Self-Supervised Vision Transformer for Enhanced Virtual Clothes Try-On
2406.10539
0
0

Abstract
Virtual clothes try-on has emerged as a vital feature in online shopping, offering consumers a critical tool to visualize how clothing fits. In our research, we introduce an innovative approach for virtual clothes try-on, utilizing a self-supervised Vision Transformer (ViT) coupled with a diffusion model. Our method emphasizes detail enhancement by contrasting local clothing image embeddings, generated by ViT, with their global counterparts. Techniques such as conditional guidance and focus on key regions have been integrated into our approach. These combined strategies empower the diffusion model to reproduce clothing details with increased clarity and realism. The experimental results showcase substantial advancements in the realism and precision of details in virtual try-on experiences, significantly surpassing the capabilities of existing technologies.
Create account to get full access
Overview
- This paper presents a self-supervised Vision Transformer model for enhanced virtual clothes try-on.
- The model leverages self-supervised learning to extract robust visual representations, enabling high-quality virtual clothes try-on without requiring extensive paired training data.
- The approach outperforms previous state-of-the-art virtual try-on methods on several benchmark datasets.
Plain English Explanation
The paper introduces a new artificial intelligence (AI) system that allows people to virtually try on clothes without needing a lot of training data. Traditionally, virtual try-on systems have required large datasets of people wearing different outfits, which can be expensive and time-consuming to collect.
This new system instead uses a technique called "self-supervised learning" to teach the AI model how to understand clothing and the human body without relying on those extensive datasets. The model can then use that knowledge to realistically superimpose clothes onto a person's image, allowing them to virtually try on new outfits.
Compared to previous virtual try-on methods, this self-supervised approach produces higher-quality results and requires less training data. This makes it more practical for real-world applications, like online shopping, where virtual try-on features can help customers make more informed purchasing decisions.
Technical Explanation
The key innovation of this work is the use of a self-supervised Vision Transformer (ViT) architecture for virtual clothes try-on. The ViT model is pre-trained on a large corpus of unlabeled images using self-supervised learning techniques. This allows the model to learn rich visual representations without the need for expensive, manually annotated datasets.
During the virtual try-on task, the self-supervised ViT extracts a detailed understanding of the human body and clothing from the input image. It then leverages this knowledge to seamlessly integrate a new clothing item onto the person's figure, producing a realistic composite image.
The authors evaluate their self-supervised ViT approach on several benchmark datasets for virtual clothes try-on, including VIVID, VTON-IT, and MVVT. They demonstrate significant improvements over previous state-of-the-art methods, both in terms of visual quality and the amount of training data required.
Critical Analysis
The paper presents a compelling approach to virtual clothes try-on, leveraging self-supervised learning to reduce the need for large, manually annotated datasets. This is an important advancement, as the lack of high-quality training data has been a major bottleneck for developing practical virtual try-on systems.
However, the authors do acknowledge certain limitations of their method. For example, the ViT model may struggle with complex clothing items or unusual body shapes that are not well-represented in the pre-training data. Additionally, the paper does not explore the model's performance on more diverse datasets that include a broader range of body types and clothing styles.
Further research could investigate ways to make the self-supervised ViT even more robust and generalizable, perhaps by incorporating additional self-supervised tasks or adapting the architecture to handle a wider range of real-world scenarios. Integrating this approach with other recent advances in novel garment transfer and multi-view virtual try-on could also lead to further improvements in virtual clothes try-on capabilities.
Conclusion
This paper presents a novel self-supervised Vision Transformer model for enhanced virtual clothes try-on. By leveraging self-supervised learning, the model can extract robust visual representations without relying on extensive, manually annotated datasets. This makes the system more practical for real-world applications, where the ability to realistically superimpose clothing onto a person's image can greatly improve the online shopping experience.
The authors demonstrate the effectiveness of their approach on several benchmark datasets, outperforming previous state-of-the-art virtual try-on methods. While the model has some limitations, this work represents an important step forward in the development of more accessible and user-friendly virtual try-on technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
ViViD: Video Virtual Try-on using Diffusion Models
Zixun Fang, Wei Zhai, Aimin Su, Hongliang Song, Kai Zhu, Mao Wang, Yu Chen, Zhiheng Liu, Yang Cao, Zheng-Jun Zha
0
0
Video virtual try-on aims to transfer a clothing item onto the video of a target person. Directly applying the technique of image-based try-on to the video domain in a frame-wise manner will cause temporal-inconsistent outcomes while previous video-based try-on solutions can only generate low visual quality and blurring results. In this work, we present ViViD, a novel framework employing powerful diffusion models to tackle the task of video virtual try-on. Specifically, we design the Garment Encoder to extract fine-grained clothing semantic features, guiding the model to capture garment details and inject them into the target video through the proposed attention feature fusion mechanism. To ensure spatial-temporal consistency, we introduce a lightweight Pose Encoder to encode pose signals, enabling the model to learn the interactions between clothing and human posture and insert hierarchical Temporal Modules into the text-to-image stable diffusion model for more coherent and lifelike video synthesis. Furthermore, we collect a new dataset, which is the largest, with the most diverse types of garments and the highest resolution for the task of video virtual try-on to date. Extensive experiments demonstrate that our approach is able to yield satisfactory video try-on results. The dataset, codes, and weights will be publicly available. Project page: https://becauseimbatman0.github.io/ViViD.
5/29/2024
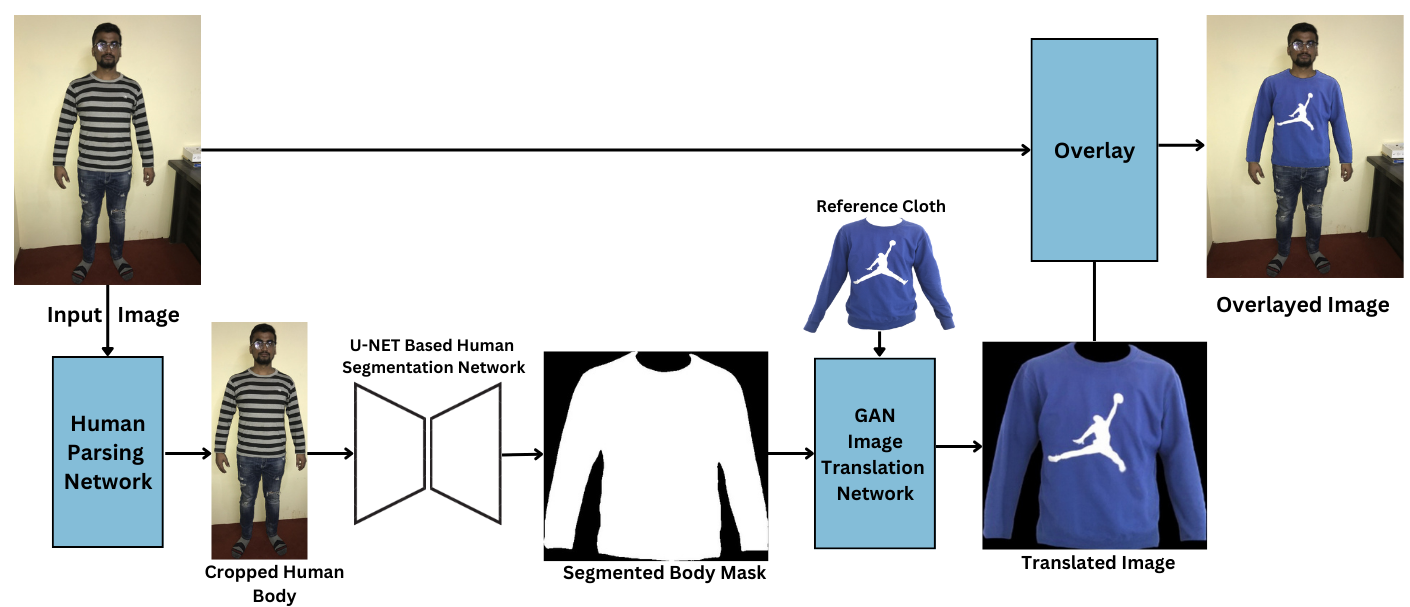
VTON-IT: Virtual Try-On using Image Translation
Santosh Adhikari, Bishnu Bhusal, Prashant Ghimire, Anil Shrestha
0
0
Virtual Try-On (trying clothes virtually) is a promising application of the Generative Adversarial Network (GAN). However, it is an arduous task to transfer the desired clothing item onto the corresponding regions of a human body because of varying body size, pose, and occlusions like hair and overlapped clothes. In this paper, we try to produce photo-realistic translated images through semantic segmentation and a generative adversarial architecture-based image translation network. We present a novel image-based Virtual Try-On application VTON-IT that takes an RGB image, segments desired body part, and overlays target cloth over the segmented body region. Most state-of-the-art GAN-based Virtual Try-On applications produce unaligned pixelated synthesis images on real-life test images. However, our approach generates high-resolution natural images with detailed textures on such variant images.
5/8/2024
📉
Image-Based Virtual Try-On: A Survey
Dan Song, Xuanpu Zhang, Juan Zhou, Weizhi Nie, Ruofeng Tong, Mohan Kankanhalli, An-An Liu
0
0
Image-based virtual try-on aims to synthesize a naturally dressed person image with a clothing image, which revolutionizes online shopping and inspires related topics within image generation, showing both research significance and commercial potential. However, there is a gap between current research progress and commercial applications and an absence of comprehensive overview of this field to accelerate the development. In this survey, we provide a comprehensive analysis of the state-of-the-art techniques and methodologies in aspects of pipeline architecture, person representation and key modules such as try-on indication, clothing warping and try-on stage. We propose a new semantic criteria with CLIP, and evaluate representative methods with uniformly implemented evaluation metrics on the same dataset. In addition to quantitative and qualitative evaluation of current open-source methods, unresolved issues are highlighted and future research directions are prospected to identify key trends and inspire further exploration. The uniformly implemented evaluation metrics, dataset and collected methods will be made public available at https://github.com/little-misfit/Survey-Of-Virtual-Try-On.
5/2/2024
🏅
MV-VTON: Multi-View Virtual Try-On with Diffusion Models
Haoyu Wang, Zhilu Zhang, Donglin Di, Shiliang Zhang, Wangmeng Zuo
0
0
The goal of image-based virtual try-on is to generate an image of the target person naturally wearing the given clothing. However, most existing methods solely focus on the frontal try-on using the frontal clothing. When the views of the clothing and person are significantly inconsistent, particularly when the person's view is non-frontal, the results are unsatisfactory. To address this challenge, we introduce Multi-View Virtual Try-ON (MV-VTON), which aims to reconstruct the dressing results of a person from multiple views using the given clothes. On the one hand, given that single-view clothes provide insufficient information for MV-VTON, we instead employ two images, i.e., the frontal and back views of the clothing, to encompass the complete view as much as possible. On the other hand, the diffusion models that have demonstrated superior abilities are adopted to perform our MV-VTON. In particular, we propose a view-adaptive selection method where hard-selection and soft-selection are applied to the global and local clothing feature extraction, respectively. This ensures that the clothing features are roughly fit to the person's view. Subsequently, we suggest a joint attention block to align and fuse clothing features with person features. Additionally, we collect a MV-VTON dataset, i.e., Multi-View Garment (MVG), in which each person has multiple photos with diverse views and poses. Experiments show that the proposed method not only achieves state-of-the-art results on MV-VTON task using our MVG dataset, but also has superiority on frontal-view virtual try-on task using VITON-HD and DressCode datasets. Codes and datasets will be publicly released at https://github.com/hywang2002/MV-VTON .
4/30/2024