Dynamic in Static: Hybrid Visual Correspondence for Self-Supervised Video Object Segmentation

0

Sign in to get full access
Overview
- This paper proposes a hybrid visual correspondence method for self-supervised video object segmentation.
- The approach leverages both static and dynamic visual cues to learn robust object representations.
- The method achieves state-of-the-art performance on several video object segmentation benchmarks.
Plain English Explanation
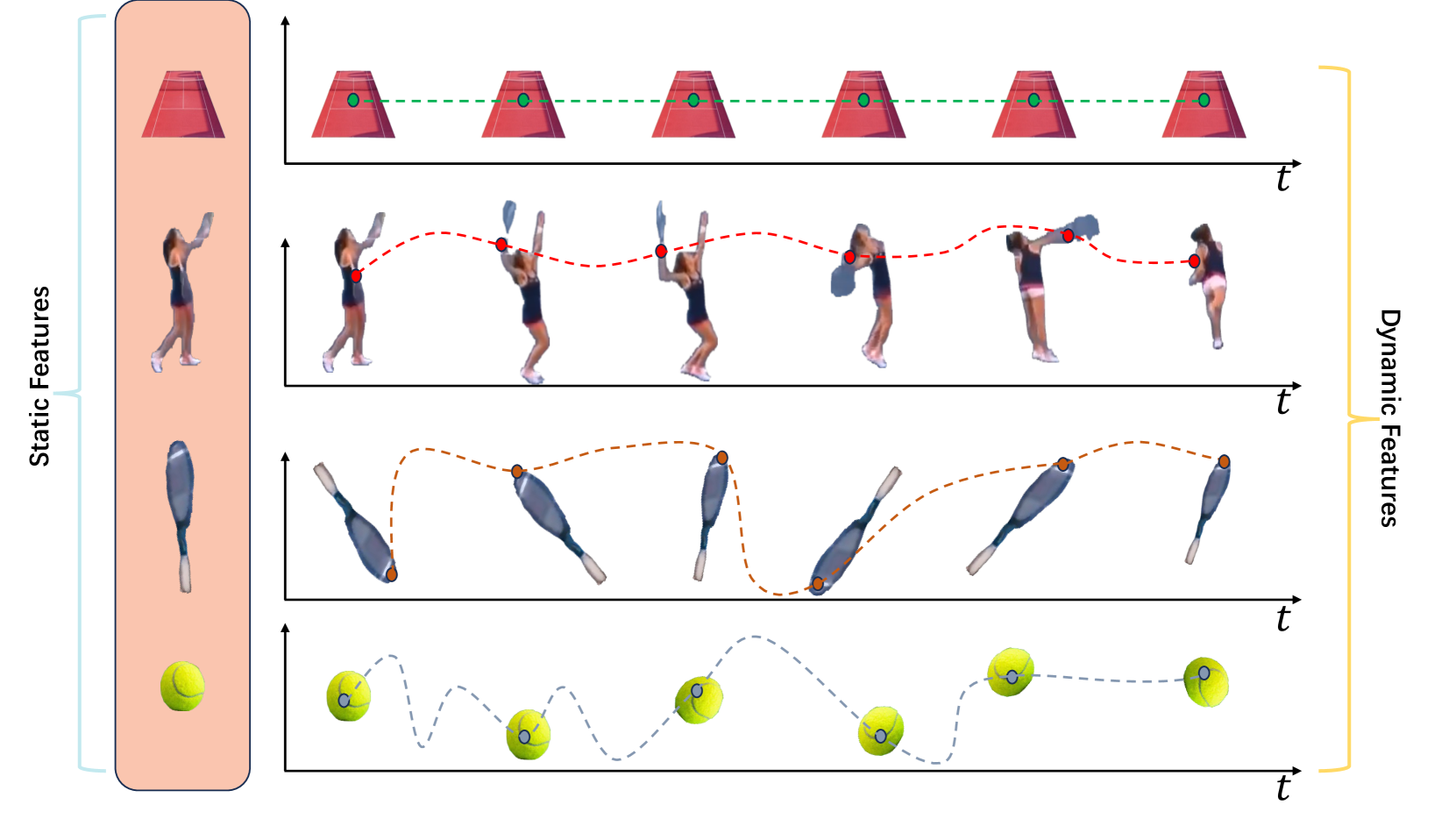
The paper describes a new way to automatically identify and track objects in video. Traditionally, video object segmentation has relied on either static visual features (like shape and color) or dynamic features (like movement and motion). However, this paper suggests that using a combination of both static and dynamic visual information can lead to better object tracking.
The key idea is to learn visual representations that capture both the static and dynamic aspects of objects in video. This "hybrid" approach allows the model to learn richer and more robust object representations, which in turn improves its ability to accurately segment and track objects over time.
The authors demonstrate that their method outperforms existing self-supervised video object segmentation techniques on several benchmark datasets. This suggests that incorporating both static and dynamic visual cues can be a powerful way to enable machines to better understand and interact with the visual world around them.
Technical Explanation
The paper introduces a new self-supervised video object segmentation framework that learns visual representations by exploiting both static and dynamic cues.
The core of the approach is a hybrid visual correspondence module that matches features across video frames in a way that captures both the spatial-semantic and temporal-motion relationships between objects. This allows the model to learn rich object representations that encode both their static appearance and dynamic movement patterns.
The authors also propose a differentiable segmentation head that can be trained end-to-end with the correspondence module, enabling the entire system to be optimized for the video object segmentation task in a self-supervised manner.
Experiments on standard benchmarks show that this hybrid static-dynamic representation learning approach outperforms previous self-supervised video object segmentation methods by a significant margin.
Critical Analysis
The paper presents a compelling approach to self-supervised video object segmentation, demonstrating the value of jointly leveraging static and dynamic visual cues. However, the authors acknowledge several limitations and potential areas for further research.
One key caveat is that the method relies on dense optical flow computations, which can be computationally expensive and may limit its applicability in real-time or resource-constrained settings. Exploring more efficient flow estimation techniques or alternative motion representations could help address this issue.
Additionally, while the approach shows strong performance on existing benchmarks, its generalization to more diverse and challenging video datasets remains an open question. Further evaluations on a wider range of video scenarios would help validate the robustness and broader applicability of the proposed framework.
Finally, the paper does not provide a deep analysis of failure cases or edge cases where the method might break down. Investigating such limitations could uncover important insights and inspire future research directions to further improve video object segmentation capabilities.
Conclusion
This paper presents a novel self-supervised video object segmentation method that leverages a hybrid visual correspondence approach to learn robust object representations from both static and dynamic visual cues. The experiments demonstrate state-of-the-art performance on several benchmarks, suggesting that this "dynamic in static" representation learning strategy can be a powerful tool for enabling machines to better understand and track objects in complex video data.
While the proposed framework has some limitations, the core idea of combining static and dynamic visual information to enable more comprehensive object understanding is an important contribution to the field of video perception and analysis. Future work building on these insights could lead to further advancements in self-supervised video understanding and its practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dynamic in Static: Hybrid Visual Correspondence for Self-Supervised Video Object Segmentation
Gensheng Pei, Yazhou Yao, Jianbo Jiao, Wenguan Wang, Liqiang Nie, Jinhui Tang
Conventional video object segmentation (VOS) methods usually necessitate a substantial volume of pixel-level annotated video data for fully supervised learning. In this paper, we present HVC, a textbf{h}ybrid static-dynamic textbf{v}isual textbf{c}orrespondence framework for self-supervised VOS. HVC extracts pseudo-dynamic signals from static images, enabling an efficient and scalable VOS model. Our approach utilizes a minimalist fully-convolutional architecture to capture static-dynamic visual correspondence in image-cropped views. To achieve this objective, we present a unified self-supervised approach to learn visual representations of static-dynamic feature similarity. Firstly, we establish static correspondence by utilizing a priori coordinate information between cropped views to guide the formation of consistent static feature representations. Subsequently, we devise a concise convolutional layer to capture the forward / backward pseudo-dynamic signals between two views, serving as cues for dynamic representations. Finally, we propose a hybrid visual correspondence loss to learn joint static and dynamic consistency representations. Our approach, without bells and whistles, necessitates only one training session using static image data, significantly reducing memory consumption ($sim$16GB) and training time ($sim$textbf{2h}). Moreover, HVC achieves state-of-the-art performance in several self-supervised VOS benchmarks and additional video label propagation tasks.
Read more4/23/2024
0
Self-Supervised Video Representation Learning in a Heuristic Decoupled Perspective
Zeen Song, Jingyao Wang, Jianqi Zhang, Changwen Zheng, Wenwen Qiang
Video contrastive learning (v-CL) has gained prominence as a leading framework for unsupervised video representation learning, showcasing impressive performance across various tasks such as action classification and detection. In the field of video representation learning, a feature extractor should ideally capture both static and dynamic semantics. However, our series of experiments reveals that existing v-CL methods predominantly capture static semantics, with limited capturing of dynamic semantics. Through causal analysis, we identify the root cause: the v-CL objective lacks explicit modeling of dynamic features and the measurement of dynamic similarity is confounded by static semantics, while the measurement of static similarity is confounded by dynamic semantics. In response, we propose Bi-level Optimization of Learning Dynamic with Decoupling and Intervention (BOLD-DI) to capture both static and dynamic semantics in a decoupled manner. Our method can be seamlessly integrated into the existing v-CL methods and experimental results highlight the significant improvements.
Read more7/22/2024
🧪
0
Decoupling Dynamic Monocular Videos for Dynamic View Synthesis
Meng You, Junhui Hou
The challenge of dynamic view synthesis from dynamic monocular videos, i.e., synthesizing novel views for free viewpoints given a monocular video of a dynamic scene captured by a moving camera, mainly lies in accurately modeling the textbf{dynamic objects} of a scene using limited 2D frames, each with a varying timestamp and viewpoint. Existing methods usually require pre-processed 2D optical flow and depth maps by off-the-shelf methods to supervise the network, making them suffer from the inaccuracy of the pre-processed supervision and the ambiguity when lifting the 2D information to 3D. In this paper, we tackle this challenge in an unsupervised fashion. Specifically, we decouple the motion of the dynamic objects into object motion and camera motion, respectively regularized by proposed unsupervised surface consistency and patch-based multi-view constraints. The former enforces the 3D geometric surfaces of moving objects to be consistent over time, while the latter regularizes their appearances to be consistent across different viewpoints. Such a fine-grained motion formulation can alleviate the learning difficulty for the network, thus enabling it to produce not only novel views with higher quality but also more accurate scene flows and depth than existing methods requiring extra supervision.
Read more8/22/2024

0
DVOS: Self-Supervised Dense-Pattern Video Object Segmentation
Keyhan Najafian, Farhad Maleki, Ian Stavness, Lingling Jin
Video object segmentation approaches primarily rely on large-scale pixel-accurate human-annotated datasets for model development. In Dense Video Object Segmentation (DVOS) scenarios, each video frame encompasses hundreds of small, dense, and partially occluded objects. Accordingly, the labor-intensive manual annotation of even a single frame often takes hours, which hinders the development of DVOS for many applications. Furthermore, in videos with dense patterns, following a large number of objects that move in different directions poses additional challenges. To address these challenges, we proposed a semi-self-supervised spatiotemporal approach for DVOS utilizing a diffusion-based method through multi-task learning. Emulating real videos' optical flow and simulating their motion, we developed a methodology to synthesize computationally annotated videos that can be used for training DVOS models; The model performance was further improved by utilizing weakly labeled (computationally generated but imprecise) data. To demonstrate the utility and efficacy of the proposed approach, we developed DVOS models for wheat head segmentation of handheld and drone-captured videos, capturing wheat crops in fields of different locations across various growth stages, spanning from heading to maturity. Despite using only a few manually annotated video frames, the proposed approach yielded high-performing models, achieving a Dice score of 0.82 when tested on a drone-captured external test set. While we showed the efficacy of the proposed approach for wheat head segmentation, its application can be extended to other crops or DVOS in other domains, such as crowd analysis or microscopic image analysis.
Read more6/10/2024