A Self-Supervised Learning Pipeline for Demographically Fair Facial Attribute Classification

0

Sign in to get full access
Overview
- This paper presents a self-supervised learning pipeline to improve the demographic fairness of facial attribute classification models.
- The approach uses self-supervised learning to pre-train a model on unlabeled data, before fine-tuning it on a smaller labeled dataset for the target task.
- The authors demonstrate that this pipeline can significantly improve the performance and fairness of facial attribute classification models compared to traditional supervised learning.
Plain English Explanation
In this paper, the researchers developed a new way to train facial recognition models to be more fair and accurate. Facial recognition models are used in many applications, like identifying people in photos or videos. However, these models can sometimes perform better or worse depending on the person's demographic characteristics, like their race or gender.
To address this issue, the researchers used a technique called self-supervised learning. self-supervised learning algorithms allow a model to learn useful representations from unlabeled data, before being fine-tuned on a smaller labeled dataset for the specific task.
By pre-training the model this way, the researchers found they could significantly improve the model's overall performance and make it more fair across different demographic groups. This is an important advance, as it can help break free from the need for strong data to train accurate and fair facial recognition systems.
Technical Explanation
The key elements of the paper are:
-
Self-Supervised Pre-Training: The researchers used a self-supervised learning approach to pre-train a facial recognition model on a large, unlabeled dataset of face images. This allowed the model to learn useful feature representations without any labeled data.
-
Fine-Tuning for Facial Attribute Classification: After pre-training, the model was then fine-tuned on a smaller labeled dataset for the specific task of facial attribute classification (e.g., predicting age, gender, etc.). This allowed the model to specialize its learned representations to the target task.
-
Evaluation of Performance and Fairness: The researchers evaluated their approach on several facial attribute classification benchmarks, measuring both the overall accuracy of the model as well as its fairness across different demographic subgroups. They showed significant improvements over traditional supervised learning baselines.
The key insight is that the self-supervised pre-training step helps the model learn more robust and generalizable features that translate better to the downstream task, leading to better performance and fairness.
Critical Analysis
The paper presents a compelling approach to improving the demographic fairness of facial recognition models. However, some potential limitations and areas for future research include:
-
The self-supervised pre-training approach relies on having access to a large, diverse, and representative dataset of unlabeled face images. Collecting and curating such a dataset can be challenging in practice.
-
The paper evaluates fairness using standard demographic parity metrics, but there may be other important fairness considerations (e.g., equal opportunity, calibration) that are not addressed.
-
The experiments are focused on facial attribute classification, but it's unclear how well the approach would generalize to other facial recognition tasks, such as face identification or verification.
Overall, the paper presents a promising direction for improving the fairness of facial recognition systems, but more research is needed to fully understand the broader implications and potential limitations of this approach.
Conclusion
This paper introduces a self-supervised learning pipeline that can significantly improve the performance and demographic fairness of facial attribute classification models. By pre-training on unlabeled data before fine-tuning on a smaller labeled dataset, the approach learns more robust and generalizable features that translate better to the target task.
The insights from this work could have important implications for developing more inclusive and equitable AI systems that do not exhibit unfair biases based on a person's demographic characteristics. As AI continues to be deployed in high-stakes applications, ensuring algorithmic fairness will be critical for building trust and promoting social good.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Self-Supervised Learning Pipeline for Demographically Fair Facial Attribute Classification
Sreeraj Ramachandran, Ajita Rattani
Published research highlights the presence of demographic bias in automated facial attribute classification. The proposed bias mitigation techniques are mostly based on supervised learning, which requires a large amount of labeled training data for generalizability and scalability. However, labeled data is limited, requires laborious annotation, poses privacy risks, and can perpetuate human bias. In contrast, self-supervised learning (SSL) capitalizes on freely available unlabeled data, rendering trained models more scalable and generalizable. However, these label-free SSL models may also introduce biases by sampling false negative pairs, especially at low-data regimes 200K images) under low compute settings. Further, SSL-based models may suffer from performance degradation due to a lack of quality assurance of the unlabeled data sourced from the web. This paper proposes a fully self-supervised pipeline for demographically fair facial attribute classifiers. Leveraging completely unlabeled data pseudolabeled via pre-trained encoders, diverse data curation techniques, and meta-learning-based weighted contrastive learning, our method significantly outperforms existing SSL approaches proposed for downstream image classification tasks. Extensive evaluations on the FairFace and CelebA datasets demonstrate the efficacy of our pipeline in obtaining fair performance over existing baselines. Thus, setting a new benchmark for SSL in the fairness of facial attribute classification.
Read more7/16/2024
0
Using Self-supervised Learning Can Improve Model Fairness
Sofia Yfantidou, Dimitris Spathis, Marios Constantinides, Athena Vakali, Daniele Quercia, Fahim Kawsar
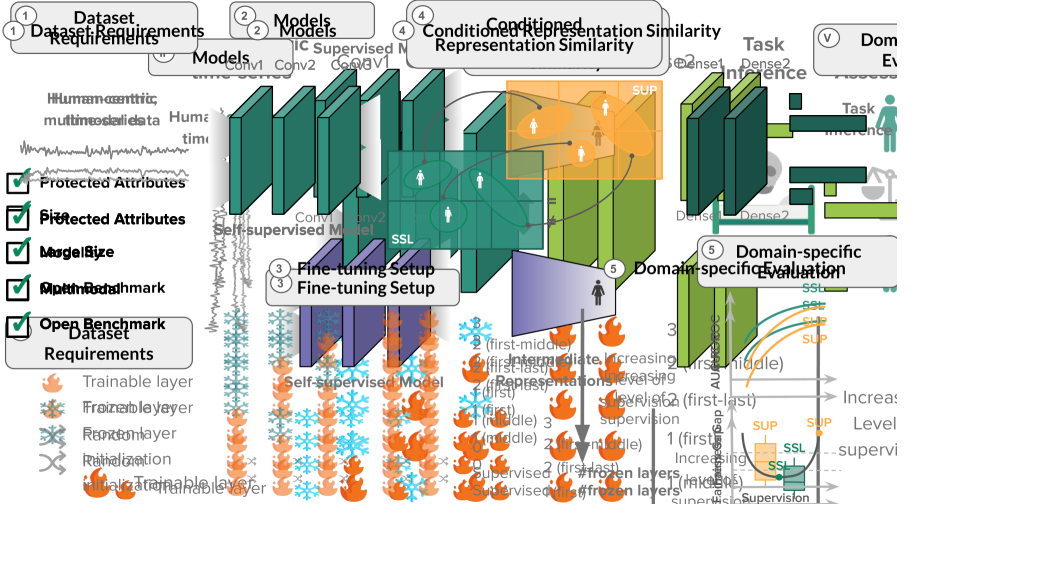
Self-supervised learning (SSL) has become the de facto training paradigm of large models, where pre-training is followed by supervised fine-tuning using domain-specific data and labels. Despite demonstrating comparable performance with supervised methods, comprehensive efforts to assess SSL's impact on machine learning fairness (i.e., performing equally on different demographic breakdowns) are lacking. Hypothesizing that SSL models would learn more generic, hence less biased representations, this study explores the impact of pre-training and fine-tuning strategies on fairness. We introduce a fairness assessment framework for SSL, comprising five stages: defining dataset requirements, pre-training, fine-tuning with gradual unfreezing, assessing representation similarity conditioned on demographics, and establishing domain-specific evaluation processes. We evaluate our method's generalizability on three real-world human-centric datasets (i.e., MIMIC, MESA, and GLOBEM) by systematically comparing hundreds of SSL and fine-tuned models on various dimensions spanning from the intermediate representations to appropriate evaluation metrics. Our findings demonstrate that SSL can significantly improve model fairness, while maintaining performance on par with supervised methods-exhibiting up to a 30% increase in fairness with minimal loss in performance through self-supervision. We posit that such differences can be attributed to representation dissimilarities found between the best- and the worst-performing demographics across models-up to x13 greater for protected attributes with larger performance discrepancies between segments.
Read more6/5/2024

0
Generalized Semi-Supervised Learning via Self-Supervised Feature Adaptation
Jiachen Liang, Ruibing Hou, Hong Chang, Bingpeng Ma, Shiguang Shan, Xilin Chen
Traditional semi-supervised learning (SSL) assumes that the feature distributions of labeled and unlabeled data are consistent which rarely holds in realistic scenarios. In this paper, we propose a novel SSL setting, where unlabeled samples are drawn from a mixed distribution that deviates from the feature distribution of labeled samples. Under this setting, previous SSL methods tend to predict wrong pseudo-labels with the model fitted on labeled data, resulting in noise accumulation. To tackle this issue, we propose Self-Supervised Feature Adaptation (SSFA), a generic framework for improving SSL performance when labeled and unlabeled data come from different distributions. SSFA decouples the prediction of pseudo-labels from the current model to improve the quality of pseudo-labels. Particularly, SSFA incorporates a self-supervised task into the SSL framework and uses it to adapt the feature extractor of the model to the unlabeled data. In this way, the extracted features better fit the distribution of unlabeled data, thereby generating high-quality pseudo-labels. Extensive experiments show that our proposed SSFA is applicable to various pseudo-label-based SSL learners and significantly improves performance in labeled, unlabeled, and even unseen distributions.
Read more6/3/2024
0
A Closer Look at Benchmarking Self-Supervised Pre-training with Image Classification
Markus Marks, Manuel Knott, Neehar Kondapaneni, Elijah Cole, Thijs Defraeye, Fernando Perez-Cruz, Pietro Perona
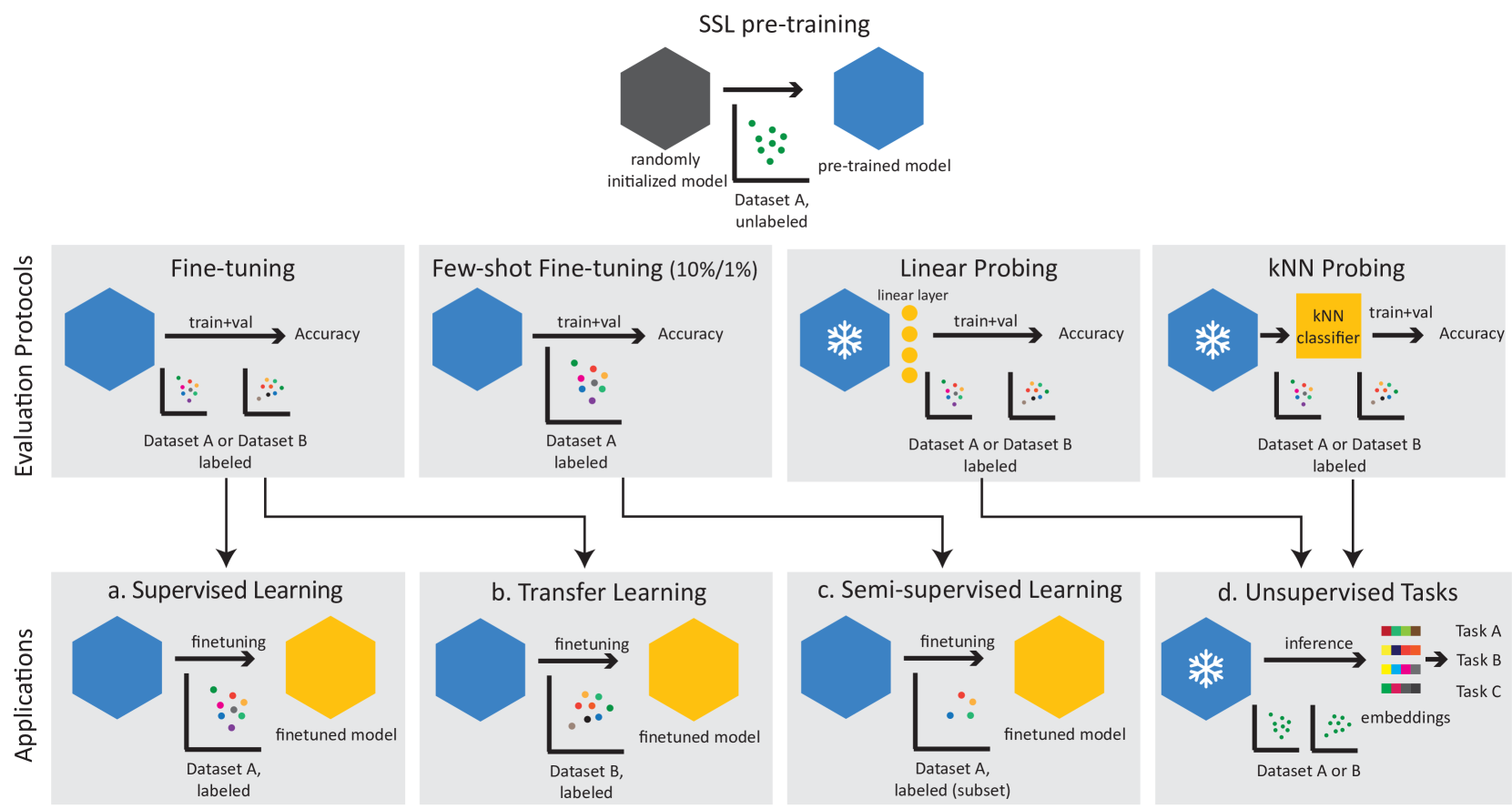
Self-supervised learning (SSL) is a machine learning approach where the data itself provides supervision, eliminating the need for external labels. The model is forced to learn about the data structure or context by solving a pretext task. With SSL, models can learn from abundant and cheap unlabeled data, significantly reducing the cost of training models where labels are expensive or inaccessible. In Computer Vision, SSL is widely used as pre-training followed by a downstream task, such as supervised transfer, few-shot learning on smaller labeled data sets, and/or unsupervised clustering. Unfortunately, it is infeasible to evaluate SSL methods on all possible downstream tasks and objectively measure the quality of the learned representation. Instead, SSL methods are evaluated using in-domain evaluation protocols, such as fine-tuning, linear probing, and k-nearest neighbors (kNN). However, it is not well understood how well these evaluation protocols estimate the representation quality of a pre-trained model for different downstream tasks under different conditions, such as dataset, metric, and model architecture. We study how classification-based evaluation protocols for SSL correlate and how well they predict downstream performance on different dataset types. Our study includes eleven common image datasets and 26 models that were pre-trained with different SSL methods or have different model backbones. We find that in-domain linear/kNN probing protocols are, on average, the best general predictors for out-of-domain performance. We further investigate the importance of batch normalization and evaluate how robust correlations are for different kinds of dataset domain shifts. We challenge assumptions about the relationship between discriminative and generative self-supervised methods, finding that most of their performance differences can be explained by changes to model backbones.
Read more7/19/2024