Taxonomy Completion with Probabilistic Scorer via Box Embedding

0
✨
Sign in to get full access
Overview
- Taxonomy completion, enriching existing taxonomies by inserting new concepts, has gained significant interest
- Previous approaches embed concepts as vectors, making it difficult to model asymmetric relations in taxonomy
- They also introduce pseudo-leaves to convert attachment cases into insertion cases, leading to bias in network learning
- The paper introduces TaxBox, a framework that leverages box containment and center closeness to design specialized geometric scorers within the box embedding space
Plain English Explanation
The research paper discusses an approach called TaxBox for improving taxonomies, which are hierarchical structures that organize concepts or entities. Taxonomies are useful for tasks like information retrieval and knowledge representation, but they can be difficult to maintain and update as new concepts emerge.
Previous methods for adding new concepts to taxonomies have relied on embedding the concepts as points in a geometric space, but this makes it hard to capture the asymmetric relationships between concepts (e.g. a car is a type of vehicle, but a vehicle is not necessarily a type of car). Additionally, these methods had to introduce "pseudo-leaves" to the taxonomy to handle certain cases, which introduced bias into the learning process.
To address these issues, the TaxBox framework uses a different geometric representation - box embeddings, where each concept is represented as a box in space. This allows TaxBox to directly model the hierarchical containment relationships between concepts using the box containment and center closeness properties. The paper describes two specialized scorers that TaxBox uses to evaluate potential insertion and attachment operations, and a dynamic ranking loss mechanism to balance these scores.
Experiments on real-world datasets show that TaxBox significantly outperforms previous methods, improving measures like Mean Reciprocal Rank, Hit@1, and Precision@1 by 6.7%, 34.9%, and 51.4% on average, respectively. This suggests that the box embedding approach is better able to capture the inherent structure of taxonomies compared to previous vector-based methods.
Technical Explanation
The key technical components of the TaxBox framework are:
-
Box Embeddings: Instead of representing concepts as points in a Euclidean space, TaxBox embeds them as boxes. This allows the model to directly capture the hierarchical containment relationships between concepts using the box containment and center closeness properties.
-
Specialized Scorers: TaxBox employs two specialized geometric scorers to evaluate potential insertion and attachment operations:
- Insertion Scorer: Measures how well a new concept can be inserted as the parent of an existing concept, based on box containment.
- Attachment Scorer: Measures how well a new concept can be attached as the child of an existing concept, based on center closeness.
-
Dynamic Ranking Loss: TaxBox uses a dynamic ranking loss mechanism to balance the scores from the insertion and attachment scorers, allowing the model to adaptively adjust the relative importance of each type of operation during training.
The paper evaluates TaxBox on four real-world taxonomy completion datasets and compares it to previous vector-based approaches. The results show that TaxBox significantly outperforms these methods, with average performance boosts of 6.7%, 34.9%, and 51.4% in MRR, Hit@1, and Prec@1, respectively.
Critical Analysis
The paper provides a compelling approach to the taxonomy completion problem, addressing key limitations of previous methods. The use of box embeddings to directly model hierarchical containment relationships is a novel and promising direction.
However, the paper does not discuss the computational complexity or training time of the TaxBox framework, which could be an important practical consideration, especially for large-scale taxonomies. Additionally, the paper does not explore the interpretability of the box embeddings or provide insights into how the model's decisions align with human intuitions about taxonomy structure.
Further research could investigate the robustness of TaxBox to noisy or incomplete taxonomy data, as well as its extensibility to other taxonomy-related tasks, such as contextual categorization enhancement or symbiotic taxonomy fusion. Exploring applications of TaxBox to continuous domains or entity-guided instruction tuning could also be fruitful avenues for future work.
Conclusion
The TaxBox framework represents a significant advancement in the field of taxonomy completion by leveraging box embeddings to better capture the inherent hierarchical structure of taxonomies. Its specialized scorers and dynamic ranking loss mechanism allow it to outperform previous vector-based methods across a range of evaluation metrics. While the paper raises some questions about computational efficiency and interpretability, the core ideas behind TaxBox suggest a promising direction for future research on improving and maintaining taxonomic knowledge structures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
0
Taxonomy Completion with Probabilistic Scorer via Box Embedding
Wei Xue, Yongliang Shen, Wenqi Ren, Jietian Guo, Shiliang Pu, Weiming Lu
Taxonomy completion, enriching existing taxonomies by inserting new concepts as parents or attaching them as children, has gained significant interest. Previous approaches embed concepts as vectors in Euclidean space, which makes it difficult to model asymmetric relations in taxonomy. In addition, they introduce pseudo-leaves to convert attachment cases into insertion cases, leading to an incorrect bias in network learning dominated by numerous pseudo-leaves. Addressing these, our framework, TaxBox, leverages box containment and center closeness to design two specialized geometric scorers within the box embedding space. These scorers are tailored for insertion and attachment operations and can effectively capture intrinsic relationships between concepts by optimizing on a granular box constraint loss. We employ a dynamic ranking loss mechanism to balance the scores from these scorers, allowing adaptive adjustments of insertion and attachment scores. Experiments on four real-world datasets show that TaxBox significantly outperforms previous methods, yielding substantial improvements over prior methods in real-world datasets, with average performance boosts of 6.7%, 34.9%, and 51.4% in MRR, Hit@1, and Prec@1, respectively.
Read more6/19/2024
0
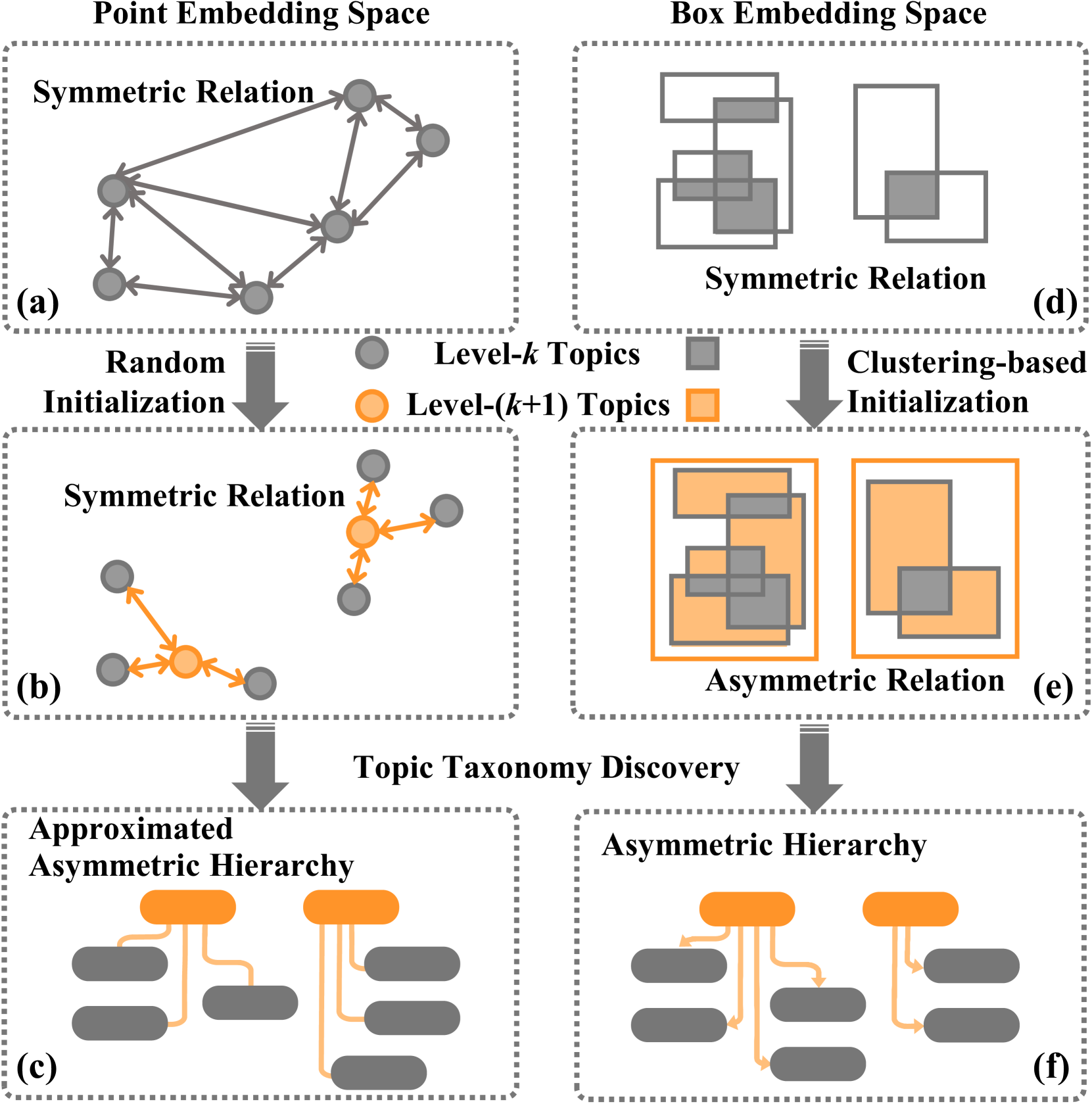
Self-supervised Topic Taxonomy Discovery in the Box Embedding Space
Yuyin Lu, Hegang Chen, Pengbo Mao, Yanghui Rao, Haoran Xie, Fu Lee Wang, Qing Li
Topic taxonomy discovery aims at uncovering topics of different abstraction levels and constructing hierarchical relations between them. Unfortunately, most of prior work can hardly model semantic scopes of words and topics by holding the Euclidean embedding space assumption. What's worse, they infer asymmetric hierarchical relations by symmetric distances between topic embeddings. As a result, existing methods suffer from problems of low-quality topics at high abstraction levels and inaccurate hierarchical relations. To alleviate these problems, this paper develops a Box embedding-based Topic Model (BoxTM) that maps words and topics into the box embedding space, where the asymmetric metric is defined to properly infer hierarchical relations among topics. Additionally, our BoxTM explicitly infers upper-level topics based on correlation between specific topics through recursive clustering on topic boxes. Finally, extensive experiments validate high-quality of the topic taxonomy learned by BoxTM.
Read more8/28/2024

0
CodeTaxo: Enhancing Taxonomy Expansion with Limited Examples via Code Language Prompts
Qingkai Zeng, Yuyang Bai, Zhaoxuan Tan, Zhenyu Wu, Shangbin Feng, Meng Jiang
Taxonomies play a crucial role in various applications by providing a structural representation of knowledge. The task of taxonomy expansion involves integrating emerging concepts into existing taxonomies by identifying appropriate parent concepts for these new query concepts. Previous approaches typically relied on self-supervised methods that generate annotation data from existing taxonomies. However, these methods are less effective when the existing taxonomy is small (fewer than 100 entities). In this work, we introduce textsc{CodeTaxo}, a novel approach that leverages large language models through code language prompts to capture the taxonomic structure. Extensive experiments on five real-world benchmarks from different domains demonstrate that textsc{CodeTaxo} consistently achieves superior performance across all evaluation metrics, significantly outperforming previous state-of-the-art methods. The code and data are available at url{https://github.com/QingkaiZeng/CodeTaxo-Pub}.
Read more8/20/2024
0
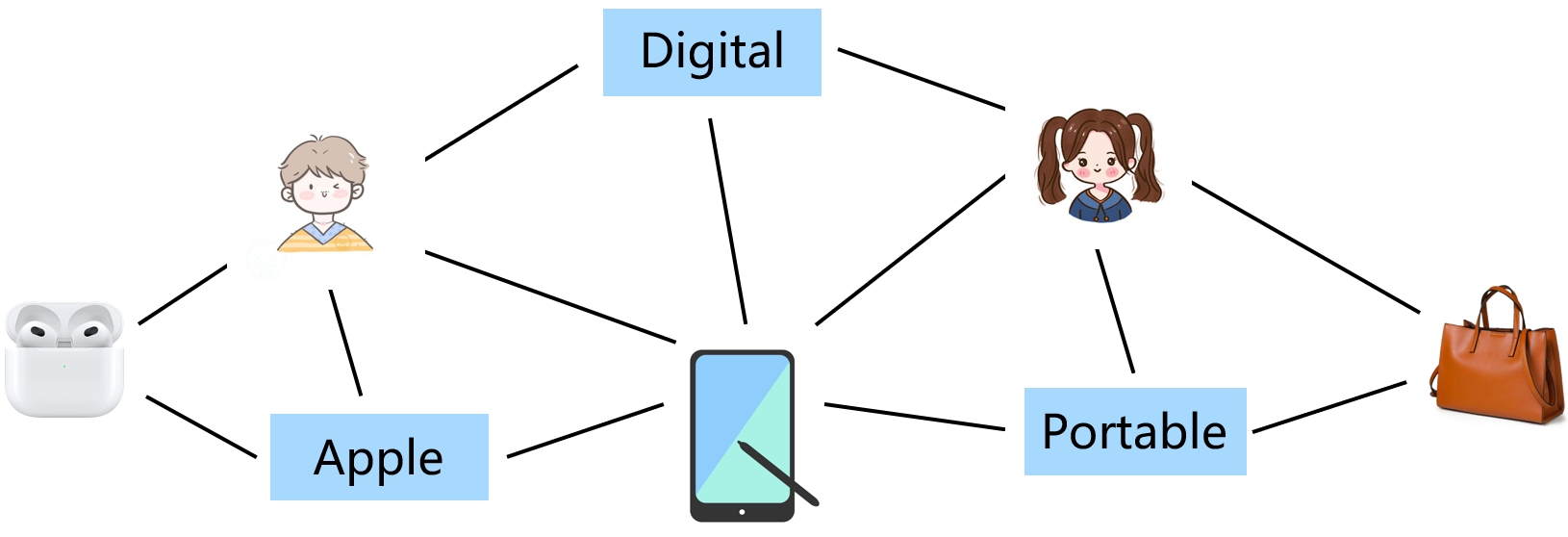
When Box Meets Graph Neural Network in Tag-aware Recommendation
Fake Lin, Ziwei Zhao, Xi Zhu, Da Zhang, Shitian Shen, Xueying Li, Tong Xu, Suojuan Zhang, Enhong Chen
Last year has witnessed the re-flourishment of tag-aware recommender systems supported by the LLM-enriched tags. Unfortunately, though large efforts have been made, current solutions may fail to describe the diversity and uncertainty inherent in user preferences with only tag-driven profiles. Recently, with the development of geometry-based techniques, e.g., box embedding, diversity of user preferences now could be fully modeled as the range within a box in high dimension space. However, defect still exists as these approaches are incapable of capturing high-order neighbor signals, i.e., semantic-rich multi-hop relations within the user-tag-item tripartite graph, which severely limits the effectiveness of user modeling. To deal with this challenge, in this paper, we propose a novel algorithm, called BoxGNN, to perform the message aggregation via combination of logical operations, thereby incorporating high-order signals. Specifically, we first embed users, items, and tags as hyper-boxes rather than simple points in the representation space, and define two logical operations to facilitate the subsequent process. Next, we perform the message aggregation mechanism via the combination of logical operations, to obtain the corresponding high-order box representations. Finally, we adopt a volume-based learning objective with Gumbel smoothing techniques to refine the representation of boxes. Extensive experiments on two publicly available datasets and one LLM-enhanced e-commerce dataset have validated the superiority of BoxGNN compared with various state-of-the-art baselines. The code is released online
Read more6/19/2024