Self-supervised learning improves robustness of deep learning lung tumor segmentation to CT imaging differences

0

Sign in to get full access
Overview
- This paper explores the use of self-supervised learning to improve the robustness of deep learning models for lung tumor segmentation in computed tomography (CT) imaging.
- The researchers developed a self-supervised pretraining approach to help the model better generalize to variations in CT imaging characteristics, such as differences in image resolution, contrast, and noise levels.
- The proposed method outperformed previous fully supervised approaches in segmenting lung tumors across CT scans with diverse imaging characteristics.
Plain English Explanation
Lung cancer is a serious health issue, and accurately identifying and delineating tumors in CT scans is crucial for diagnosis and treatment planning. However, deep learning models trained for this task can struggle when applied to CT scans with different imaging characteristics, such as resolution, contrast, or noise levels.
The researchers in this paper tried to address this challenge by using a self-supervised learning approach. Instead of solely training the model on labeled CT scans, they first had it learn general visual features through a self-supervised pretraining task. This helped the model develop a more robust understanding of the underlying lung anatomy and imaging features, enabling it to better generalize to new CT scans with varying characteristics.
The self-supervised pretraining involved tasks like predicting the relative positions of image patches or the color of grayscale images. By learning to solve these pretext tasks, the model gained a more comprehensive visual understanding that could then be applied to the primary task of lung tumor segmentation.
When the researchers tested their self-supervised approach, they found that it outperformed previous fully supervised methods in segmenting lung tumors across CT scans with diverse imaging properties. This suggests that self-supervised learning can be a powerful technique for improving the robustness and performance of deep learning models in medical imaging applications, where data variability is a common challenge.
Technical Explanation
The researchers developed a self-supervised pretraining approach to improve the robustness of deep learning models for lung tumor segmentation across CT imaging differences. They used a U-Net architecture as the base model and applied self-supervised learning techniques to learn general visual representations before fine-tuning the model on the lung tumor segmentation task.
The self-supervised pretraining involved two pretext tasks: patch position prediction and colorization. For patch position prediction, the model was trained to predict the relative positions of randomly sampled image patches. This encouraged the model to learn the spatial relationships between different lung anatomy and imaging features. For colorization, the model was tasked with predicting the color of grayscale CT images, which helped it capture more comprehensive visual information.
After the self-supervised pretraining, the researchers fine-tuned the model on a dataset of labeled lung CT scans for the tumor segmentation task. They evaluated the model's performance on a held-out test set, including CT scans with varying imaging characteristics such as resolution, contrast, and noise levels.
The results showed that the self-supervised pretraining approach significantly improved the model's segmentation performance compared to a fully supervised baseline. The self-supervised model achieved higher dice scores and better generalization to CT scans with diverse imaging properties, demonstrating its robustness to such variations.
The researchers attribute the improved performance to the self-supervised pretraining, which enabled the model to learn more generalizable visual representations that were less dependent on specific imaging characteristics. This allowed the model to better handle the diverse CT scans encountered during testing, leading to more accurate and reliable lung tumor segmentation.
Critical Analysis
The researchers present a promising approach to improving the robustness of deep learning models for lung tumor segmentation in CT imaging. By incorporating self-supervised pretraining, they have shown that the model can learn more comprehensive visual representations that are less sensitive to variations in imaging characteristics.
However, the paper does not provide a detailed analysis of the specific types of imaging differences the model was able to handle, nor does it explore the limits of the model's robustness. It would be valuable to see how the model performs on a wider range of imaging variations, such as different scanners, protocols, or patient populations, to better understand the generalization capabilities.
Additionally, the paper does not discuss the computational and time requirements of the self-supervised pretraining, which could be an important consideration for practical deployment in clinical settings. The trade-offs between the improved performance and the additional training overhead should be explored further.
It would also be interesting to see how the self-supervised approach compares to other techniques for improving model robustness, such as data augmentation or domain adaptation 1, 2, 3. A more comprehensive comparison to the state-of-the-art could further validate the advantages of the proposed self-supervised method.
Overall, the paper presents a valuable contribution to the field of medical imaging and demonstrates the potential of self-supervised learning to enhance the robustness of deep learning models. Further research and validation in clinical settings would be valuable to fully assess the practical impact of this approach.
Conclusion
This paper explores the use of self-supervised learning to improve the robustness of deep learning models for lung tumor segmentation in CT imaging. The researchers developed a self-supervised pretraining approach that enabled the model to learn more generalizable visual representations, leading to better performance and generalization across CT scans with diverse imaging characteristics.
The results suggest that self-supervised learning can be a powerful technique for enhancing the robustness of medical imaging models, which is crucial for their successful deployment in real-world clinical settings. By learning comprehensive visual features through self-supervised pretraining, the model was able to better handle variations in CT imaging, resulting in more accurate and reliable lung tumor segmentation.
This work highlights the potential of self-supervised learning to address the challenges of data variability and model generalization in medical imaging applications. Further research and validation in clinical settings could help establish the practical impact of this approach and pave the way for more robust and reliable deep learning models in healthcare.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-supervised learning improves robustness of deep learning lung tumor segmentation to CT imaging differences
Jue Jiang, Aneesh Rangnekar, Harini Veeraraghavan
Self-supervised learning (SSL) is an approach to extract useful feature representations from unlabeled data, and enable fine-tuning on downstream tasks with limited labeled examples. Self-pretraining is a SSL approach that uses the curated task dataset for both pretraining the networks and fine-tuning them. Availability of large, diverse, and uncurated public medical image sets provides the opportunity to apply SSL in the wild and potentially extract features robust to imaging variations. However, the benefit of wild- vs self-pretraining has not been studied for medical image analysis. In this paper, we compare robustness of wild versus self-pretrained transformer (vision transformer [ViT] and hierarchical shifted window [Swin]) models to computed tomography (CT) imaging differences for non-small cell lung cancer (NSCLC) segmentation. Wild-pretrained Swin models outperformed self-pretrained Swin for the various imaging acquisitions. ViT resulted in similar accuracy for both wild- and self-pretrained models. Masked image prediction pretext task that forces networks to learn the local structure resulted in higher accuracy compared to contrastive task that models global image information. Wild-pretrained models resulted in higher feature reuse at the lower level layers and feature differentiation close to output layer after fine-tuning. Hence, we conclude: Wild-pretrained networks were more robust to analyzed CT imaging differences for lung tumor segmentation than self-pretrained methods. Swin architecture benefited from such pretraining more than ViT.
Read more5/15/2024

0
A Survey of the Self Supervised Learning Mechanisms for Vision Transformers
Asifullah Khan, Anabia Sohail, Mustansar Fiaz, Mehdi Hassan, Tariq Habib Afridi, Sibghat Ullah Marwat, Farzeen Munir, Safdar Ali, Hannan Naseem, Muhammad Zaigham Zaheer, Kamran Ali, Tangina Sultana, Ziaurrehman Tanoli, Naeem Akhter
Deep supervised learning models require high volume of labeled data to attain sufficiently good results. Although, the practice of gathering and annotating such big data is costly and laborious. Recently, the application of self supervised learning (SSL) in vision tasks has gained significant attention. The intuition behind SSL is to exploit the synchronous relationships within the data as a form of self-supervision, which can be versatile. In the current big data era, most of the data is unlabeled, and the success of SSL thus relies in finding ways to improve this vast amount of unlabeled data available. Thus its better for deep learning algorithms to reduce reliance on human supervision and instead focus on self-supervision based on the inherent relationships within the data. With the advent of ViTs, which have achieved remarkable results in computer vision, it is crucial to explore and understand the various SSL mechanisms employed for training these models specifically in scenarios where there is less label data available. In this survey we thus develop a comprehensive taxonomy of systematically classifying the SSL techniques based upon their representations and pre-training tasks being applied. Additionally, we discuss the motivations behind SSL, review popular pre-training tasks, and highlight the challenges and advancements in this field. Furthermore, we present a comparative analysis of different SSL methods, evaluate their strengths and limitations, and identify potential avenues for future research.
Read more9/2/2024
📈
0
Enhanced Self-supervised Learning for Multi-modality MRI Segmentation and Classification: A Novel Approach Avoiding Model Collapse
Linxuan Han, Sa Xiao, Zimeng Li, Haidong Li, Xiuchao Zhao, Fumin Guo, Yeqing Han, Xin Zhou
Multi-modality magnetic resonance imaging (MRI) can provide complementary information for computer-aided diagnosis. Traditional deep learning algorithms are suitable for identifying specific anatomical structures segmenting lesions and classifying diseases with magnetic resonance images. However, manual labels are limited due to high expense, which hinders further improvement of model accuracy. Self-supervised learning (SSL) can effectively learn feature representations from unlabeled data by pre-training and is demonstrated to be effective in natural image analysis. Most SSL methods ignore the similarity of multi-modality MRI, leading to model collapse. This limits the efficiency of pre-training, causing low accuracy in downstream segmentation and classification tasks. To solve this challenge, we establish and validate a multi-modality MRI masked autoencoder consisting of hybrid mask pattern (HMP) and pyramid barlow twin (PBT) module for SSL on multi-modality MRI analysis. The HMP concatenates three masking steps forcing the SSL to learn the semantic connections of multi-modality images by reconstructing the masking patches. We have proved that the proposed HMP can avoid model collapse. The PBT module exploits the pyramidal hierarchy of the network to construct barlow twin loss between masked and original views, aligning the semantic representations of image patches at different vision scales in latent space. Experiments on BraTS2023, PI-CAI, and lung gas MRI datasets further demonstrate the superiority of our framework over the state-of-the-art. The performance of the segmentation and classification is substantially enhanced, supporting the accurate detection of small lesion areas. The code is available at https://github.com/LinxuanHan/M2-MAE.
Read more7/18/2024
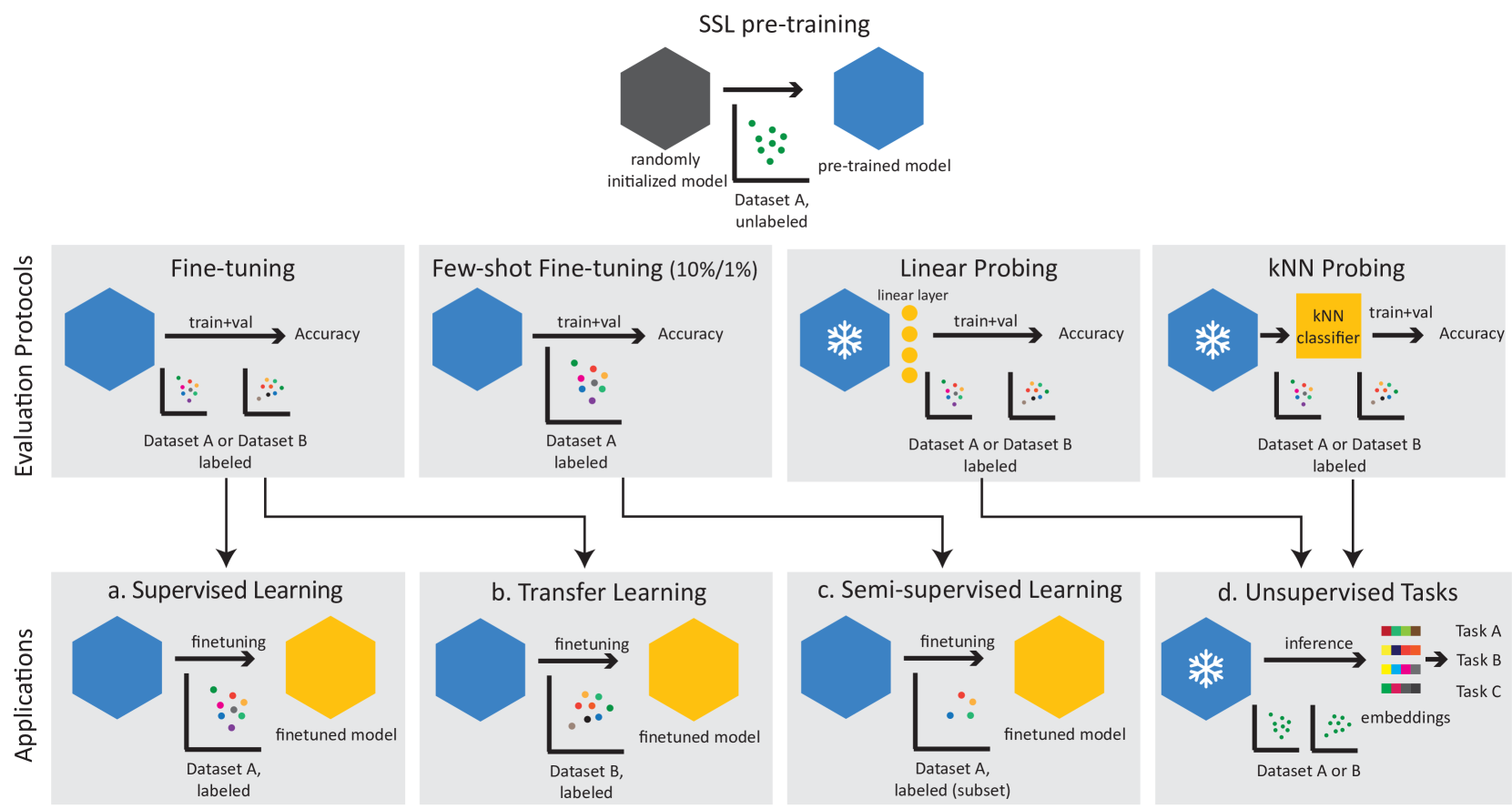
0
A Closer Look at Benchmarking Self-Supervised Pre-training with Image Classification
Markus Marks, Manuel Knott, Neehar Kondapaneni, Elijah Cole, Thijs Defraeye, Fernando Perez-Cruz, Pietro Perona
Self-supervised learning (SSL) is a machine learning approach where the data itself provides supervision, eliminating the need for external labels. The model is forced to learn about the data structure or context by solving a pretext task. With SSL, models can learn from abundant and cheap unlabeled data, significantly reducing the cost of training models where labels are expensive or inaccessible. In Computer Vision, SSL is widely used as pre-training followed by a downstream task, such as supervised transfer, few-shot learning on smaller labeled data sets, and/or unsupervised clustering. Unfortunately, it is infeasible to evaluate SSL methods on all possible downstream tasks and objectively measure the quality of the learned representation. Instead, SSL methods are evaluated using in-domain evaluation protocols, such as fine-tuning, linear probing, and k-nearest neighbors (kNN). However, it is not well understood how well these evaluation protocols estimate the representation quality of a pre-trained model for different downstream tasks under different conditions, such as dataset, metric, and model architecture. We study how classification-based evaluation protocols for SSL correlate and how well they predict downstream performance on different dataset types. Our study includes eleven common image datasets and 26 models that were pre-trained with different SSL methods or have different model backbones. We find that in-domain linear/kNN probing protocols are, on average, the best general predictors for out-of-domain performance. We further investigate the importance of batch normalization and evaluate how robust correlations are for different kinds of dataset domain shifts. We challenge assumptions about the relationship between discriminative and generative self-supervised methods, finding that most of their performance differences can be explained by changes to model backbones.
Read more7/19/2024