Self-Supervised Disentangled Representation Learning for Robust Target Speech Extraction

0

Sign in to get full access
Introduction
This research paper proposes a self-supervised disentangled representation learning approach for robust target speech extraction. The key idea is to learn a speech representation that separates the target speaker's voice from background noise and other interfering speakers. This can enable more accurate extraction of the target speech signal, which has important applications in areas like speech enhancement, speaker diarization, and meeting transcription.
Related Work
Prior work on speech representation learning has explored techniques like adversarial training and end-to-end models to disentangle speech factors like speaker identity, accent, and environment. However, these methods may not generalize well to unseen noise conditions. The current paper aims to address this limitation through a self-supervised approach that can learn robust speech representations without relying on extensive labeled data.
Methodology
Notations and Problem Formulation
The paper defines the problem of target speech extraction as follows: Given a mixed audio signal containing the target speaker's voice along with background noise and other interfering speakers, the goal is to estimate the clean target speech signal. The mixed audio is represented as a spectrogram, and the model aims to learn a disentangled representation that separates the target speaker's voice from other factors.
Self-Supervised Disentangled Representation Learning
The key components of the proposed approach are:
- Audio Reconstruction: The model is trained to reconstruct the original mixed audio signal from its learned representation, encouraging the representation to encode all necessary information.
- Disentanglement: The model is also trained to predict various attributes of the audio, such as speaker identity, background noise, and interfering speakers. This forces the representation to isolate these factors, leading to a disentangled representation.
- Adversarial Training: An adversarial component is incorporated to further encourage the disentanglement of the target speaker's voice from other factors.
The training process optimizes a combination of these objectives to learn a robust speech representation that can be used for accurate target speech extraction.
Technical Explanation
The proposed model consists of an encoder-decoder architecture, where the encoder learns the disentangled representation, and the decoder reconstructs the original mixed audio. The encoder has branching sub-networks that predict the various attributes (speaker identity, noise, etc.) to encourage disentanglement.
During training, the mixed audio spectrogram is fed into the encoder, which produces the disentangled representation. This representation is then used by the decoder to reconstruct the original audio, and the attribute prediction sub-networks to predict the various factors. The model is trained end-to-end using a combination of reconstruction, disentanglement, and adversarial losses.
The learned representation can be used for target speech extraction by inputting the mixed audio into the encoder and selecting the target speaker's component from the disentangled representation.
Critical Analysis
The paper presents a well-designed self-supervised approach for learning robust speech representations. By incorporating disentanglement and adversarial training, the model is able to generalize to unseen noise conditions, which is a significant advantage over prior work.
However, the paper does not address potential limitations, such as the computational complexity of the model or its performance on real-world, highly complex audio mixtures. Additionally, the evaluation is conducted on relatively simple datasets, and further testing on more challenging scenarios would be valuable.
Conclusion
This research introduces a self-supervised disentangled representation learning framework for robust target speech extraction. By learning to separate the target speaker's voice from other factors, the model can effectively isolate the target speech signal, even in the presence of background noise and interfering speakers. This has important implications for a wide range of speech processing applications that require accurate target speech extraction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-Supervised Disentangled Representation Learning for Robust Target Speech Extraction
Zhaoxi Mu, Xinyu Yang, Sining Sun, Qing Yang
Speech signals are inherently complex as they encompass both global acoustic characteristics and local semantic information. However, in the task of target speech extraction, certain elements of global and local semantic information in the reference speech, which are irrelevant to speaker identity, can lead to speaker confusion within the speech extraction network. To overcome this challenge, we propose a self-supervised disentangled representation learning method. Our approach tackles this issue through a two-phase process, utilizing a reference speech encoding network and a global information disentanglement network to gradually disentangle the speaker identity information from other irrelevant factors. We exclusively employ the disentangled speaker identity information to guide the speech extraction network. Moreover, we introduce the adaptive modulation Transformer to ensure that the acoustic representation of the mixed signal remains undisturbed by the speaker embeddings. This component incorporates speaker embeddings as conditional information, facilitating natural and efficient guidance for the speech extraction network. Experimental results substantiate the effectiveness of our meticulously crafted approach, showcasing a substantial reduction in the likelihood of speaker confusion.
Read more8/27/2024
0
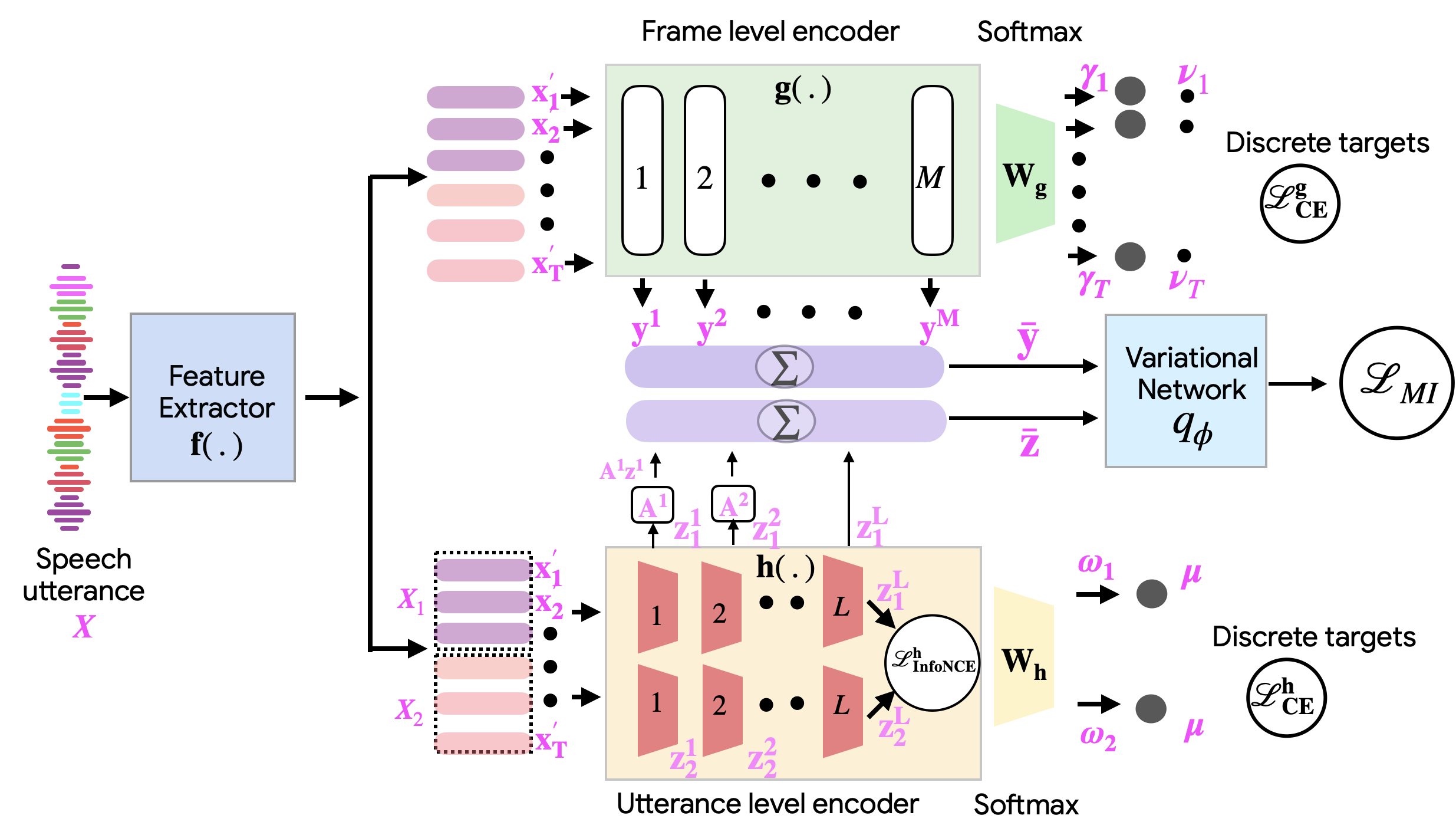
Towards the Next Frontier in Speech Representation Learning Using Disentanglement
Varun Krishna, Sriram Ganapathy
The popular frameworks for self-supervised learning of speech representations have largely focused on frame-level masked prediction of speech regions. While this has shown promising downstream task performance for speech recognition and related tasks, this has largely ignored factors of speech that are encoded at coarser level, like characteristics of the speaker or channel that remain consistent through-out a speech utterance. In this work, we propose a framework for Learning Disentangled Self Supervised (termed as Learn2Diss) representations of speech, which consists of frame-level and an utterance-level encoder modules. The two encoders are initially learned independently, where the frame-level model is largely inspired by existing self supervision techniques, thereby learning pseudo-phonemic representations, while the utterance-level encoder is inspired by constrastive learning of pooled embeddings, thereby learning pseudo-speaker representations. The joint learning of these two modules consists of disentangling the two encoders using a mutual information based criterion. With several downstream evaluation experiments, we show that the proposed Learn2Diss achieves state-of-the-art results on a variety of tasks, with the frame-level encoder representations improving semantic tasks, while the utterance-level representations improve non-semantic tasks.
Read more7/4/2024
0
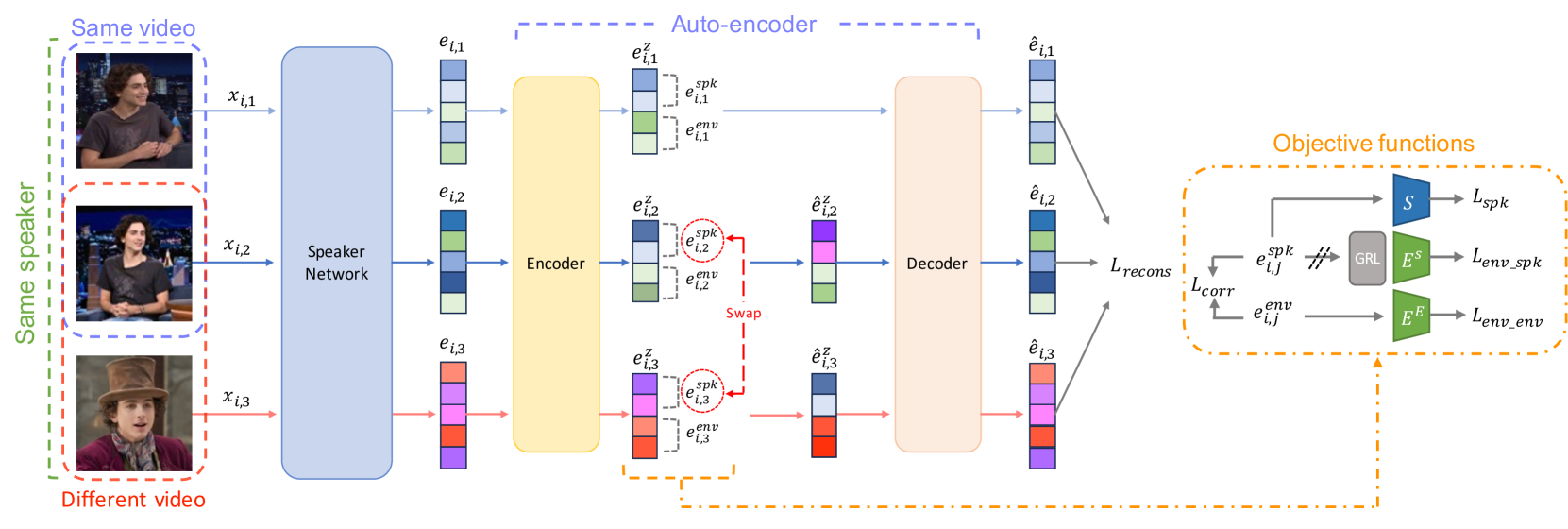
Disentangled Representation Learning for Environment-agnostic Speaker Recognition
KiHyun Nam, Hee-Soo Heo, Jee-weon Jung, Joon Son Chung
This work presents a framework based on feature disentanglement to learn speaker embeddings that are robust to environmental variations. Our framework utilises an auto-encoder as a disentangler, dividing the input speaker embedding into components related to the speaker and other residual information. We employ a group of objective functions to ensure that the auto-encoder's code representation - used as the refined embedding - condenses only the speaker characteristics. We show the versatility of our framework through its compatibility with any existing speaker embedding extractor, requiring no structural modifications or adaptations for integration. We validate the effectiveness of our framework by incorporating it into two popularly used embedding extractors and conducting experiments across various benchmarks. The results show a performance improvement of up to 16%. We release our code for this work to be available https://github.com/kaistmm/voxceleb-disentangler
Read more6/21/2024

0
A Joint Noise Disentanglement and Adversarial Training Framework for Robust Speaker Verification
Xujiang Xing, Mingxing Xu, Thomas Fang Zheng
Automatic Speaker Verification (ASV) suffers from performance degradation in noisy conditions. To address this issue, we propose a novel adversarial learning framework that incorporates noise-disentanglement to establish a noise-independent speaker invariant embedding space. Specifically, the disentanglement module includes two encoders for separating speaker related and irrelevant information, respectively. The reconstruction module serves as a regularization term to constrain the noise. A feature-robust loss is also used to supervise the speaker encoder to learn noise-independent speaker embeddings without losing speaker information. In addition, adversarial training is introduced to discourage the speaker encoder from encoding acoustic condition information for achieving a speaker-invariant embedding space. Experiments on VoxCeleb1 indicate that the proposed method improves the performance of the speaker verification system under both clean and noisy conditions.
Read more8/23/2024