Image-Based Virtual Try-On: A Survey
2311.04811
0
0
📉
Abstract
Image-based virtual try-on aims to synthesize a naturally dressed person image with a clothing image, which revolutionizes online shopping and inspires related topics within image generation, showing both research significance and commercial potential. However, there is a gap between current research progress and commercial applications and an absence of comprehensive overview of this field to accelerate the development. In this survey, we provide a comprehensive analysis of the state-of-the-art techniques and methodologies in aspects of pipeline architecture, person representation and key modules such as try-on indication, clothing warping and try-on stage. We propose a new semantic criteria with CLIP, and evaluate representative methods with uniformly implemented evaluation metrics on the same dataset. In addition to quantitative and qualitative evaluation of current open-source methods, unresolved issues are highlighted and future research directions are prospected to identify key trends and inspire further exploration. The uniformly implemented evaluation metrics, dataset and collected methods will be made public available at https://github.com/little-misfit/Survey-Of-Virtual-Try-On.
Create account to get full access
Overview
- This paper provides a comprehensive analysis of the state-of-the-art techniques and methodologies in image-based virtual try-on, which aims to synthesize a naturally dressed person image with a clothing image.
- The paper highlights the research significance and commercial potential of virtual try-on, while also identifying the gap between current research progress and commercial applications.
- The authors propose a new semantic criteria with CLIP and evaluate representative methods with uniformly implemented evaluation metrics on the same dataset.
- The paper also highlights unresolved issues and future research directions to identify key trends and inspire further exploration in this field.
Plain English Explanation
Image-based virtual try-on is a technology that allows you to see what clothes would look like on you, without actually trying them on. This can revolutionize online shopping, as it helps customers visualize how items would fit and look on them before making a purchase.
The research in this area is significant, as it has the potential to improve the online shopping experience and drive new innovations in areas like image generation. However, there is still a gap between the current research progress and what is actually being used in commercial applications.
To help address this gap, the authors of this paper have done a comprehensive analysis of the latest techniques and methods being used in virtual try-on. They've proposed a new way to evaluate these methods, using a tool called CLIP, and have evaluated several representative methods using the same dataset and metrics.
The paper also highlights some of the unresolved issues and suggests future research directions. This can help guide researchers and developers in this field to focus on the key challenges and opportunities.
Overall, this paper provides a valuable overview of the state of the art in image-based virtual try-on, and can help accelerate the development and adoption of this technology.
Technical Explanation
The paper begins by outlining the importance of image-based virtual try-on, which allows customers to see how clothing would look on them before making a purchase. This has significant research significance, as it involves advancements in image generation, and also has substantial commercial potential.
To provide a comprehensive analysis of the current state-of-the-art, the authors examine various aspects of the virtual try-on pipeline, including person representation, try-on indication, clothing warping, and the overall try-on stage. They propose a new semantic criteria using the CLIP model, and evaluate several representative methods using uniformly implemented evaluation metrics on the same dataset.
The paper not only provides quantitative and qualitative evaluations of current open-source methods, but also highlights unresolved issues and future research directions. This includes exploring novel garment transfer methods and excavating spatial-temporal tunnels for improved virtual try-on experiences.
Critical Analysis
The paper provides a thorough and well-structured analysis of the current state-of-the-art in image-based virtual try-on. The authors' use of a unified evaluation framework and the proposal of a new semantic criteria are particularly noteworthy, as they can help drive more consistent and meaningful comparisons between different methods.
However, the paper does acknowledge some limitations of the current research, such as the gap between research progress and commercial applications. This suggests that there may be practical challenges or constraints that are not fully addressed by the academic work in this field.
Additionally, while the paper highlights several future research directions, it would be helpful to see a more in-depth discussion of the potential barriers or obstacles that may need to be overcome to realize these advancements. For example, the technical complexity of excavating spatial-temporal tunnels for improved virtual try-on could be a significant challenge.
Overall, the paper provides a valuable contribution to the field of image-based virtual try-on, but further work may be needed to bridge the gap between research and practical deployment.
Conclusion
This paper offers a comprehensive overview of the state-of-the-art in image-based virtual try-on, a technology that has the potential to revolutionize online shopping and inspire related advancements in image generation. The authors' thorough analysis of current techniques and methodologies, combined with their proposal of a new evaluation framework and identification of future research directions, can help accelerate the development and adoption of this technology.
By addressing the gap between research progress and commercial applications, and highlighting key trends and unresolved issues, this paper serves as a valuable resource for researchers, developers, and industry stakeholders interested in advancing the field of virtual try-on. The publicly available dataset and evaluation metrics can also contribute to more consistent and meaningful comparisons between different methods, further driving innovation in this space.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
ViViD: Video Virtual Try-on using Diffusion Models
Zixun Fang, Wei Zhai, Aimin Su, Hongliang Song, Kai Zhu, Mao Wang, Yu Chen, Zhiheng Liu, Yang Cao, Zheng-Jun Zha
0
0
Video virtual try-on aims to transfer a clothing item onto the video of a target person. Directly applying the technique of image-based try-on to the video domain in a frame-wise manner will cause temporal-inconsistent outcomes while previous video-based try-on solutions can only generate low visual quality and blurring results. In this work, we present ViViD, a novel framework employing powerful diffusion models to tackle the task of video virtual try-on. Specifically, we design the Garment Encoder to extract fine-grained clothing semantic features, guiding the model to capture garment details and inject them into the target video through the proposed attention feature fusion mechanism. To ensure spatial-temporal consistency, we introduce a lightweight Pose Encoder to encode pose signals, enabling the model to learn the interactions between clothing and human posture and insert hierarchical Temporal Modules into the text-to-image stable diffusion model for more coherent and lifelike video synthesis. Furthermore, we collect a new dataset, which is the largest, with the most diverse types of garments and the highest resolution for the task of video virtual try-on to date. Extensive experiments demonstrate that our approach is able to yield satisfactory video try-on results. The dataset, codes, and weights will be publicly available. Project page: https://becauseimbatman0.github.io/ViViD.
5/29/2024
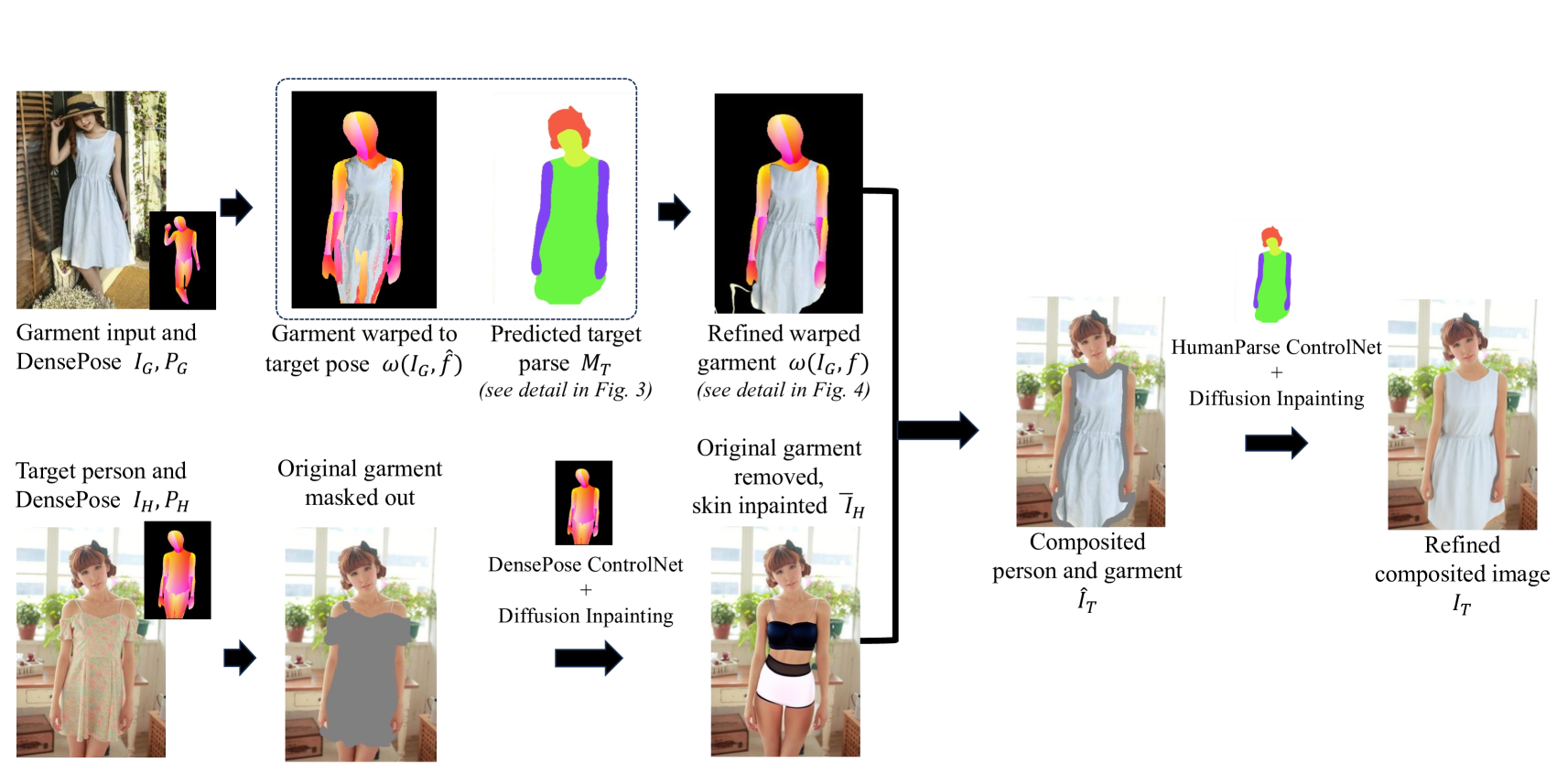
Street TryOn: Learning In-the-Wild Virtual Try-On from Unpaired Person Images
Aiyu Cui, Jay Mahajan, Viraj Shah, Preeti Gomathinayagam, Chang Liu, Svetlana Lazebnik
0
0
Most existing methods for virtual try-on focus on studio person images with a limited range of poses and clean backgrounds. They can achieve plausible results for this studio try-on setting by learning to warp a garment image to fit a person's body from paired training data, i.e., garment images paired with images of people wearing the same garment. Such data is often collected from commercial websites, where each garment is demonstrated both by itself and on several models. By contrast, it is hard to collect paired data for in-the-wild scenes, and therefore, virtual try-on for casual images of people with more diverse poses against cluttered backgrounds is rarely studied. In this work, we fill the gap by introducing a StreetTryOn benchmark to evaluate in-the-wild virtual try-on performance and proposing a novel method that can learn it without paired data, from a set of in-the-wild person images directly. Our method achieves robust performance across shop and street domains using a novel DensePose warping correction method combined with diffusion-based conditional inpainting. Our experiments show competitive performance for standard studio try-on tasks and SOTA performance for street try-on and cross-domain try-on tasks.
4/22/2024

Self-Supervised Vision Transformer for Enhanced Virtual Clothes Try-On
Lingxiao Lu, Shengyi Wu, Haoxuan Sun, Junhong Gou, Jianlou Si, Chen Qian, Jianfu Zhang, Liqing Zhang
0
0
Virtual clothes try-on has emerged as a vital feature in online shopping, offering consumers a critical tool to visualize how clothing fits. In our research, we introduce an innovative approach for virtual clothes try-on, utilizing a self-supervised Vision Transformer (ViT) coupled with a diffusion model. Our method emphasizes detail enhancement by contrasting local clothing image embeddings, generated by ViT, with their global counterparts. Techniques such as conditional guidance and focus on key regions have been integrated into our approach. These combined strategies empower the diffusion model to reproduce clothing details with increased clarity and realism. The experimental results showcase substantial advancements in the realism and precision of details in virtual try-on experiences, significantly surpassing the capabilities of existing technologies.
6/18/2024
🏅
MV-VTON: Multi-View Virtual Try-On with Diffusion Models
Haoyu Wang, Zhilu Zhang, Donglin Di, Shiliang Zhang, Wangmeng Zuo
0
0
The goal of image-based virtual try-on is to generate an image of the target person naturally wearing the given clothing. However, most existing methods solely focus on the frontal try-on using the frontal clothing. When the views of the clothing and person are significantly inconsistent, particularly when the person's view is non-frontal, the results are unsatisfactory. To address this challenge, we introduce Multi-View Virtual Try-ON (MV-VTON), which aims to reconstruct the dressing results of a person from multiple views using the given clothes. On the one hand, given that single-view clothes provide insufficient information for MV-VTON, we instead employ two images, i.e., the frontal and back views of the clothing, to encompass the complete view as much as possible. On the other hand, the diffusion models that have demonstrated superior abilities are adopted to perform our MV-VTON. In particular, we propose a view-adaptive selection method where hard-selection and soft-selection are applied to the global and local clothing feature extraction, respectively. This ensures that the clothing features are roughly fit to the person's view. Subsequently, we suggest a joint attention block to align and fuse clothing features with person features. Additionally, we collect a MV-VTON dataset, i.e., Multi-View Garment (MVG), in which each person has multiple photos with diverse views and poses. Experiments show that the proposed method not only achieves state-of-the-art results on MV-VTON task using our MVG dataset, but also has superiority on frontal-view virtual try-on task using VITON-HD and DressCode datasets. Codes and datasets will be publicly released at https://github.com/hywang2002/MV-VTON .
4/30/2024