A Survey on Self-supervised Learning: Algorithms, Applications, and Future Trends

0
🌀
Sign in to get full access
Overview
- Supervised learning algorithms often require large amounts of labeled data, which can be costly and time-consuming to obtain.
- Self-supervised learning (SSL) aims to extract useful features from unlabeled data without relying on human-annotated labels.
- SSL has gained significant attention, leading to the development of numerous related algorithms.
- This paper provides a comprehensive review of various SSL methods, including their algorithmic aspects, application domains, key trends, and open research questions.
Plain English Explanation
Self-supervised learning (SSL) is a type of machine learning that can learn useful features from data without the need for human-labeled examples. This is different from traditional supervised learning, which requires a large dataset of labeled data to train models effectively.
The process of collecting and labeling data can be time-consuming and expensive, especially for certain tasks. SSL aims to overcome this limitation by finding patterns and relationships in unlabeled data, which is often more readily available. By learning from the inherent structure of the data itself, SSL algorithms can discover important features that can then be used to solve various problems, such as image recognition or natural language processing.
This paper examines the different SSL algorithms that have been developed, exploring how they work, where they are being applied, and the key trends and open research questions in this rapidly evolving field. The authors provide a detailed overview of the motivations behind SSL, as well as the commonalities and differences between various SSL approaches. They also highlight representative applications of SSL across domains like computer vision and natural language processing.
Additionally, the paper discusses three primary trends in SSL research, such as the use of time series analysis and efforts to break free from strong data requirements. The authors also identify open research questions, including the need to better understand the probabilistic models underlying SSL.
Overall, this review provides a comprehensive look at the current state of SSL, highlighting its potential to revolutionize machine learning by enabling more efficient and effective training of models without the need for extensive human-labeled data.
Technical Explanation
This paper presents a comprehensive review of diverse self-supervised learning (SSL) methods, covering their algorithmic aspects, application domains, key trends, and open research questions.
The authors begin by providing a detailed introduction to the motivations behind most SSL algorithms and comparing their commonalities and differences. SSL aims to learn discriminative features from unlabeled data without relying on human-annotated labels, addressing the challenge of obtaining large volumes of labeled data required for satisfactory performance in traditional supervised learning.
The paper then explores representative applications of SSL across various domains, including image processing, computer vision, and natural language processing. These applications demonstrate the versatility of SSL in extracting useful features from data without the need for extensive manual labeling.
Furthermore, the authors discuss three primary trends observed in SSL research. These include the use of time series analysis techniques, efforts to break free from strong data requirements, and a growing interest in understanding the probabilistic models behind SSL.
The paper concludes by highlighting the open research questions that remain in the field of SSL. These include the need to further investigate the theoretical underpinnings of SSL algorithms, explore their performance limits, and develop more effective techniques for leveraging unlabeled data to enhance model performance.
Critical Analysis
The paper provides a comprehensive overview of the field of self-supervised learning, covering a wide range of algorithms, application domains, and research trends. The authors have done an excellent job of synthesizing the existing literature and highlighting the key developments in this rapidly evolving area of machine learning.
One strength of the paper is its detailed exploration of the motivations and fundamental principles behind SSL algorithms. By comparing the commonalities and differences between various SSL approaches, the authors help readers gain a deeper understanding of the core concepts and the underlying principles driving this field of research.
However, the paper could have delved deeper into the limitations and potential drawbacks of SSL. While the authors mention the need to better understand the theoretical foundations and performance limits of SSL, they could have provided a more critical analysis of the current challenges and areas for improvement.
Additionally, the paper could have discussed the ethical considerations and societal implications of SSL, particularly in domains like computer vision and natural language processing, where the use of unlabeled data could raise concerns about privacy, bias, and fairness.
Overall, this paper serves as an excellent resource for researchers and practitioners interested in understanding the state-of-the-art in self-supervised learning. The authors have done a commendable job of synthesizing a complex and rapidly evolving field, providing a solid foundation for further exploration and critical analysis.
Conclusion
This comprehensive review of self-supervised learning (SSL) algorithms and trends highlights the significant potential of this approach to overcome the limitations of traditional supervised learning. By leveraging unlabeled data to learn useful features, SSL offers a more efficient and cost-effective way to train machine learning models, with applications across a wide range of domains.
The paper's detailed examination of SSL's algorithmic aspects, representative applications, and emerging research directions provides a valuable resource for the research community. It also raises important questions about the theoretical underpinnings, performance limits, and societal implications of this rapidly evolving field.
As the authors have noted, further research is needed to better understand the probabilistic models behind SSL and explore ways to break free from strong data requirements. Addressing these challenges will be crucial for unlocking the full potential of SSL and driving innovation in areas like computer vision, natural language processing, and time series analysis.
Overall, this review serves as an invaluable resource for researchers and practitioners seeking to deepen their understanding of self-supervised learning and its implications for the future of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
0
A Survey on Self-supervised Learning: Algorithms, Applications, and Future Trends
Jie Gui, Tuo Chen, Jing Zhang, Qiong Cao, Zhenan Sun, Hao Luo, Dacheng Tao
Deep supervised learning algorithms typically require a large volume of labeled data to achieve satisfactory performance. However, the process of collecting and labeling such data can be expensive and time-consuming. Self-supervised learning (SSL), a subset of unsupervised learning, aims to learn discriminative features from unlabeled data without relying on human-annotated labels. SSL has garnered significant attention recently, leading to the development of numerous related algorithms. However, there is a dearth of comprehensive studies that elucidate the connections and evolution of different SSL variants. This paper presents a review of diverse SSL methods, encompassing algorithmic aspects, application domains, three key trends, and open research questions. Firstly, we provide a detailed introduction to the motivations behind most SSL algorithms and compare their commonalities and differences. Secondly, we explore representative applications of SSL in domains such as image processing, computer vision, and natural language processing. Lastly, we discuss the three primary trends observed in SSL research and highlight the open questions that remain. A curated collection of valuable resources can be accessed at https://github.com/guijiejie/SSL.
Read more7/16/2024

0
A Survey of the Self Supervised Learning Mechanisms for Vision Transformers
Asifullah Khan, Anabia Sohail, Mustansar Fiaz, Mehdi Hassan, Tariq Habib Afridi, Sibghat Ullah Marwat, Farzeen Munir, Safdar Ali, Hannan Naseem, Muhammad Zaigham Zaheer, Kamran Ali, Tangina Sultana, Ziaurrehman Tanoli, Naeem Akhter
Deep supervised learning models require high volume of labeled data to attain sufficiently good results. Although, the practice of gathering and annotating such big data is costly and laborious. Recently, the application of self supervised learning (SSL) in vision tasks has gained significant attention. The intuition behind SSL is to exploit the synchronous relationships within the data as a form of self-supervision, which can be versatile. In the current big data era, most of the data is unlabeled, and the success of SSL thus relies in finding ways to improve this vast amount of unlabeled data available. Thus its better for deep learning algorithms to reduce reliance on human supervision and instead focus on self-supervision based on the inherent relationships within the data. With the advent of ViTs, which have achieved remarkable results in computer vision, it is crucial to explore and understand the various SSL mechanisms employed for training these models specifically in scenarios where there is less label data available. In this survey we thus develop a comprehensive taxonomy of systematically classifying the SSL techniques based upon their representations and pre-training tasks being applied. Additionally, we discuss the motivations behind SSL, review popular pre-training tasks, and highlight the challenges and advancements in this field. Furthermore, we present a comparative analysis of different SSL methods, evaluate their strengths and limitations, and identify potential avenues for future research.
Read more9/2/2024
0
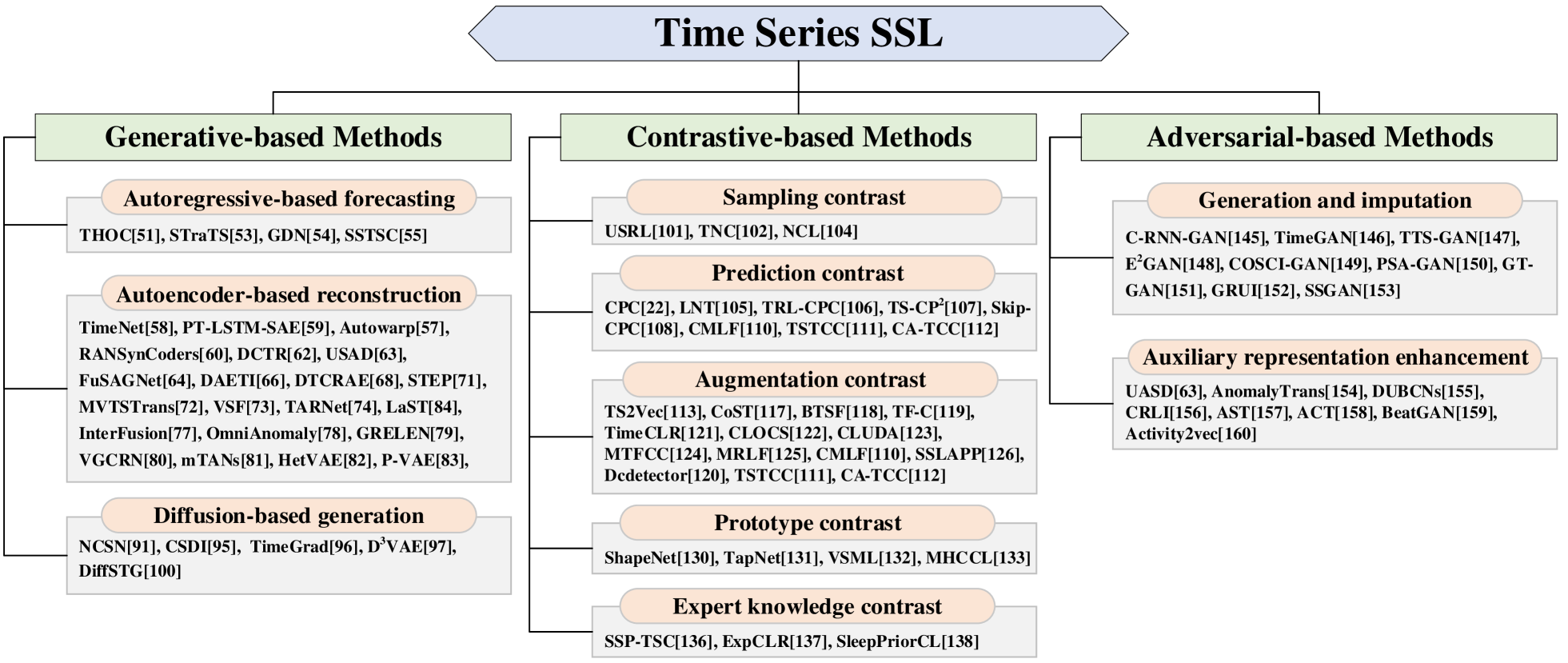
Self-Supervised Learning for Time Series Analysis: Taxonomy, Progress, and Prospects
Kexin Zhang, Qingsong Wen, Chaoli Zhang, Rongyao Cai, Ming Jin, Yong Liu, James Zhang, Yuxuan Liang, Guansong Pang, Dongjin Song, Shirui Pan
Self-supervised learning (SSL) has recently achieved impressive performance on various time series tasks. The most prominent advantage of SSL is that it reduces the dependence on labeled data. Based on the pre-training and fine-tuning strategy, even a small amount of labeled data can achieve high performance. Compared with many published self-supervised surveys on computer vision and natural language processing, a comprehensive survey for time series SSL is still missing. To fill this gap, we review current state-of-the-art SSL methods for time series data in this article. To this end, we first comprehensively review existing surveys related to SSL and time series, and then provide a new taxonomy of existing time series SSL methods by summarizing them from three perspectives: generative-based, contrastive-based, and adversarial-based. These methods are further divided into ten subcategories with detailed reviews and discussions about their key intuitions, main frameworks, advantages and disadvantages. To facilitate the experiments and validation of time series SSL methods, we also summarize datasets commonly used in time series forecasting, classification, anomaly detection, and clustering tasks. Finally, we present the future directions of SSL for time series analysis.
Read more4/9/2024

0
A Comprehensive Survey on Self-Supervised Learning for Recommendation
Xubin Ren, Wei Wei, Lianghao Xia, Chao Huang
Recommender systems play a crucial role in tackling the challenge of information overload by delivering personalized recommendations based on individual user preferences. Deep learning techniques, such as RNNs, GNNs, and Transformer architectures, have significantly propelled the advancement of recommender systems by enhancing their comprehension of user behaviors and preferences. However, supervised learning methods encounter challenges in real-life scenarios due to data sparsity, resulting in limitations in their ability to learn representations effectively. To address this, self-supervised learning (SSL) techniques have emerged as a solution, leveraging inherent data structures to generate supervision signals without relying solely on labeled data. By leveraging unlabeled data and extracting meaningful representations, recommender systems utilizing SSL can make accurate predictions and recommendations even when confronted with data sparsity. In this paper, we provide a comprehensive review of self-supervised learning frameworks designed for recommender systems, encompassing a thorough analysis of over 170 papers. We conduct an exploration of nine distinct scenarios, enabling a comprehensive understanding of SSL-enhanced recommenders in different contexts. For each domain, we elaborate on different self-supervised learning paradigms, namely contrastive learning, generative learning, and adversarial learning, so as to present technical details of how SSL enhances recommender systems in various contexts. We consistently maintain the related open-source materials at https://github.com/HKUDS/Awesome-SSLRec-Papers.
Read more4/9/2024