Action2Sound: Ambient-Aware Generation of Action Sounds from Egocentric Videos
2406.09272
0
0

Abstract
Generating realistic audio for human interactions is important for many applications, such as creating sound effects for films or virtual reality games. Existing approaches implicitly assume total correspondence between the video and audio during training, yet many sounds happen off-screen and have weak to no correspondence with the visuals -- resulting in uncontrolled ambient sounds or hallucinations at test time. We propose a novel ambient-aware audio generation model, AV-LDM. We devise a novel audio-conditioning mechanism to learn to disentangle foreground action sounds from the ambient background sounds in in-the-wild training videos. Given a novel silent video, our model uses retrieval-augmented generation to create audio that matches the visual content both semantically and temporally. We train and evaluate our model on two in-the-wild egocentric video datasets Ego4D and EPIC-KITCHENS. Our model outperforms an array of existing methods, allows controllable generation of the ambient sound, and even shows promise for generalizing to computer graphics game clips. Overall, our work is the first to focus video-to-audio generation faithfully on the observed visual content despite training from uncurated clips with natural background sounds.
Create account to get full access
Overview
- This paper introduces a novel method called "Action2Sound" for generating ambient-aware action sounds from egocentric (first-person) videos.
- The system leverages the surrounding environment and contextual information in the video to produce more realistic and immersive audio that matches the visual actions.
- Key innovations include a multi-modal neural network architecture and a dataset of egocentric videos paired with corresponding action sounds.
Plain English Explanation
The researchers have developed a way to automatically generate the sounds that should accompany the actions seen in a first-person video. For example, if the video shows someone opening a door, the system would produce the realistic sound of the door creaking and closing.
The key innovation is that the system takes into account the broader environment and context of the video, not just the specific action. So the door sound would also reflect the acoustics of the room or building the person is in. This makes the generated audio much more natural and immersive, matching the visual scene.
To achieve this, the researchers trained a machine learning model on a large dataset of first-person videos paired with the correct corresponding sounds. The model learns to associate visual cues and environmental factors with the appropriate audio. When shown a new video, it can then predict what sounds should be generated to seamlessly complement the actions.
This technology has exciting applications in areas like virtual reality, video games, and filmmaking, where adding high-quality ambient sounds can significantly enhance the user experience and sense of realism. It also has potential for accessibility, by allowing those with hearing impairments to better experience audio-visual content.
Technical Explanation
The paper introduces the "Action2Sound" method for generating ambient-aware action sounds from egocentric videos. The key innovation is its ability to leverage the surrounding environment and contextual information in the video to produce more realistic and immersive audio that matches the visual actions.
The authors propose a multi-modal neural network architecture that takes in egocentric video frames and predicts the corresponding action sounds. This goes beyond previous work on video-to-audio generation by incorporating ambient cues from the environment, such as the acoustic properties of the room or building.
To train the model, the researchers created a new dataset of egocentric videos paired with their corresponding action sounds. This allows the network to learn the complex relationships between the visual inputs, environmental context, and appropriate audio outputs.
Experiments show that the Action2Sound method significantly outperforms baseline video-to-audio generation approaches in terms of audio quality and realism. The generated sounds are more spatially coherent and synchronized with the visual actions, thanks to the model's ability to reason about the ambient context.
Critical Analysis
The Action2Sound paper presents a promising approach to generating ambient-aware action sounds from first-person videos. However, there are a few potential limitations and areas for further research:
-
The dataset used for training is relatively small, so the model's performance may be constrained by the diversity of environments and actions represented. Expanding the dataset could lead to more robust and generalized sound generation.
-
The paper does not explore the model's ability to handle complex, multi-agent scenarios or videos with significant camera motion. These real-world conditions may introduce additional challenges that require further investigation.
-
While the authors demonstrate the benefits of incorporating environmental context, the exact mechanisms by which the model learns and utilizes this information are not fully explained. A deeper analysis of the model's inner workings could provide valuable insights.
-
The paper focuses on evaluating the generated audio quality, but does not assess the impact of the ambient-aware sounds on the overall user experience, such as in virtual reality applications. Conducting user studies could help validate the practical value of the technology.
Overall, the Action2Sound method represents an important step forward in semantically consistent video-to-audio generation. With further research and refinement, this technology could significantly enhance the realism and immersion of audio-visual experiences across a wide range of applications.
Conclusion
The Action2Sound paper presents a novel approach for generating ambient-aware action sounds from first-person videos. By leveraging the surrounding environment and contextual information, the system can produce more realistic and synchronized audio that enhances the overall user experience.
The key innovations include a multi-modal neural network architecture and a dataset of egocentric videos paired with corresponding action sounds. Experiments show that Action2Sound outperforms baseline video-to-audio generation methods, demonstrating the benefits of incorporating ambient cues.
This technology has exciting applications in virtual reality, video games, and filmmaking, where adding high-quality ambient sounds can significantly improve realism and immersion. It also has potential for accessibility, by allowing those with hearing impairments to better experience audio-visual content.
While the paper presents a promising approach, there are opportunities for further research to address limitations and explore the broader practical impacts of ambient-aware sound generation. Nonetheless, the Action2Sound method represents an important step forward in the field of audio-visual learning and understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SoundingActions: Learning How Actions Sound from Narrated Egocentric Videos
Changan Chen, Kumar Ashutosh, Rohit Girdhar, David Harwath, Kristen Grauman
0
0
We propose a novel self-supervised embedding to learn how actions sound from narrated in-the-wild egocentric videos. Whereas existing methods rely on curated data with known audio-visual correspondence, our multimodal contrastive-consensus coding (MC3) embedding reinforces the associations between audio, language, and vision when all modality pairs agree, while diminishing those associations when any one pair does not. We show our approach can successfully discover how the long tail of human actions sound from egocentric video, outperforming an array of recent multimodal embedding techniques on two datasets (Ego4D and EPIC-Sounds) and multiple cross-modal tasks.
4/9/2024
🤯
Synthesizing Audio from Silent Video using Sequence to Sequence Modeling
Hugo Garrido-Lestache Belinchon, Helina Mulugeta, Adam Haile
0
0
Generating audio from a video's visual context has multiple practical applications in improving how we interact with audio-visual media - for example, enhancing CCTV footage analysis, restoring historical videos (e.g., silent movies), and improving video generation models. We propose a novel method to generate audio from video using a sequence-to-sequence model, improving on prior work that used CNNs and WaveNet and faced sound diversity and generalization challenges. Our approach employs a 3D Vector Quantized Variational Autoencoder (VQ-VAE) to capture the video's spatial and temporal structures, decoding with a custom audio decoder for a broader range of sounds. Trained on the Youtube8M dataset segment, focusing on specific domains, our model aims to enhance applications like CCTV footage analysis, silent movie restoration, and video generation models.
4/30/2024
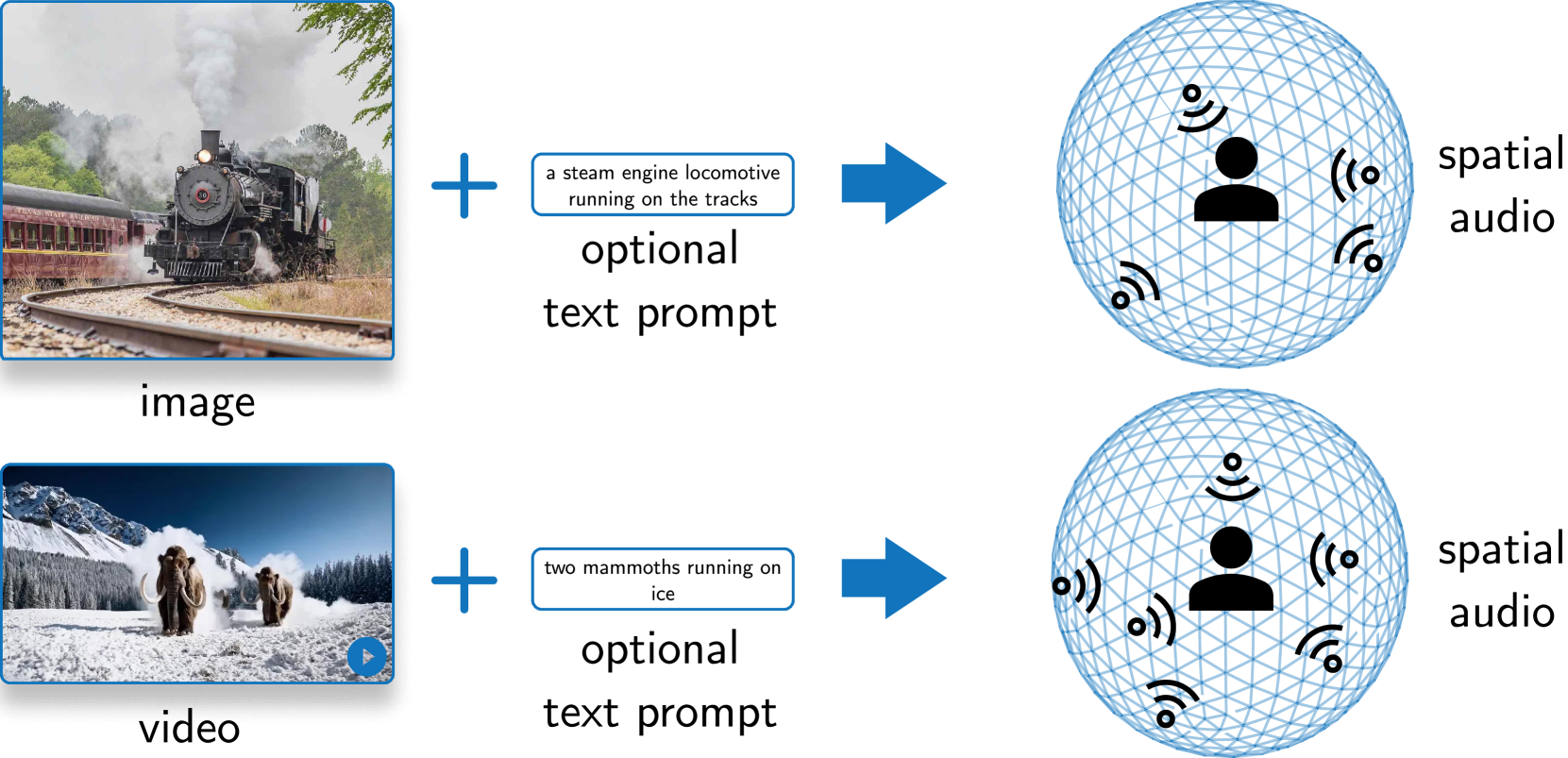
SEE-2-SOUND: Zero-Shot Spatial Environment-to-Spatial Sound
Rishit Dagli, Shivesh Prakash, Robert Wu, Houman Khosravani
0
0
Generating combined visual and auditory sensory experiences is critical for the consumption of immersive content. Recent advances in neural generative models have enabled the creation of high-resolution content across multiple modalities such as images, text, speech, and videos. Despite these successes, there remains a significant gap in the generation of high-quality spatial audio that complements generated visual content. Furthermore, current audio generation models excel in either generating natural audio or speech or music but fall short in integrating spatial audio cues necessary for immersive experiences. In this work, we introduce SEE-2-SOUND, a zero-shot approach that decomposes the task into (1) identifying visual regions of interest; (2) locating these elements in 3D space; (3) generating mono-audio for each; and (4) integrating them into spatial audio. Using our framework, we demonstrate compelling results for generating spatial audio for high-quality videos, images, and dynamic images from the internet, as well as media generated by learned approaches.
6/12/2024
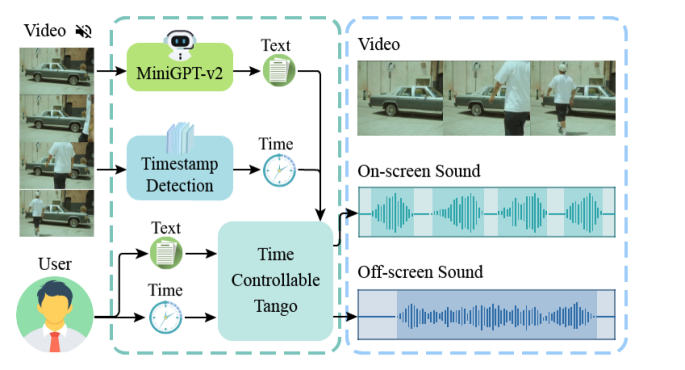
SonicVisionLM: Playing Sound with Vision Language Models
Zhifeng Xie, Shengye Yu, Qile He, Mengtian Li
0
0
There has been a growing interest in the task of generating sound for silent videos, primarily because of its practicality in streamlining video post-production. However, existing methods for video-sound generation attempt to directly create sound from visual representations, which can be challenging due to the difficulty of aligning visual representations with audio representations. In this paper, we present SonicVisionLM, a novel framework aimed at generating a wide range of sound effects by leveraging vision-language models(VLMs). Instead of generating audio directly from video, we use the capabilities of powerful VLMs. When provided with a silent video, our approach first identifies events within the video using a VLM to suggest possible sounds that match the video content. This shift in approach transforms the challenging task of aligning image and audio into more well-studied sub-problems of aligning image-to-text and text-to-audio through the popular diffusion models. To improve the quality of audio recommendations with LLMs, we have collected an extensive dataset that maps text descriptions to specific sound effects and developed a time-controlled audio adapter. Our approach surpasses current state-of-the-art methods for converting video to audio, enhancing synchronization with the visuals, and improving alignment between audio and video components. Project page: https://yusiissy.github.io/SonicVisionLM.github.io/
4/4/2024