Self-Supervised Audio-Visual Soundscape Stylization

0

Sign in to get full access
Overview
- This paper proposes a self-supervised method for audio-visual soundscape stylization.
- The approach learns to transform audio and visual inputs into a shared representation, which is then used to generate a stylized soundscape.
- The method is evaluated on various datasets and shown to outperform existing techniques in generating realistic and expressive audio-visual scenes.
Plain English Explanation
The researchers have developed a new way to create stylized soundscapes by combining audio and visual information. Their self-supervised method learns to take in both audio and video data, and then use that information to generate a new, enhanced audio experience.
The key idea is to find a shared representation that can capture the relationship between the audio and visual inputs. This shared representation then becomes the basis for generating a final soundscape that has a distinct style or character, beyond just a straightforward recording.
For example, the system might take a video of a bustling city street and the ambient sounds of that environment, and then use that information to produce a more cinematic, evocative soundscape - one that feels more immersive and artistically stylized. This could be useful for things like film, video games, or virtual environments, where you want to create an engaging, atmospheric audio experience.
Technical Explanation
The paper introduces a self-supervised audio-visual soundscape stylization approach. The key components are:
-
Audio-Visual Encoder: The system takes in both audio and visual inputs and learns a shared representation that captures the relationship between them.
-
Soundscape Generator: This module takes the shared representation and generates a new, stylized soundscape. This allows the system to create expressive, non-literal audio outputs.
-
Self-Supervision: The model is trained in a self-supervised manner, without relying on labeled data. It learns by predicting the correct soundscape for a given video.
The researchers evaluate their approach on several audio-visual datasets and show that it outperforms previous methods in generating realistic and compelling soundscapes. The self-supervised training allows the model to learn powerful representations without the need for extensive manual labeling.
Critical Analysis
The paper presents a novel and promising approach to audio-visual stylization. However, a few potential limitations are worth noting:
-
The evaluation is primarily focused on perceptual quality, without deeper analysis of the learned representations. Further investigation into the model's understanding of audio-visual relationships could provide additional insights.
-
The method is demonstrated on relatively constrained datasets. Scaling to more diverse, real-world audio-visual data may present additional challenges.
-
While the self-supervised training is a strength, the paper does not explore the model's ability to generalize to unseen audio-visual inputs or handle out-of-distribution samples.
Addressing these areas could strengthen the research and further explore the potential of self-supervised audio-visual stylization techniques.
Conclusion
This paper introduces a novel self-supervised approach for generating stylized soundscapes from audio-visual inputs. By learning a shared representation that captures the relationship between audio and visual data, the system is able to create expressive, non-literal audio outputs that enhance the immersive experience of multimedia applications.
The promising results demonstrate the potential of this technique to advance the field of audio-visual generation and processing. Further research into the model's generalization capabilities and its application to more diverse real-world scenarios could unlock even greater possibilities for this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-Supervised Audio-Visual Soundscape Stylization
Tingle Li, Renhao Wang, Po-Yao Huang, Andrew Owens, Gopala Anumanchipalli
Speech sounds convey a great deal of information about the scenes, resulting in a variety of effects ranging from reverberation to additional ambient sounds. In this paper, we manipulate input speech to sound as though it was recorded within a different scene, given an audio-visual conditional example recorded from that scene. Our model learns through self-supervision, taking advantage of the fact that natural video contains recurring sound events and textures. We extract an audio clip from a video and apply speech enhancement. We then train a latent diffusion model to recover the original speech, using another audio-visual clip taken from elsewhere in the video as a conditional hint. Through this process, the model learns to transfer the conditional example's sound properties to the input speech. We show that our model can be successfully trained using unlabeled, in-the-wild videos, and that an additional visual signal can improve its sound prediction abilities. Please see our project webpage for video results: https://tinglok.netlify.app/files/avsoundscape/
Read more9/24/2024

0
Improving Audio Generation with Visual Enhanced Caption
Yi Yuan, Dongya Jia, Xiaobin Zhuang, Yuanzhe Chen, Zhengxi Liu, Zhuo Chen, Yuping Wang, Yuxuan Wang, Xubo Liu, Xiyuan Kang, Mark D. Plumbley, Wenwu Wang
Generative models have shown significant achievements in audio generation tasks. However, existing models struggle with complex and detailed prompts, leading to potential performance degradation. We hypothesize that this problem stems from the simplicity and scarcity of the training data. This work aims to create a large-scale audio dataset with rich captions for improving audio generation models. We first develop an automated pipeline to generate detailed captions by transforming predicted visual captions, audio captions, and tagging labels into comprehensive descriptions using a Large Language Model (LLM). The resulting dataset, Sound-VECaps, comprises 1.66M high-quality audio-caption pairs with enriched details including audio event orders, occurred places and environment information. We then demonstrate that training the text-to-audio generation models with Sound-VECaps significantly improves the performance on complex prompts. Furthermore, we conduct ablation studies of the models on several downstream audio-language tasks, showing the potential of Sound-VECaps in advancing audio-text representation learning. Our dataset and models are available online.
Read more8/16/2024

0
Action2Sound: Ambient-Aware Generation of Action Sounds from Egocentric Videos
Changan Chen, Puyuan Peng, Ami Baid, Zihui Xue, Wei-Ning Hsu, David Harwath, Kristen Grauman
Generating realistic audio for human actions is important for many applications, such as creating sound effects for films or virtual reality games. Existing approaches implicitly assume total correspondence between the video and audio during training, yet many sounds happen off-screen and have weak to no correspondence with the visuals -- resulting in uncontrolled ambient sounds or hallucinations at test time. We propose a novel ambient-aware audio generation model, AV-LDM. We devise a novel audio-conditioning mechanism to learn to disentangle foreground action sounds from the ambient background sounds in in-the-wild training videos. Given a novel silent video, our model uses retrieval-augmented generation to create audio that matches the visual content both semantically and temporally. We train and evaluate our model on two in-the-wild egocentric video datasets, Ego4D and EPIC-KITCHENS, and we introduce Ego4D-Sounds -- 1.2M curated clips with action-audio correspondence. Our model outperforms an array of existing methods, allows controllable generation of the ambient sound, and even shows promise for generalizing to computer graphics game clips. Overall, our approach is the first to focus video-to-audio generation faithfully on the observed visual content despite training from uncurated clips with natural background sounds.
Read more7/26/2024
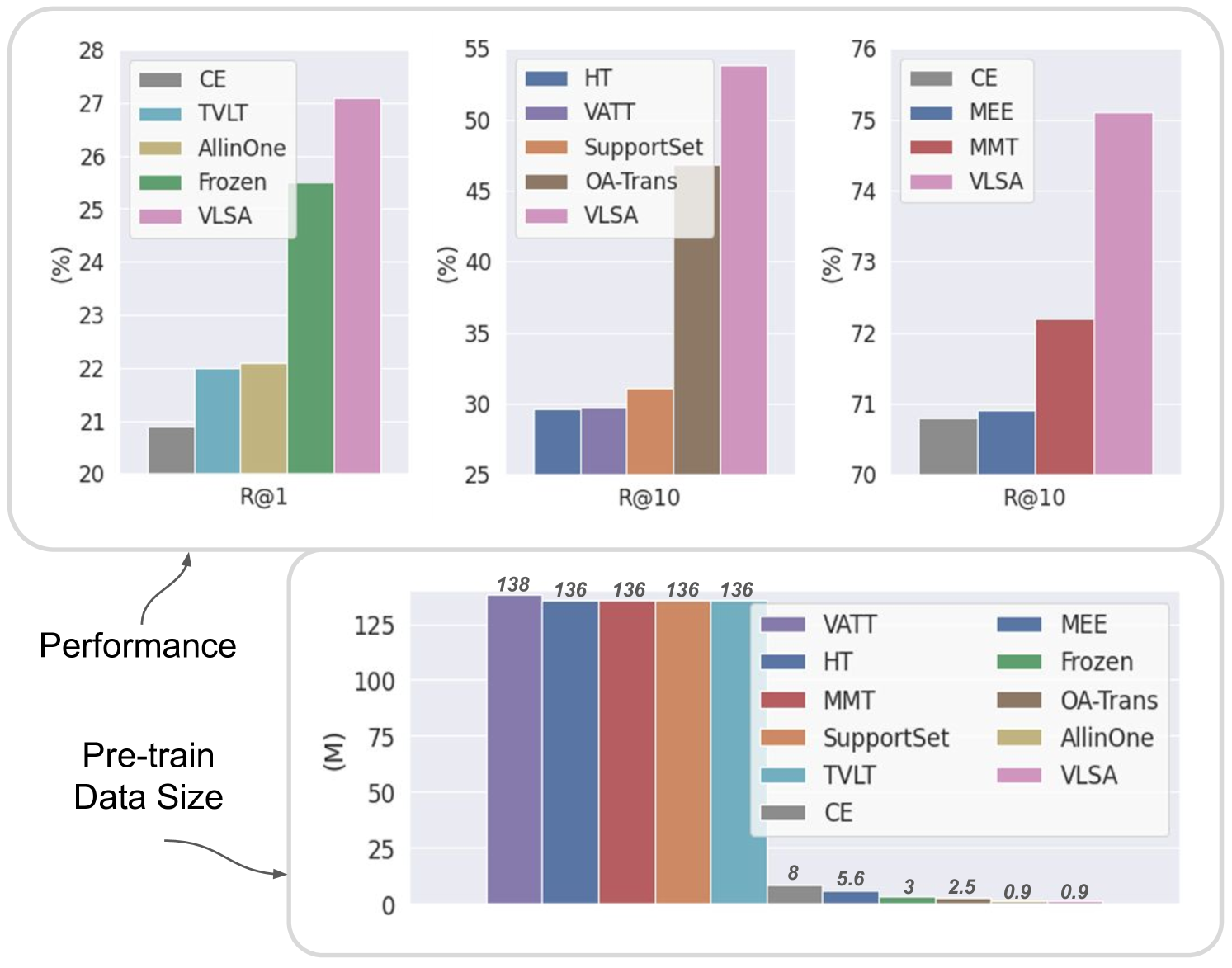
0
Unified Video-Language Pre-training with Synchronized Audio
Shentong Mo, Haofan Wang, Huaxia Li, Xu Tang
Video-language pre-training is a typical and challenging problem that aims at learning visual and textual representations from large-scale data in a self-supervised way. Existing pre-training approaches either captured the correspondence of image-text pairs or utilized temporal ordering of frames. However, they do not explicitly explore the natural synchronization between audio and the other two modalities. In this work, we propose an enhanced framework for Video-Language pre-training with Synchronized Audio, termed as VLSA, that can learn tri-modal representations in a unified self-supervised transformer. Specifically, our VLSA jointly aggregates embeddings of local patches and global tokens for video, text, and audio. Furthermore, we utilize local-patch masked modeling to learn modality-aware features, and leverage global audio matching to capture audio-guided features for video and text. We conduct extensive experiments on retrieval across text, video, and audio. Our simple model pre-trained on only 0.9M data achieves improving results against state-of-the-art baselines. In addition, qualitative visualizations vividly showcase the superiority of our VLSA in learning discriminative visual-textual representations.
Read more5/14/2024