Self-Supervised Video Representation Learning in a Heuristic Decoupled Perspective

0
Sign in to get full access
Overview
- This paper proposes a self-supervised video representation learning method that decouples the learning of static and dynamic representations.
- The method aims to learn robust and transferable video representations without using any labeled data.
- It introduces a heuristic decoupling approach that separates the learning of static and dynamic features through a series of self-supervised pretext tasks.
Plain English Explanation
The paper introduces a new way to train artificial intelligence (AI) systems to understand and represent video data without using labeled examples. This is important because collecting and labeling large datasets of videos can be time-consuming and expensive.
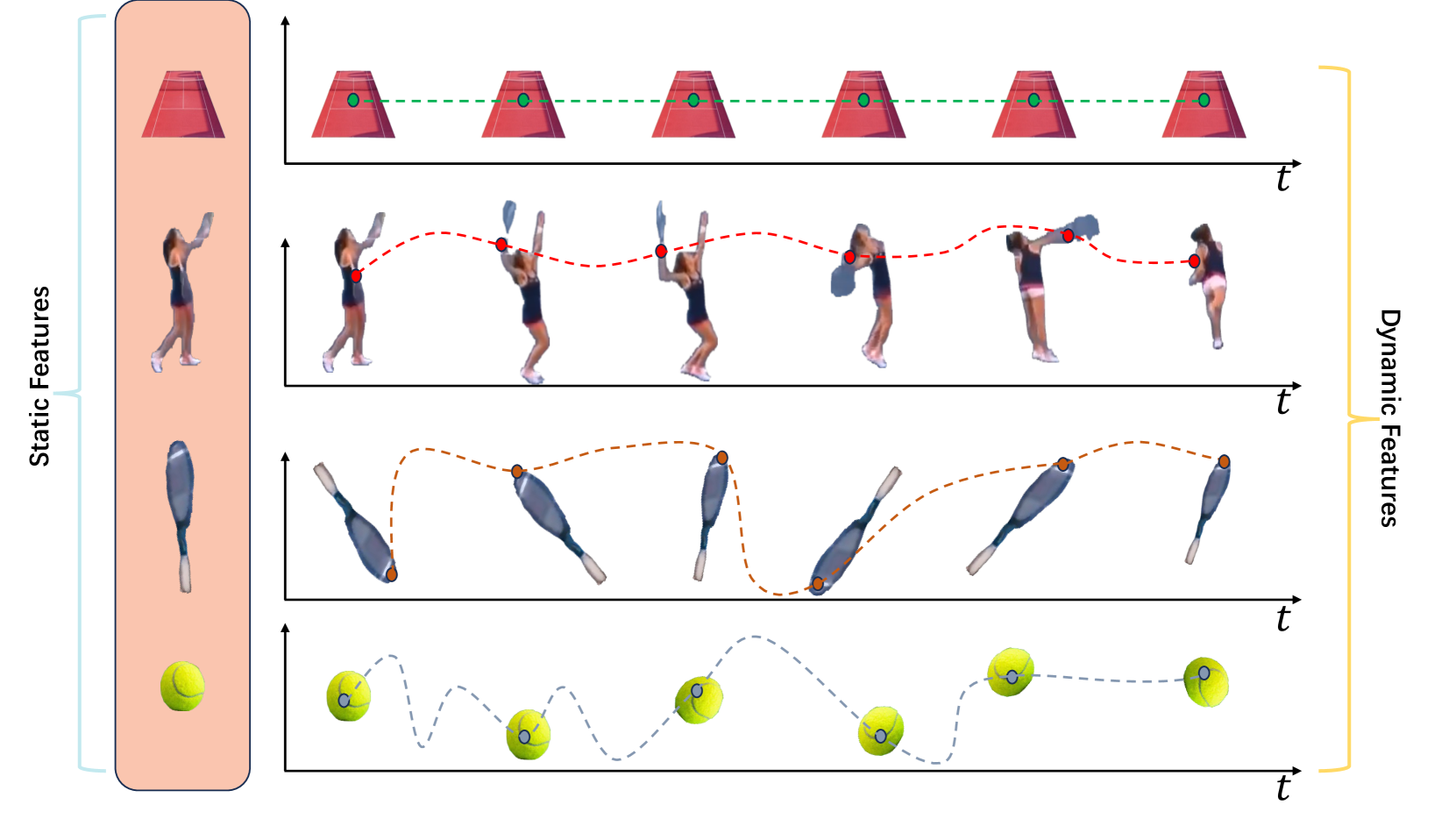
The key idea is to decouple the learning of static and dynamic representations in the video. Static representations capture the content and objects in the video, while dynamic representations capture the motion and changes over time.
The method does this through a series of self-supervised pretext tasks, which means the AI system learns to solve related problems in the video data itself, without any human-provided labels. For example, one task might be predicting the next frame in the video sequence, while another task could be identifying which frames were played in the correct order.
By separating the learning of static and dynamic features, the method aims to learn more robust and transferable video representations. This means the learned representations can be useful for a variety of downstream tasks, like video classification or action recognition, without needing to retrain the entire system from scratch.
Technical Explanation
The paper proposes a self-supervised video representation learning method that decouples the learning of static and dynamic representations. The key technical components are:
-
Heuristic Decoupling: The method introduces a series of self-supervised pretext tasks that are designed to encourage the learning of static and dynamic representations separately. For example, one task might be predicting the next frame in a video sequence (to learn dynamic representations), while another task could be identifying whether a sequence of frames was played in the correct order (to learn static representations).
-
Architecture Design: The model architecture consists of a shared backbone encoder that processes the video frames, along with separate prediction heads for the static and dynamic pretext tasks. This allows the model to learn distinct representations for the two types of features.
-
Multitask Training: The model is trained on all the pretext tasks simultaneously, with the goal of optimizing the performance on each task. This encourages the learning of robust and transferable video representations that can be useful for a variety of downstream applications.
The experiments show that this decoupled approach outperforms other self-supervised video representation learning methods on standard benchmarks for action recognition and video classification. The authors attribute this to the model's ability to learn more disentangled and informative representations by separating the static and dynamic aspects of the video.
Critical Analysis
The paper presents a thoughtful and well-designed approach to self-supervised video representation learning. The key strength of the method is the decoupling of static and dynamic representations, which aligns well with our understanding of how humans perceive and process video information.
However, the paper does not address some potential limitations and areas for further research:
-
Task Selection: The choice of pretext tasks and their specific formulation can have a significant impact on the learned representations. The paper does not provide a detailed analysis of how different task designs might affect the results.
-
Computational Complexity: Training the model on multiple pretext tasks simultaneously can be computationally expensive, especially for large-scale video datasets. The paper does not discuss the training efficiency or scalability of the approach.
-
Generalization to Diverse Video Data: The experiments focus on relatively constrained video datasets, such as action recognition benchmarks. It's unclear how well the method would generalize to more diverse and unconstrained video data, which is often the case in real-world applications.
-
Interpretability: The paper does not provide much insight into how the static and dynamic representations are actually learned and disentangled by the model. A more interpretable approach could lead to better understanding and potentially further improvements.
Overall, the paper presents a promising direction for self-supervised video representation learning, but further research is needed to address these potential limitations and explore the broader applicability of the method.
Conclusion
This paper introduces a novel self-supervised video representation learning method that decouples the learning of static and dynamic representations. By designing a series of pretext tasks that encourage the model to learn these distinct types of features, the approach is able to produce robust and transferable video representations that outperform other self-supervised methods on standard benchmarks.
While the paper demonstrates the effectiveness of this approach, it also highlights areas for further research, such as task selection, computational efficiency, generalization, and interpretability. Addressing these challenges could lead to even more powerful and versatile video understanding systems that can be deployed in a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-Supervised Video Representation Learning in a Heuristic Decoupled Perspective
Zeen Song, Jingyao Wang, Jianqi Zhang, Changwen Zheng, Wenwen Qiang
Video contrastive learning (v-CL) has gained prominence as a leading framework for unsupervised video representation learning, showcasing impressive performance across various tasks such as action classification and detection. In the field of video representation learning, a feature extractor should ideally capture both static and dynamic semantics. However, our series of experiments reveals that existing v-CL methods predominantly capture static semantics, with limited capturing of dynamic semantics. Through causal analysis, we identify the root cause: the v-CL objective lacks explicit modeling of dynamic features and the measurement of dynamic similarity is confounded by static semantics, while the measurement of static similarity is confounded by dynamic semantics. In response, we propose Bi-level Optimization of Learning Dynamic with Decoupling and Intervention (BOLD-DI) to capture both static and dynamic semantics in a decoupled manner. Our method can be seamlessly integrated into the existing v-CL methods and experimental results highlight the significant improvements.
Read more7/22/2024

0
Dynamic in Static: Hybrid Visual Correspondence for Self-Supervised Video Object Segmentation
Gensheng Pei, Yazhou Yao, Jianbo Jiao, Wenguan Wang, Liqiang Nie, Jinhui Tang
Conventional video object segmentation (VOS) methods usually necessitate a substantial volume of pixel-level annotated video data for fully supervised learning. In this paper, we present HVC, a textbf{h}ybrid static-dynamic textbf{v}isual textbf{c}orrespondence framework for self-supervised VOS. HVC extracts pseudo-dynamic signals from static images, enabling an efficient and scalable VOS model. Our approach utilizes a minimalist fully-convolutional architecture to capture static-dynamic visual correspondence in image-cropped views. To achieve this objective, we present a unified self-supervised approach to learn visual representations of static-dynamic feature similarity. Firstly, we establish static correspondence by utilizing a priori coordinate information between cropped views to guide the formation of consistent static feature representations. Subsequently, we devise a concise convolutional layer to capture the forward / backward pseudo-dynamic signals between two views, serving as cues for dynamic representations. Finally, we propose a hybrid visual correspondence loss to learn joint static and dynamic consistency representations. Our approach, without bells and whistles, necessitates only one training session using static image data, significantly reducing memory consumption ($sim$16GB) and training time ($sim$textbf{2h}). Moreover, HVC achieves state-of-the-art performance in several self-supervised VOS benchmarks and additional video label propagation tasks.
Read more4/23/2024

0
Self-Supervised Contrastive Learning for Videos using Differentiable Local Alignment
Keyne Oei, Amr Gomaa, Anna Maria Feit, Jo~ao Belo
Robust frame-wise embeddings are essential to perform video analysis and understanding tasks. We present a self-supervised method for representation learning based on aligning temporal video sequences. Our framework uses a transformer-based encoder to extract frame-level features and leverages them to find the optimal alignment path between video sequences. We introduce the novel Local-Alignment Contrastive (LAC) loss, which combines a differentiable local alignment loss to capture local temporal dependencies with a contrastive loss to enhance discriminative learning. Prior works on video alignment have focused on using global temporal ordering across sequence pairs, whereas our loss encourages identifying the best-scoring subsequence alignment. LAC uses the differentiable Smith-Waterman (SW) affine method, which features a flexible parameterization learned through the training phase, enabling the model to adjust the temporal gap penalty length dynamically. Evaluations show that our learned representations outperform existing state-of-the-art approaches on action recognition tasks.
Read more9/10/2024
🤷
0
Unsupervised Open-Vocabulary Object Localization in Videos
Ke Fan, Zechen Bai, Tianjun Xiao, Dominik Zietlow, Max Horn, Zixu Zhao, Carl-Johann Simon-Gabriel, Mike Zheng Shou, Francesco Locatello, Bernt Schiele, Thomas Brox, Zheng Zhang, Yanwei Fu, Tong He
In this paper, we show that recent advances in video representation learning and pre-trained vision-language models allow for substantial improvements in self-supervised video object localization. We propose a method that first localizes objects in videos via an object-centric approach with slot attention and then assigns text to the obtained slots. The latter is achieved by an unsupervised way to read localized semantic information from the pre-trained CLIP model. The resulting video object localization is entirely unsupervised apart from the implicit annotation contained in CLIP, and it is effectively the first unsupervised approach that yields good results on regular video benchmarks.
Read more6/27/2024