Self-supervised Topic Taxonomy Discovery in the Box Embedding Space

0
Sign in to get full access
Overview
- The paper proposes a self-supervised method for discovering a topic taxonomy in the box embedding space.
- It explores how the semantic relationships between topics can be captured using a box-based representation.
- The approach aims to learn a hierarchical topic taxonomy from unlabeled text data in an unsupervised manner.
Plain English Explanation
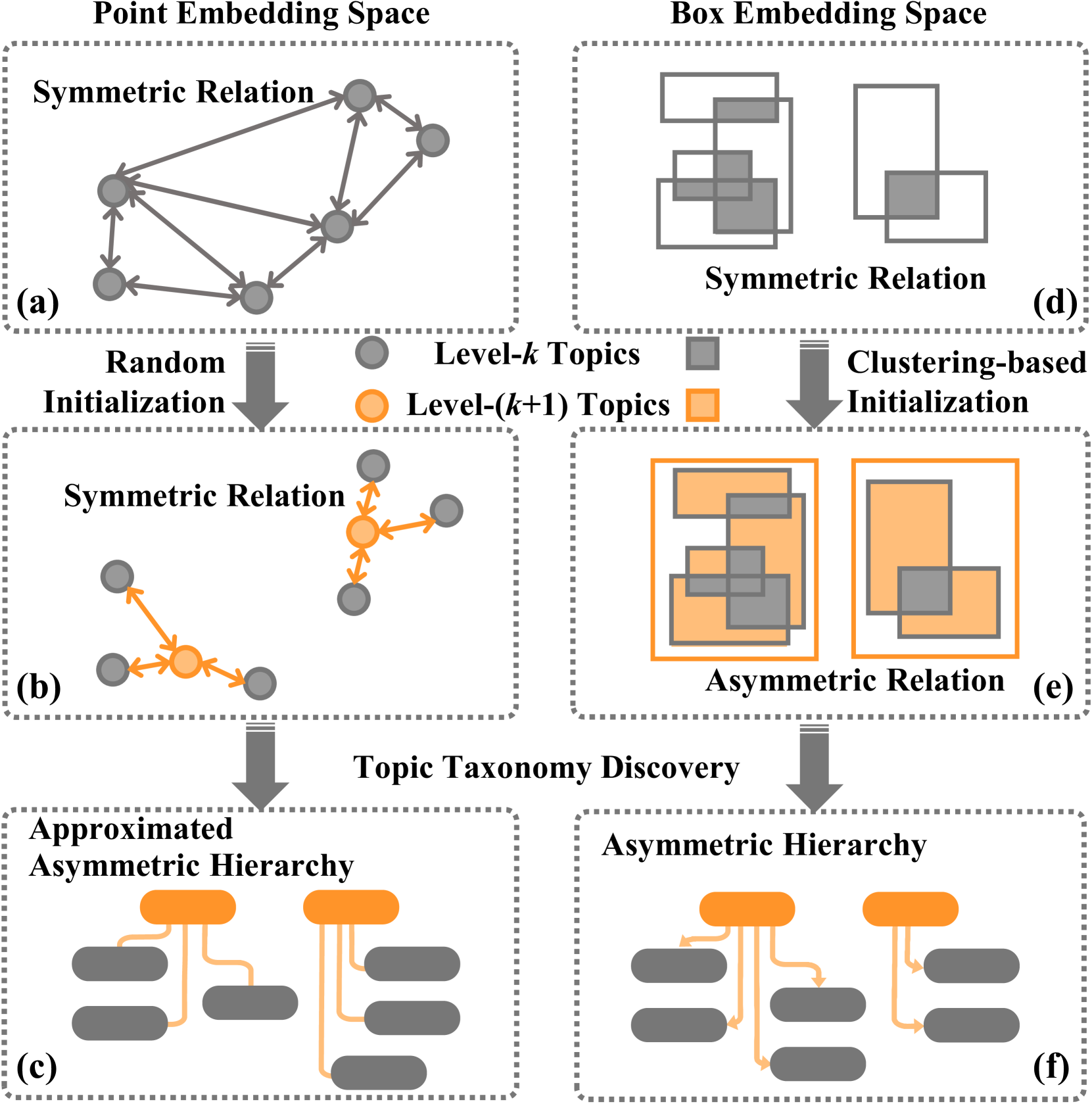
The researchers developed a new way to organize and understand the relationships between different topics in a large collection of text data, such as academic papers or news articles. Instead of using traditional topic modeling techniques, they represent each topic as a "box" in a multi-dimensional space.
These boxes allow the model to capture not only the main topic of a document, but also how that topic is related to other topics in a hierarchical way. For example, the topic of "machine learning" might be a larger box that contains smaller boxes for more specific sub-topics like "neural networks" and "decision trees."
The key innovation is that the model learns this topic taxonomy in a self-supervised way, without requiring any manual labeling or categorization of the text data. It can discover the topic structure automatically by analyzing the patterns and relationships in the text itself.
This approach could be useful for organizing large document collections, enhancing language models, or even building taxonomic knowledge bases. By understanding the hierarchical relationships between topics, it may be possible to better navigate and make sense of complex information landscapes.
Technical Explanation
The paper introduces a self-supervised method for discovering a topic taxonomy in the box embedding space. The core idea is to represent each topic as a multi-dimensional "box" that can capture both the main theme of the topic as well as its relationships to other topics in a hierarchical manner.
The approach involves two main steps:
-
Box Embedding Learning: The model learns low-dimensional box embeddings for each topic by optimizing an objective function that encourages the boxes to tightly cover the text documents associated with each topic, while also ensuring that the boxes do not overlap excessively.
-
Taxonomy Discovery: The learned box embeddings are then used to construct a topic taxonomy by recursively splitting the topic boxes into smaller sub-topics based on their semantic relationships. This is done by identifying the optimal split points that maximize the separation between sub-topics while minimizing the overlap.
The authors evaluate their method on several benchmark datasets and show that it outperforms various baselines in terms of recovering the ground truth topic taxonomies. They also demonstrate the interpretability of the learned topic boxes and their ability to capture meaningful hierarchical relationships.
Critical Analysis
The key strengths of this work are the novel box-based representation of topics and the self-supervised approach to discovering the topic taxonomy. By learning the topic structure directly from the text data, the method avoids the need for manual labeling or prior knowledge, which can be a significant bottleneck for many real-world applications.
However, the paper does not address some potential limitations and areas for further research:
-
Scalability: The taxonomy discovery process relies on recursively splitting the topic boxes, which may become computationally expensive as the number of topics and the depth of the taxonomy grow. Investigating more efficient algorithms or approximation techniques could be an important direction.
-
Interpretability: While the paper demonstrates the interpretability of the learned topic boxes, it would be valuable to further explore how the box representations can be made more transparent and intuitive for users, especially in the context of large-scale taxonomies.
-
Evaluation: The authors use standard taxonomy evaluation metrics, but it would be interesting to also consider task-specific evaluations, such as how the discovered taxonomies impact downstream applications like text classification or knowledge base construction.
-
Robustness: The paper does not explore the sensitivity of the method to factors like data quality, noise, or domain shifts. Understanding the limitations and failure modes of the approach would be valuable for real-world deployments.
Overall, the proposed self-supervised topic taxonomy discovery method is a promising step towards more flexible and scalable ways of organizing and understanding large text corpora. Further research to address the identified limitations could lead to significant advancements in this important area.
Conclusion
This paper introduces a novel self-supervised approach for discovering a topic taxonomy in the box embedding space. By representing topics as multi-dimensional boxes, the method can capture both the main themes of the topics and their hierarchical relationships. The authors demonstrate the effectiveness of their approach on several benchmark datasets and highlight the interpretability of the learned topic structures.
While the paper makes a valuable contribution to the field of topic modeling and taxonomy learning, there are several areas for potential improvement and further research, such as scalability, interpretability, and robustness. Addressing these challenges could lead to more practical and impactful applications of this technology in domains like text classification, knowledge management, and information retrieval.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-supervised Topic Taxonomy Discovery in the Box Embedding Space
Yuyin Lu, Hegang Chen, Pengbo Mao, Yanghui Rao, Haoran Xie, Fu Lee Wang, Qing Li
Topic taxonomy discovery aims at uncovering topics of different abstraction levels and constructing hierarchical relations between them. Unfortunately, most of prior work can hardly model semantic scopes of words and topics by holding the Euclidean embedding space assumption. What's worse, they infer asymmetric hierarchical relations by symmetric distances between topic embeddings. As a result, existing methods suffer from problems of low-quality topics at high abstraction levels and inaccurate hierarchical relations. To alleviate these problems, this paper develops a Box embedding-based Topic Model (BoxTM) that maps words and topics into the box embedding space, where the asymmetric metric is defined to properly infer hierarchical relations among topics. Additionally, our BoxTM explicitly infers upper-level topics based on correlation between specific topics through recursive clustering on topic boxes. Finally, extensive experiments validate high-quality of the topic taxonomy learned by BoxTM.
Read more8/28/2024
✨
0
Taxonomy Completion with Probabilistic Scorer via Box Embedding
Wei Xue, Yongliang Shen, Wenqi Ren, Jietian Guo, Shiliang Pu, Weiming Lu
Taxonomy completion, enriching existing taxonomies by inserting new concepts as parents or attaching them as children, has gained significant interest. Previous approaches embed concepts as vectors in Euclidean space, which makes it difficult to model asymmetric relations in taxonomy. In addition, they introduce pseudo-leaves to convert attachment cases into insertion cases, leading to an incorrect bias in network learning dominated by numerous pseudo-leaves. Addressing these, our framework, TaxBox, leverages box containment and center closeness to design two specialized geometric scorers within the box embedding space. These scorers are tailored for insertion and attachment operations and can effectively capture intrinsic relationships between concepts by optimizing on a granular box constraint loss. We employ a dynamic ranking loss mechanism to balance the scores from these scorers, allowing adaptive adjustments of insertion and attachment scores. Experiments on four real-world datasets show that TaxBox significantly outperforms previous methods, yielding substantial improvements over prior methods in real-world datasets, with average performance boosts of 6.7%, 34.9%, and 51.4% in MRR, Hit@1, and Prec@1, respectively.
Read more6/19/2024

0
Concept Formation and Alignment in Language Models: Bridging Statistical Patterns in Latent Space to Concept Taxonomy
Mehrdad Khatir, Chandan K. Reddy
This paper explores the concept formation and alignment within the realm of language models (LMs). We propose a mechanism for identifying concepts and their hierarchical organization within the semantic representations learned by various LMs, encompassing a spectrum from early models like Glove to the transformer-based language models like ALBERT and T5. Our approach leverages the inherent structure present in the semantic embeddings generated by these models to extract a taxonomy of concepts and their hierarchical relationships. This investigation sheds light on how LMs develop conceptual understanding and opens doors to further research to improve their ability to reason and leverage real-world knowledge. We further conducted experiments and observed the possibility of isolating these extracted conceptual representations from the reasoning modules of the transformer-based LMs. The observed concept formation along with the isolation of conceptual representations from the reasoning modules can enable targeted token engineering to open the door for potential applications in knowledge transfer, explainable AI, and the development of more modular and conceptually grounded language models.
Read more6/11/2024

0
Taxonomy-Aware Continual Semantic Segmentation in Hyperbolic Spaces for Open-World Perception
Julia Hindel, Daniele Cattaneo, Abhinav Valada
Semantic segmentation models are typically trained on a fixed set of classes, limiting their applicability in open-world scenarios. Class-incremental semantic segmentation aims to update models with emerging new classes while preventing catastrophic forgetting of previously learned ones. However, existing methods impose strict rigidity on old classes, reducing their effectiveness in learning new incremental classes. In this work, we propose Taxonomy-Oriented Poincar'e-regularized Incremental-Class Segmentation (TOPICS) that learns feature embeddings in hyperbolic space following explicit taxonomy-tree structures. This supervision provides plasticity for old classes, updating ancestors based on new classes while integrating new classes at fitting positions. Additionally, we maintain implicit class relational constraints on the geometric basis of the Poincar'e ball. This ensures that the latent space can continuously adapt to new constraints while maintaining a robust structure to combat catastrophic forgetting. We also establish eight realistic incremental learning protocols for autonomous driving scenarios, where novel classes can originate from known classes or the background. Extensive evaluations of TOPICS on the Cityscapes and Mapillary Vistas 2.0 benchmarks demonstrate that it achieves state-of-the-art performance. We make the code and trained models publicly available at http://topics.cs.uni-freiburg.de.
Read more7/26/2024