Self-Tuning: Instructing LLMs to Effectively Acquire New Knowledge through Self-Teaching
2406.06326
0
0

Abstract
Large language models (LLMs) often struggle to provide up-to-date information due to their one-time training and the constantly evolving nature of the world. To keep LLMs current, existing approaches typically involve continued pre-training on new documents. However, they frequently face difficulties in extracting stored knowledge. Motivated by the remarkable success of the Feynman Technique in efficient human learning, we introduce Self-Tuning, a learning framework aimed at improving an LLM's ability to effectively acquire new knowledge from raw documents through self-teaching. Specifically, we develop a Self-Teaching strategy that augments the documents with a set of knowledge-intensive tasks created in a self-supervised manner, focusing on three crucial aspects: memorization, comprehension, and self-reflection. In addition, we introduce three Wiki-Newpages-2023-QA datasets to facilitate an in-depth analysis of an LLM's knowledge acquisition ability concerning memorization, extraction, and reasoning. Extensive experimental results on Llama2 family models reveal that Self-Tuning consistently exhibits superior performance across all knowledge acquisition tasks and excels in preserving previous knowledge.
Create account to get full access
Overview
• This paper presents a novel approach called "self-tuning" that enables large language models (LLMs) to effectively acquire new knowledge through self-teaching.
• The researchers propose instructing LLMs to autonomously learn new information by curating their own training data, generating their own prompts, and evaluating their own performance.
• This self-directed learning process allows LLMs to continually expand their knowledge and capabilities without the need for external supervision or ongoing fine-tuning.
Plain English Explanation
The paper introduces a technique called "self-tuning" that teaches large language models (LLMs) how to teach themselves. Instead of relying on humans to provide training data and feedback, the self-tuning approach allows the LLMs to independently find information, generate their own practice questions, and assess how well they've learned the new material.
This self-directed learning process is significant because it means LLMs can keep expanding their knowledge and skills on their own, without requiring constant human oversight or retraining. The LLMs could autonomously learn without external supervision approach allows the models to become more self-sufficient and adaptable over time.
The researchers draw inspiration from how humans learn, where we actively seek out new information, test our understanding, and refine our knowledge through practice. By imbuing LLMs with similar self-teaching capabilities, the models can continuously improve themselves and acquire expertise in a wider range of domains.
This work builds on previous research exploring self-evolution in large language models and the ability of LLMs to learn without external guidance. The self-tuning approach represents an important step forward in enabling LLMs to teach themselves and become more autonomous and capable.
Technical Explanation
The key innovation of this paper is the "self-tuning" framework, which instructs large language models (LLMs) to effectively acquire new knowledge through a self-directed learning process. The researchers propose equipping LLMs with the ability to:
-
Curate their own training data: The LLM can autonomously search for and select relevant information sources to expand its knowledge on a given topic.
-
Generate their own prompts: The LLM can create customized practice questions and tasks to test and reinforce its understanding of the new material.
-
Evaluate their own performance: The LLM can assess how well it has learned the new information by comparing its responses to high-quality reference answers.
This self-teaching workflow allows the LLM to continuously learn and improve itself without the need for external human supervision or ongoing fine-tuning. The researchers demonstrate the effectiveness of this approach through extensive experiments, showing that self-tuning enables LLMs to significantly outperform traditional fine-tuning methods in terms of knowledge acquisition and task performance.
The self-tuning framework draws inspiration from how humans learn, leveraging the LLM's natural language understanding and generation capabilities to mimic the active, self-directed learning process that humans engage in. By imbuing LLMs with this self-teaching ability, the models can become more autonomous, adaptable, and capable of expanding their knowledge and skills over time.
Critical Analysis
The self-tuning approach presented in this paper represents a promising step forward in enabling large language models to become more self-sufficient and autonomous. By allowing LLMs to curate their own training data, generate their own practice prompts, and evaluate their own performance, the models can continuously learn and improve without relying on external supervision.
However, the paper does not extensively address potential limitations or challenges that may arise with this self-tuning framework. For example, it's unclear how the LLMs would handle biases or misinformation in their self-selected training data, or how they would ensure the quality and reliability of their self-generated prompts and evaluation metrics.
Additionally, while the experiments demonstrate the efficacy of self-tuning, the paper does not explore the long-term implications of this approach. As LLMs become increasingly self-directed, there may be concerns around transparency, accountability, and the potential for the models to diverge from their intended purpose or behavior.
Further research is needed to address these potential issues and explore the broader implications of enabling LLMs to teach themselves. Nonetheless, the self-tuning approach represents a significant advancement in the field of large language model development and could have far-reaching implications for the future of artificial intelligence.
Conclusion
The paper presents a novel "self-tuning" framework that equips large language models (LLMs) with the ability to effectively acquire new knowledge through a self-directed learning process. By allowing LLMs to curate their own training data, generate their own practice prompts, and evaluate their own performance, the self-tuning approach enables the models to continuously expand their knowledge and capabilities without the need for external supervision or ongoing fine-tuning.
This work builds on previous research exploring self-evolution and self-learning in LLMs, representing an important step forward in enabling these models to become more autonomous and adaptable. While the paper does not address all potential limitations and challenges, the self-tuning approach is a significant contribution to the field of large language model development and has the potential to drive transformative advancements in artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LLMs Could Autonomously Learn Without External Supervision
Ke Ji, Junying Chen, Anningzhe Gao, Wenya Xie, Xiang Wan, Benyou Wang
0
0
In the quest for super-human performance, Large Language Models (LLMs) have traditionally been tethered to human-annotated datasets and predefined training objectives-a process that is both labor-intensive and inherently limited. This paper presents a transformative approach: Autonomous Learning for LLMs, a self-sufficient learning paradigm that frees models from the constraints of human supervision. This method endows LLMs with the ability to self-educate through direct interaction with text, akin to a human reading and comprehending literature. Our approach eliminates the reliance on annotated data, fostering an Autonomous Learning environment where the model independently identifies and reinforces its knowledge gaps. Empirical results from our comprehensive experiments, which utilized a diverse array of learning materials and were evaluated against standard public quizzes, reveal that Autonomous Learning outstrips the performance of both Pre-training and Supervised Fine-Tuning (SFT), as well as retrieval-augmented methods. These findings underscore the potential of Autonomous Learning to not only enhance the efficiency and effectiveness of LLM training but also to pave the way for the development of more advanced, self-reliant AI systems.
6/10/2024
Instruction-tuned Language Models are Better Knowledge Learners
Zhengbao Jiang, Zhiqing Sun, Weijia Shi, Pedro Rodriguez, Chunting Zhou, Graham Neubig, Xi Victoria Lin, Wen-tau Yih, Srinivasan Iyer
0
0
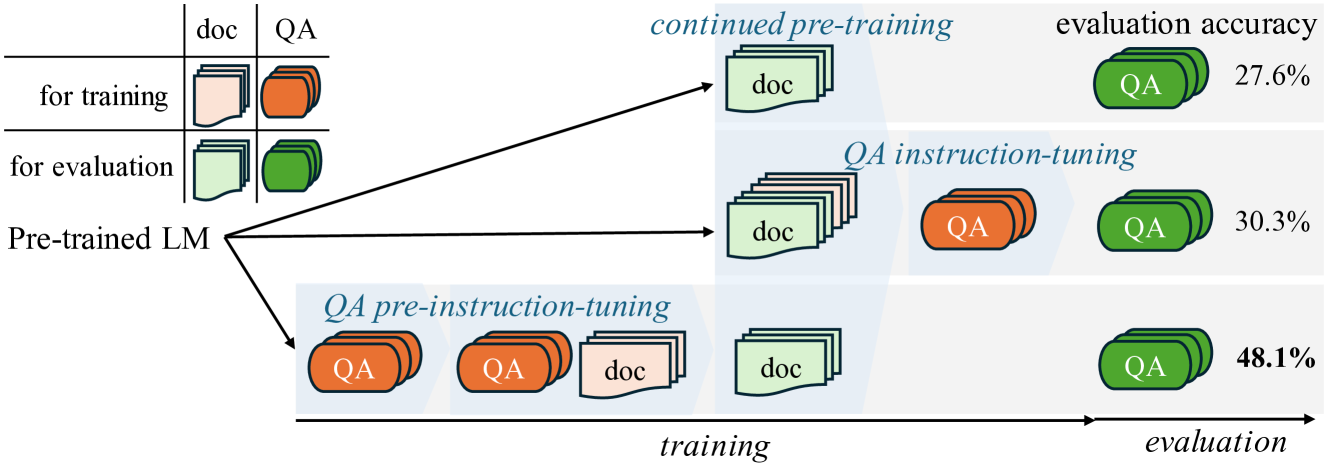
In order for large language model (LLM)-based assistants to effectively adapt to evolving information needs, it must be possible to update their factual knowledge through continued training on new data. The standard recipe for doing so involves continued pre-training on new documents followed by instruction-tuning on question-answer (QA) pairs. However, we find that LLMs trained with this recipe struggle to answer questions, even though the perplexity of documents is minimized. We found that QA pairs are generally straightforward, while documents are more complex, weaving many factual statements together in an intricate manner. Therefore, we hypothesize that it is beneficial to expose LLMs to QA pairs before continued pre-training on documents so that the process of encoding knowledge from complex documents takes into account how this knowledge is accessed through questions. Based on this, we propose pre-instruction-tuning (PIT), a method that instruction-tunes on questions prior to training on documents. This contrasts with standard instruction-tuning, which learns how to extract knowledge after training on documents. Extensive experiments and ablation studies demonstrate that pre-instruction-tuning significantly enhances the ability of LLMs to absorb knowledge from new documents, outperforming standard instruction-tuning by 17.8%.
5/28/2024
A Survey on Self-Evolution of Large Language Models
Zhengwei Tao, Ting-En Lin, Xiancai Chen, Hangyu Li, Yuchuan Wu, Yongbin Li, Zhi Jin, Fei Huang, Dacheng Tao, Jingren Zhou
0
0
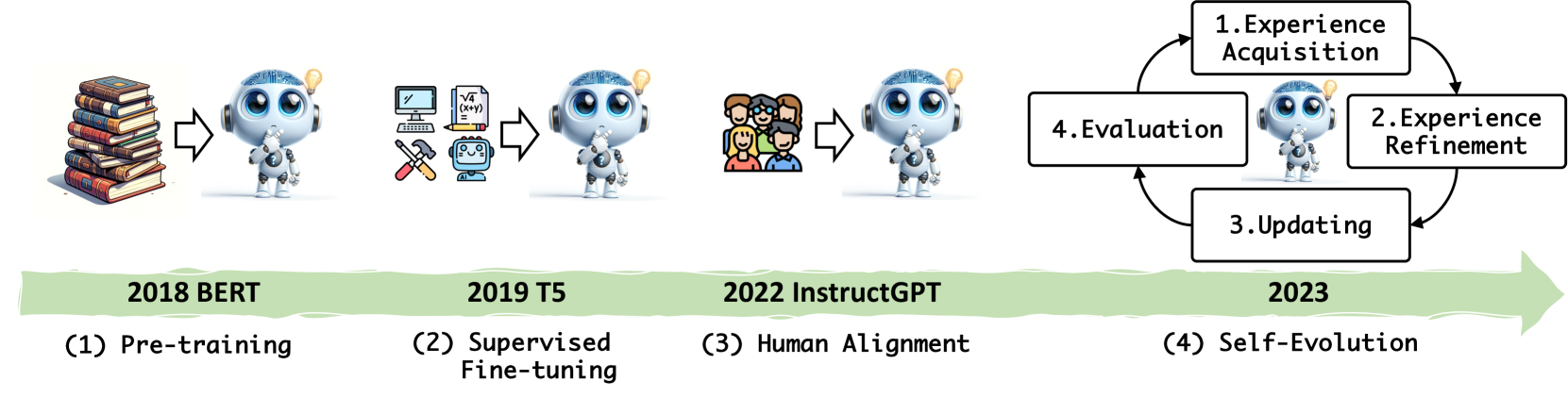
Large language models (LLMs) have significantly advanced in various fields and intelligent agent applications. However, current LLMs that learn from human or external model supervision are costly and may face performance ceilings as task complexity and diversity increase. To address this issue, self-evolution approaches that enable LLM to autonomously acquire, refine, and learn from experiences generated by the model itself are rapidly growing. This new training paradigm inspired by the human experiential learning process offers the potential to scale LLMs towards superintelligence. In this work, we present a comprehensive survey of self-evolution approaches in LLMs. We first propose a conceptual framework for self-evolution and outline the evolving process as iterative cycles composed of four phases: experience acquisition, experience refinement, updating, and evaluation. Second, we categorize the evolution objectives of LLMs and LLM-based agents; then, we summarize the literature and provide taxonomy and insights for each module. Lastly, we pinpoint existing challenges and propose future directions to improve self-evolution frameworks, equipping researchers with critical insights to fast-track the development of self-evolving LLMs. Our corresponding GitHub repository is available at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/Awesome-Self-Evolution-of-LLM
6/4/2024
💬
Into the Unknown: Self-Learning Large Language Models
Teddy Ferdinan, Jan Koco'n, Przemys{l}aw Kazienko
0
0
We address the main problem of self-learning LLM: the question of what to learn. We propose a self-learning LLM framework that enables an LLM to independently learn previously unknown knowledge through selfassessment of their own hallucinations. Using the hallucination score, we introduce a new concept of Points in the Unknown (PiUs), along with one extrinsic and three intrinsic methods for automatic PiUs identification. It facilitates the creation of a self-learning loop that focuses exclusively on the knowledge gap in Points in the Unknown, resulting in a reduced hallucination score. We also developed evaluation metrics for gauging an LLM's self-learning capability. Our experiments revealed that 7B-Mistral models that have been finetuned or aligned and RWKV5-Eagle are capable of self-learning considerably well. Our self-learning concept allows more efficient LLM updates and opens new perspectives for knowledge exchange. It may also increase public trust in AI.
6/5/2024