference, thus keeping the same inference speed. We evaluated our models with various training strategies on multiple datasets, and the results show an improved tracking accuracy even without real depth. Through these findings we highlight the potential of depth estimation in enhancing object tracking performance.
5/24/2024
✨
Mind The Edge: Refining Depth Edges in Sparsely-Supervised Monocular Depth Estimation
Lior Talker, Aviad Cohen, Erez Yosef, Alexandra Dana, Michael Dinerstein
0
0
Monocular Depth Estimation (MDE) is a fundamental problem in computer vision with numerous applications. Recently, LIDAR-supervised methods have achieved remarkable per-pixel depth accuracy in outdoor scenes. However, significant errors are typically found in the proximity of depth discontinuities, i.e., depth edges, which often hinder the performance of depth-dependent applications that are sensitive to such inaccuracies, e.g., novel view synthesis and augmented reality. Since direct supervision for the location of depth edges is typically unavailable in sparse LIDAR-based scenes, encouraging the MDE model to produce correct depth edges is not straightforward. To the best of our knowledge this paper is the first attempt to address the depth edges issue for LIDAR-supervised scenes. In this work we propose to learn to detect the location of depth edges from densely-supervised synthetic data, and use it to generate supervision for the depth edges in the MDE training. To quantitatively evaluate our approach, and due to the lack of depth edges GT in LIDAR-based scenes, we manually annotated subsets of the KITTI and the DDAD datasets with depth edges ground truth. We demonstrate significant gains in the accuracy of the depth edges with comparable per-pixel depth accuracy on several challenging datasets. Code and datasets are available at url{https://github.com/liortalker/MindTheEdge}.
4/4/2024

Self-Supervised Monocular Depth Estimation in the Dark: Towards Data Distribution Compensation
Haolin Yang, Chaoqiang Zhao, Lu Sheng, Yang Tang
0
0
Nighttime self-supervised monocular depth estimation has received increasing attention in recent years. However, using night images for self-supervision is unreliable because the photometric consistency assumption is usually violated in the videos taken under complex lighting conditions. Even with domain adaptation or photometric loss repair, performance is still limited by the poor supervision of night images on trainable networks. In this paper, we propose a self-supervised nighttime monocular depth estimation method that does not use any night images during training. Our framework utilizes day images as a stable source for self-supervision and applies physical priors (e.g., wave optics, reflection model and read-shot noise model) to compensate for some key day-night differences. With day-to-night data distribution compensation, our framework can be trained in an efficient one-stage self-supervised manner. Though no nighttime images are considered during training, qualitative and quantitative results demonstrate that our method achieves SoTA depth estimating results on the challenging nuScenes-Night and RobotCar-Night compared with existing methods.
4/23/2024
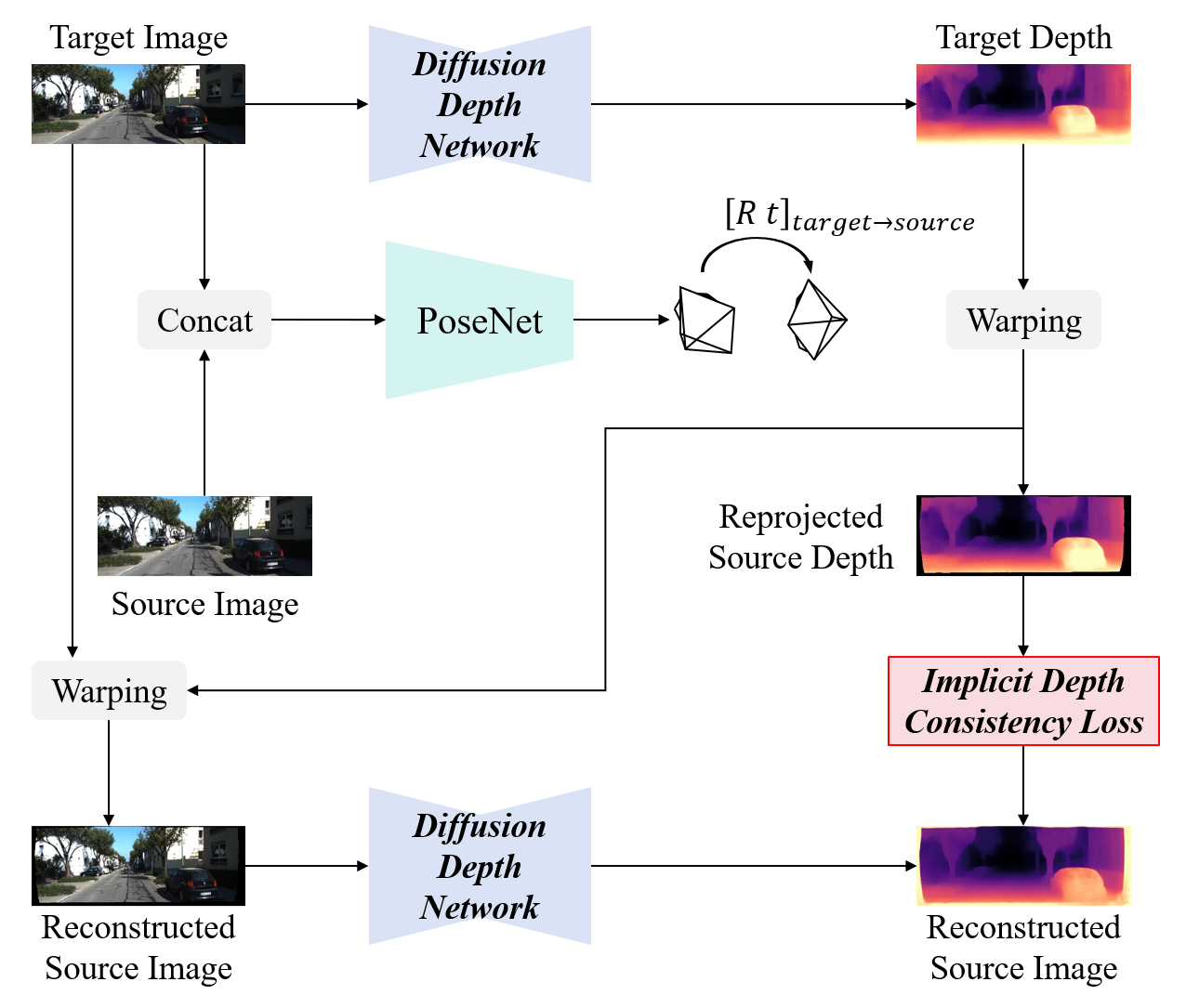
Unsupervised Monocular Depth Estimation Based on Hierarchical Feature-Guided Diffusion
Runze Liu, Dongchen Zhu, Guanghui Zhang, Yue Xu, Wenjun Shi, Xiaolin Zhang, Lei Wang, Jiamao Li
0
0
Unsupervised monocular depth estimation has received widespread attention because of its capability to train without ground truth. In real-world scenarios, the images may be blurry or noisy due to the influence of weather conditions and inherent limitations of the camera. Therefore, it is particularly important to develop a robust depth estimation model. Benefiting from the training strategies of generative networks, generative-based methods often exhibit enhanced robustness. In light of this, we employ a well-converging diffusion model among generative networks for unsupervised monocular depth estimation. Additionally, we propose a hierarchical feature-guided denoising module. This model significantly enriches the model's capacity for learning and interpreting depth distribution by fully leveraging image features to guide the denoising process. Furthermore, we explore the implicit depth within reprojection and design an implicit depth consistency loss. This loss function serves to enhance the performance of the model and ensure the scale consistency of depth within a video sequence. We conduct experiments on the KITTI, Make3D, and our self-collected SIMIT datasets. The results indicate that our approach stands out among generative-based models, while also showcasing remarkable robustness.
6/17/2024