Instruction-tuned Language Models are Better Knowledge Learners
2402.12847
0
0
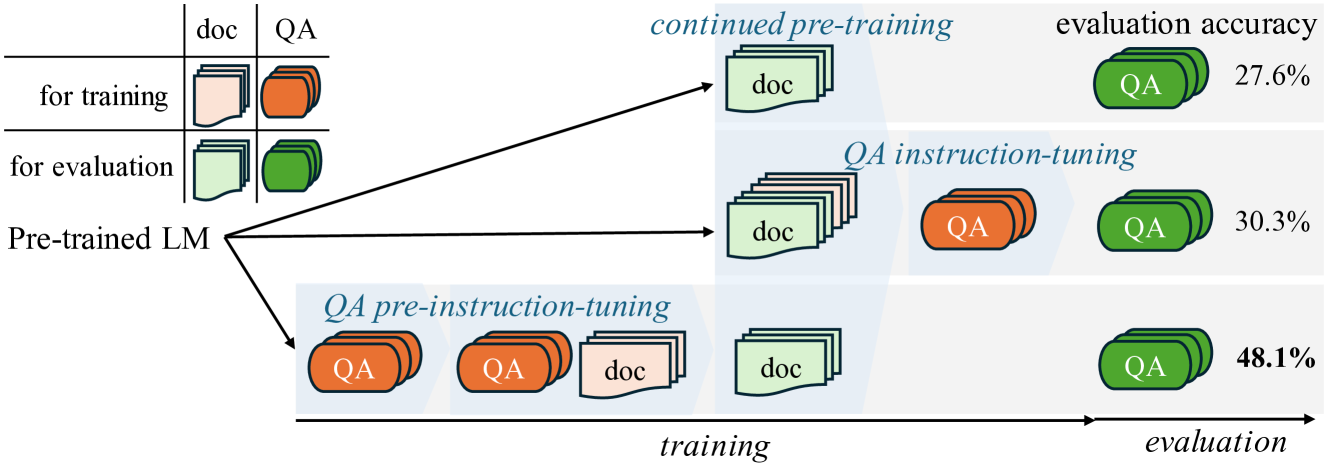
Abstract
In order for large language model (LLM)-based assistants to effectively adapt to evolving information needs, it must be possible to update their factual knowledge through continued training on new data. The standard recipe for doing so involves continued pre-training on new documents followed by instruction-tuning on question-answer (QA) pairs. However, we find that LLMs trained with this recipe struggle to answer questions, even though the perplexity of documents is minimized. We found that QA pairs are generally straightforward, while documents are more complex, weaving many factual statements together in an intricate manner. Therefore, we hypothesize that it is beneficial to expose LLMs to QA pairs before continued pre-training on documents so that the process of encoding knowledge from complex documents takes into account how this knowledge is accessed through questions. Based on this, we propose pre-instruction-tuning (PIT), a method that instruction-tunes on questions prior to training on documents. This contrasts with standard instruction-tuning, which learns how to extract knowledge after training on documents. Extensive experiments and ablation studies demonstrate that pre-instruction-tuning significantly enhances the ability of LLMs to absorb knowledge from new documents, outperforming standard instruction-tuning by 17.8%.
Create account to get full access
Overview
- This paper examines how instruction-tuned language models perform at continual knowledge acquisition compared to standard language models.
- The researchers built a dataset, called Wiki2023, to study this by progressively adding new information to a base corpus.
- They find that instruction-tuned models like Instruct-GPT and PALM are able to learn and retain new knowledge more effectively than standard language models.
Plain English Explanation
The paper looks at how language models that are trained to follow instructions, like Instruct-GPT and PALM, perform at continuously learning new information. The researchers created a dataset called Wiki2023 that starts with a base set of information and gradually adds more over time, simulating how knowledge grows.
They found that the instruction-tuned models were better able to learn and remember the new information added to the dataset compared to standard language models. This suggests that training models to understand and follow instructions, rather than just predict the next word, can make them more effective at continuously acquiring knowledge over time.
This is an important finding because it indicates that the way we train language models - whether to simply predict text or to understand and execute instructions - can have a big impact on their ability to learn and retain information. Instruction-following models may be better suited for real-world applications where adapting to new information is crucial.
Technical Explanation
The researchers built the Wiki2023 dataset to study continual knowledge acquisition. They started with a base corpus of Wikipedia articles and then progressively added new articles in a series of steps, simulating how real-world knowledge grows over time.
They then evaluated how well different language models, including standard models and instruction-tuned models like Instruct-GPT and PALM, could learn and retain the new information added at each step. The instruction-tuning process involves training the models on a diverse set of instructions to improve their ability to understand and follow instructions.
The results showed that the instruction-tuned models significantly outperformed standard language models in their ability to continually acquire new knowledge over the course of the Wiki2023 dataset. This provides empirical evidence that the training approach used for language models, such as instruction-tuning, can have a major impact on their knowledge learning capabilities.
Critical Analysis
The paper provides a rigorous experimental setup and compelling results demonstrating the advantages of instruction-tuned language models for continual knowledge acquisition. However, the dataset and experiments are limited to a specific domain - Wikipedia articles. Further research would be needed to see if these findings generalize to other types of knowledge and real-world applications.
Additionally, the paper does not deeply explore the underlying mechanisms or cognitive processes that allow instruction-tuned models to outperform standard models in this task. More analysis would be needed to fully understand the reasons for this performance gap.
Finally, the paper acknowledges that the instruction-tuned models still exhibit some limitations in their ability to retain all new information over time. Continued research is needed to further improve the continual learning capabilities of these models.
Conclusion
This paper provides evidence that training language models to understand and follow instructions, rather than just predict text, can significantly enhance their ability to continually acquire new knowledge over time. This has important implications for developing AI systems that can adapt and learn flexibly in real-world settings.
The findings suggest that the training approach used for language models is a crucial factor in determining their knowledge learning capabilities. Instruction-tuned models like Instruct-GPT and PALM appear to be better equipped than standard language models for applications that require continuous adaptation to new information. Further research in this area could lead to major advancements in artificial general intelligence and lifelong learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
From Language Modeling to Instruction Following: Understanding the Behavior Shift in LLMs after Instruction Tuning
Xuansheng Wu, Wenlin Yao, Jianshu Chen, Xiaoman Pan, Xiaoyang Wang, Ninghao Liu, Dong Yu
0
0
Large Language Models (LLMs) have achieved remarkable success, where instruction tuning is the critical step in aligning LLMs with user intentions. In this work, we investigate how the instruction tuning adjusts pre-trained models with a focus on intrinsic changes. Specifically, we first develop several local and global explanation methods, including a gradient-based method for input-output attribution, and techniques for interpreting patterns and concepts in self-attention and feed-forward layers. The impact of instruction tuning is then studied by comparing the explanations derived from the pre-trained and instruction-tuned models. This approach provides an internal perspective of the model shifts on a human-comprehensible level. Our findings reveal three significant impacts of instruction tuning: 1) It empowers LLMs to recognize the instruction parts of user prompts, and promotes the response generation constantly conditioned on the instructions. 2) It encourages the self-attention heads to capture more word-word relationships about instruction verbs. 3) It encourages the feed-forward networks to rotate their pre-trained knowledge toward user-oriented tasks. These insights contribute to a more comprehensive understanding of instruction tuning and lay the groundwork for future work that aims at explaining and optimizing LLMs for various applications. Our code and data are publicly available at https://github.com/JacksonWuxs/Interpret_Instruction_Tuning_LLMs.
4/5/2024

Self-Tuning: Instructing LLMs to Effectively Acquire New Knowledge through Self-Teaching
Xiaoying Zhang, Baolin Peng, Ye Tian, Jingyan Zhou, Yipeng Zhang, Haitao Mi, Helen Meng
0
0
Large language models (LLMs) often struggle to provide up-to-date information due to their one-time training and the constantly evolving nature of the world. To keep LLMs current, existing approaches typically involve continued pre-training on new documents. However, they frequently face difficulties in extracting stored knowledge. Motivated by the remarkable success of the Feynman Technique in efficient human learning, we introduce Self-Tuning, a learning framework aimed at improving an LLM's ability to effectively acquire new knowledge from raw documents through self-teaching. Specifically, we develop a Self-Teaching strategy that augments the documents with a set of knowledge-intensive tasks created in a self-supervised manner, focusing on three crucial aspects: memorization, comprehension, and self-reflection. In addition, we introduce three Wiki-Newpages-2023-QA datasets to facilitate an in-depth analysis of an LLM's knowledge acquisition ability concerning memorization, extraction, and reasoning. Extensive experimental results on Llama2 family models reveal that Self-Tuning consistently exhibits superior performance across all knowledge acquisition tasks and excels in preserving previous knowledge.
6/18/2024
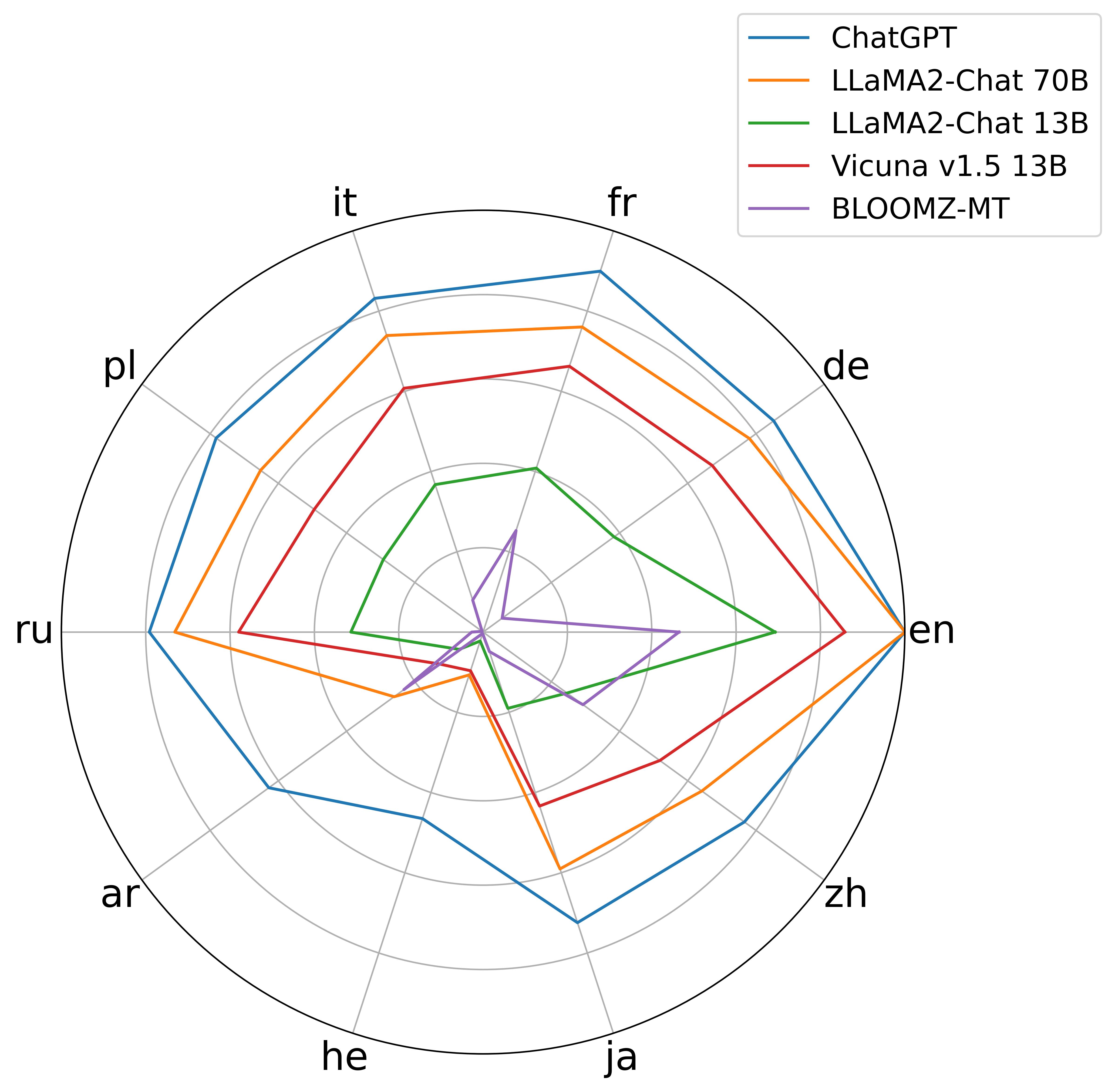
Multilingual Pretraining and Instruction Tuning Improve Cross-Lingual Knowledge Alignment, But Only Shallowly
Changjiang Gao, Hongda Hu, Peng Hu, Jiajun Chen, Jixing Li, Shujian Huang
0
0
Despite their strong ability to retrieve knowledge in English, current large language models show imbalance abilities in different languages. Two approaches are proposed to address this, i.e., multilingual pretraining and multilingual instruction tuning. However, whether and how do such methods contribute to the cross-lingual knowledge alignment inside the models is unknown. In this paper, we propose CLiKA, a systematic framework to assess the cross-lingual knowledge alignment of LLMs in the Performance, Consistency and Conductivity levels, and explored the effect of multilingual pretraining and instruction tuning on the degree of alignment. Results show that: while both multilingual pretraining and instruction tuning are beneficial for cross-lingual knowledge alignment, the training strategy needs to be carefully designed. Namely, continued pretraining improves the alignment of the target language at the cost of other languages, while mixed pretraining affect other languages less. Also, the overall cross-lingual knowledge alignment, especially in the conductivity level, is unsatisfactory for all tested LLMs, and neither multilingual pretraining nor instruction tuning can substantially improve the cross-lingual knowledge conductivity.
4/9/2024
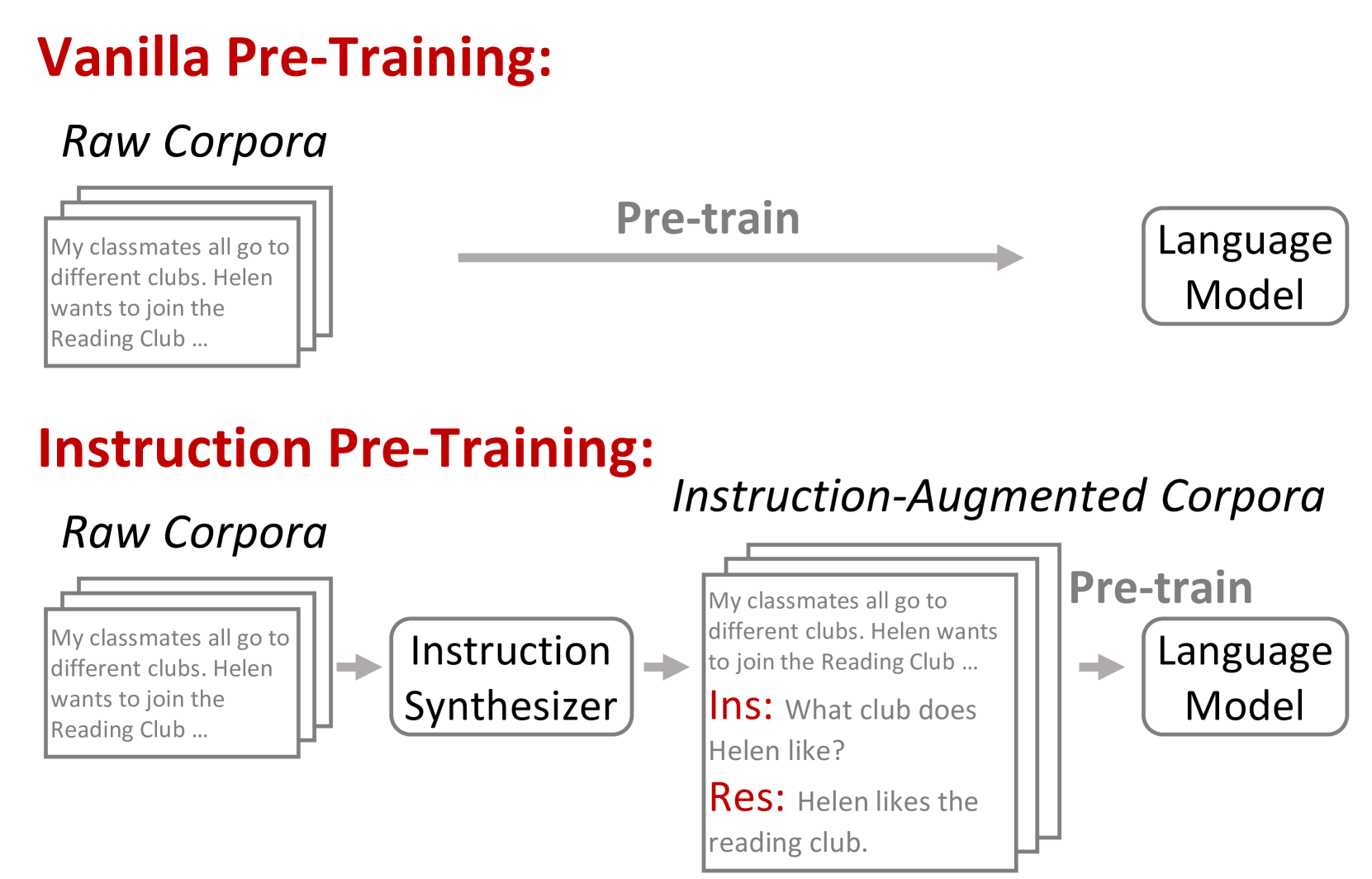
Instruction Pre-Training: Language Models are Supervised Multitask Learners
Daixuan Cheng, Yuxian Gu, Shaohan Huang, Junyu Bi, Minlie Huang, Furu Wei
0
0
Unsupervised multitask pre-training has been the critical method behind the recent success of language models (LMs). However, supervised multitask learning still holds significant promise, as scaling it in the post-training stage trends towards better generalization. In this paper, we explore supervised multitask pre-training by proposing Instruction Pre-Training, a framework that scalably augments massive raw corpora with instruction-response pairs to pre-train LMs. The instruction-response pairs are generated by an efficient instruction synthesizer built on open-source models. In our experiments, we synthesize 200M instruction-response pairs covering 40+ task categories to verify the effectiveness of Instruction Pre-Training. In pre-training from scratch, Instruction Pre-Training not only consistently enhances pre-trained base models but also benefits more from further instruction tuning. In continual pre-training, Instruction Pre-Training enables Llama3-8B to be comparable to or even outperform Llama3-70B. Our model, code, and data are available at https://github.com/microsoft/LMOps.
6/21/2024