A Joint Noise Disentanglement and Adversarial Training Framework for Robust Speaker Verification

0

Sign in to get full access
Overview
- This paper presents a joint noise disentanglement and adversarial training framework for robust speaker verification.
- The proposed approach aims to improve the performance of speaker verification systems in the presence of various noise and distortion factors.
- The key ideas include disentangling the noise and speaker representation, and using adversarial training to enhance the robustness of the speaker verification model.
Plain English Explanation
The paper describes a new way to make speaker verification systems more reliable, even when the audio recordings have background noise or other distortions. <a href="https://aimodels.fyi/papers/arxiv/disentangled-representation-learning-environment-agnostic-speaker-recognition">Speaker verification</a> is the process of confirming a person's identity based on their voice.
The main innovation is a two-part approach:
-
Noise Disentanglement: The system learns to separate the speaker's voice from the background noise in the audio recording. This allows it to focus on the essential voice characteristics for verification, while ignoring irrelevant noise factors.
-
Adversarial Training: The system is trained to be robust against a wide range of potential noise and distortions. This is done through an "adversarial" training process, where the system is intentionally exposed to challenging noise conditions during training, forcing it to learn more generalizable representations.
By combining these two techniques, the paper shows the speaker verification system can maintain high accuracy even when tested on noisy or distorted audio, outperforming previous approaches. This could make speaker verification more reliable for real-world applications like voice-based authentication or transcription.
Technical Explanation
The paper proposes a <a href="https://aimodels.fyi/papers/arxiv/improving-adversarial-robustness-speaker-verification-by-self">joint noise disentanglement and adversarial training framework</a> for robust speaker verification.
The key components are:
-
Noise Disentanglement Module: This module learns to extract the speaker representation while disentangling it from noise factors in the input audio. It uses a multi-task learning approach, with one branch predicting the speaker identity and another branch predicting the noise characteristics.
-
Adversarial Training: The speaker verification model is trained using adversarial loss, where an adversary tries to fool the model by generating corrupted audio samples. This forces the model to learn representations that are more robust to various noise and distortion factors.
-
Speaker Verification Model: The final speaker verification model combines the noise-disentangled speaker representation with the adversarially-trained classifier to achieve improved performance on noisy test samples.
The paper evaluates the proposed framework on standard speaker verification benchmarks with various noise conditions. The results show that the joint noise disentanglement and adversarial training approach outperforms previous state-of-the-art methods, demonstrating the effectiveness of the proposed techniques.
Critical Analysis
The paper provides a compelling approach to improving the robustness of speaker verification systems, which is an important practical challenge. The key strengths are:
- The noise disentanglement module allows the system to focus on the essential speaker characteristics, rather than getting distracted by irrelevant background noise.
- The adversarial training strategy exposes the model to a diverse range of noise conditions, forcing it to learn more generalizable representations.
- The combination of these two techniques leads to significant performance gains over prior work, as shown by the experimental results.
However, some potential limitations and areas for further research include:
- The paper only evaluates the approach on standard benchmarks with simulated noise conditions. It would be valuable to test the system on more diverse real-world data to understand its practical limitations.
- The noise disentanglement module assumes the noise factors can be easily separated from the speaker representation. In more complex real-world scenarios, the noise characteristics may be more entangled with the speaker identity.
- The adversarial training process can be computationally expensive and unstable. Exploring more efficient or stable adversarial training strategies could be an area for future work.
Overall, the joint noise disentanglement and adversarial training framework represents a promising direction for building more robust and reliable speaker verification systems. Further research and real-world validation could help refine and expand upon these techniques.
Conclusion
This paper introduces a novel approach to improving the robustness of speaker verification systems by jointly disentangling noise factors from speaker representations and using adversarial training techniques. The experimental results demonstrate significant performance gains over previous methods, particularly in the presence of various noise and distortion factors.
The key innovations - noise disentanglement and adversarial training - provide a compelling way to make speaker verification systems more reliable and practical for real-world applications like voice-based authentication and transcription. While there are still some limitations and areas for further research, this work represents an important step forward in the development of <a href="https://aimodels.fyi/papers/arxiv/towards-next-frontier-speech-representation-learning-using">robust speech recognition and speaker modeling</a> systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Joint Noise Disentanglement and Adversarial Training Framework for Robust Speaker Verification
Xujiang Xing, Mingxing Xu, Thomas Fang Zheng
Automatic Speaker Verification (ASV) suffers from performance degradation in noisy conditions. To address this issue, we propose a novel adversarial learning framework that incorporates noise-disentanglement to establish a noise-independent speaker invariant embedding space. Specifically, the disentanglement module includes two encoders for separating speaker related and irrelevant information, respectively. The reconstruction module serves as a regularization term to constrain the noise. A feature-robust loss is also used to supervise the speaker encoder to learn noise-independent speaker embeddings without losing speaker information. In addition, adversarial training is introduced to discourage the speaker encoder from encoding acoustic condition information for achieving a speaker-invariant embedding space. Experiments on VoxCeleb1 indicate that the proposed method improves the performance of the speaker verification system under both clean and noisy conditions.
Read more8/23/2024
0
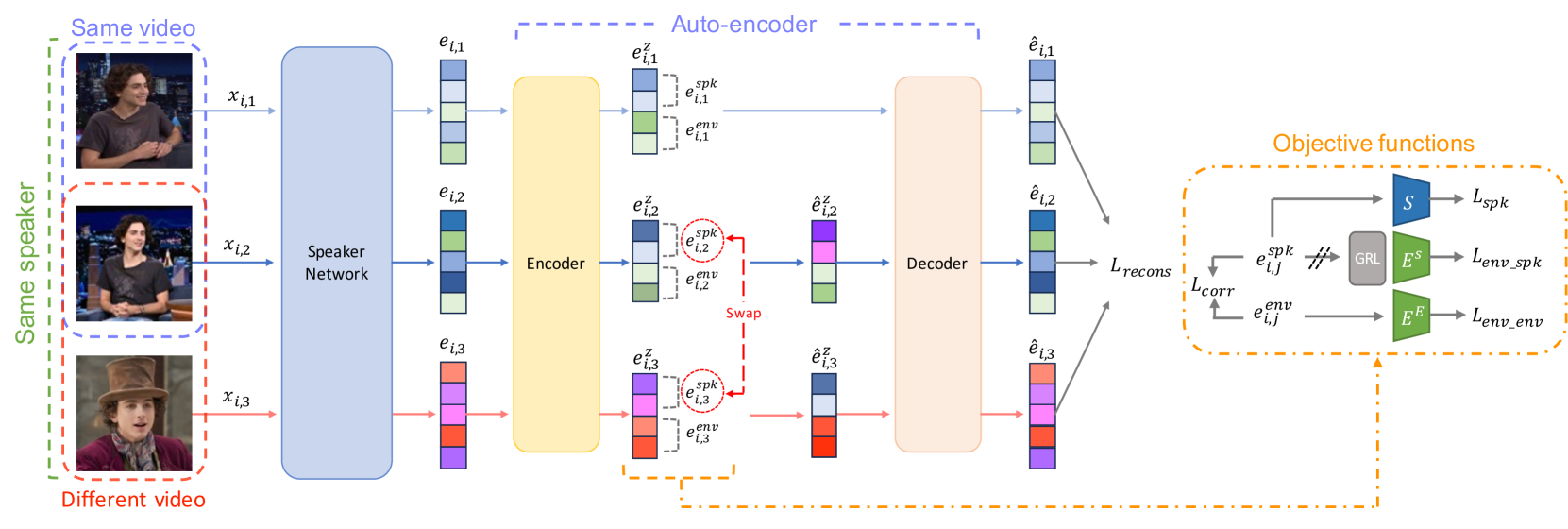
Disentangled Representation Learning for Environment-agnostic Speaker Recognition
KiHyun Nam, Hee-Soo Heo, Jee-weon Jung, Joon Son Chung
This work presents a framework based on feature disentanglement to learn speaker embeddings that are robust to environmental variations. Our framework utilises an auto-encoder as a disentangler, dividing the input speaker embedding into components related to the speaker and other residual information. We employ a group of objective functions to ensure that the auto-encoder's code representation - used as the refined embedding - condenses only the speaker characteristics. We show the versatility of our framework through its compatibility with any existing speaker embedding extractor, requiring no structural modifications or adaptations for integration. We validate the effectiveness of our framework by incorporating it into two popularly used embedding extractors and conducting experiments across various benchmarks. The results show a performance improvement of up to 16%. We release our code for this work to be available https://github.com/kaistmm/voxceleb-disentangler
Read more6/21/2024
🐍
0
Improving the Adversarial Robustness for Speaker Verification by Self-Supervised Learning
Haibin Wu, Xu Li, Andy T. Liu, Zhiyong Wu, Helen Meng, Hung-yi Lee
Previous works have shown that automatic speaker verification (ASV) is seriously vulnerable to malicious spoofing attacks, such as replay, synthetic speech, and recently emerged adversarial attacks. Great efforts have been dedicated to defending ASV against replay and synthetic speech; however, only a few approaches have been explored to deal with adversarial attacks. All the existing approaches to tackle adversarial attacks for ASV require the knowledge for adversarial samples generation, but it is impractical for defenders to know the exact attack algorithms that are applied by the in-the-wild attackers. This work is among the first to perform adversarial defense for ASV without knowing the specific attack algorithms. Inspired by self-supervised learning models (SSLMs) that possess the merits of alleviating the superficial noise in the inputs and reconstructing clean samples from the interrupted ones, this work regards adversarial perturbations as one kind of noise and conducts adversarial defense for ASV by SSLMs. Specifically, we propose to perform adversarial defense from two perspectives: 1) adversarial perturbation purification and 2) adversarial perturbation detection. Experimental results show that our detection module effectively shields the ASV by detecting adversarial samples with an accuracy of around 80%. Moreover, since there is no common metric for evaluating the adversarial defense performance for ASV, this work also formalizes evaluation metrics for adversarial defense considering both purification and detection based approaches into account. We sincerely encourage future works to benchmark their approaches based on the proposed evaluation framework.
Read more6/6/2024

0
Self-Supervised Disentangled Representation Learning for Robust Target Speech Extraction
Zhaoxi Mu, Xinyu Yang, Sining Sun, Qing Yang
Speech signals are inherently complex as they encompass both global acoustic characteristics and local semantic information. However, in the task of target speech extraction, certain elements of global and local semantic information in the reference speech, which are irrelevant to speaker identity, can lead to speaker confusion within the speech extraction network. To overcome this challenge, we propose a self-supervised disentangled representation learning method. Our approach tackles this issue through a two-phase process, utilizing a reference speech encoding network and a global information disentanglement network to gradually disentangle the speaker identity information from other irrelevant factors. We exclusively employ the disentangled speaker identity information to guide the speech extraction network. Moreover, we introduce the adaptive modulation Transformer to ensure that the acoustic representation of the mixed signal remains undisturbed by the speaker embeddings. This component incorporates speaker embeddings as conditional information, facilitating natural and efficient guidance for the speech extraction network. Experimental results substantiate the effectiveness of our meticulously crafted approach, showcasing a substantial reduction in the likelihood of speaker confusion.
Read more8/27/2024