Into the Unknown: Self-Learning Large Language Models
2402.09147
0
0
💬
Abstract
We address the main problem of self-learning LLM: the question of what to learn. We propose a self-learning LLM framework that enables an LLM to independently learn previously unknown knowledge through selfassessment of their own hallucinations. Using the hallucination score, we introduce a new concept of Points in the Unknown (PiUs), along with one extrinsic and three intrinsic methods for automatic PiUs identification. It facilitates the creation of a self-learning loop that focuses exclusively on the knowledge gap in Points in the Unknown, resulting in a reduced hallucination score. We also developed evaluation metrics for gauging an LLM's self-learning capability. Our experiments revealed that 7B-Mistral models that have been finetuned or aligned and RWKV5-Eagle are capable of self-learning considerably well. Our self-learning concept allows more efficient LLM updates and opens new perspectives for knowledge exchange. It may also increase public trust in AI.
Create account to get full access
Overview
- The main problem addressed is how to enable large language models (LLMs) to independently learn new knowledge without external supervision.
- The proposed solution is a self-learning framework that allows LLMs to assess their own hallucinations and identify "Points in the Unknown" (PiUs) to focus their learning on.
- Evaluation metrics were developed to gauge an LLM's self-learning capability, and experiments showed that certain model versions were able to self-learn considerably well.
- The self-learning concept could lead to more efficient LLM updates and increase public trust in AI.
Plain English Explanation
The paper tackles the challenge of how to get large language models (LLMs) to learn new things on their own, without someone constantly supervising and training them. The researchers developed a framework that allows LLMs to evaluate their own outputs and identify areas where they are uncertain or may be hallucinating (making up) information.
This framework uses a "hallucination score" to pinpoint these "Points in the Unknown" (PiUs) - the gaps in the LLM's knowledge. The model can then focus its learning efforts on these specific areas, reducing its hallucination over time through a self-learning loop.
The researchers also created ways to measure how well an LLM is able to self-learn. When they tested this on certain model versions, like 7B-Mistral and RWKV5-Eagle, they found that these models were quite capable of teaching themselves new things.
This self-learning approach could lead to more efficient ways of updating and improving LLMs over time. It may also help increase public trust in AI, as the models would be able to recognize and address their own limitations rather than blindly generating outputs.
Technical Explanation
The paper introduces a self-learning framework for large language models (LLMs) that enables them to independently learn previously unknown knowledge. The key innovation is the concept of "Points in the Unknown" (PiUs), which are identified using the model's own hallucination score.
The framework includes four methods for automatically detecting PiUs:
- An extrinsic method that compares the model's outputs to a ground truth knowledge base.
- Three intrinsic methods that analyze the model's internal confidence, consistency, and uncertainty.
These PiUs then drive a self-learning loop, where the model focuses its learning efforts on reducing the hallucination in these specific areas. The researchers also developed evaluation metrics to assess an LLM's self-learning capability.
Experiments were conducted on several model versions, including 7B-Mistral models that had been fine-tuned or aligned, as well as the RWKV5-Eagle model. The results showed that these models were able to self-learn considerably well, demonstrating the potential of this approach.
Critical Analysis
The paper presents a compelling solution to the challenge of enabling LLMs to learn autonomously. The self-learning framework and PiUs concept are novel and well-designed, providing a clear pathway for models to identify and address their own knowledge gaps.
However, the paper does not delve into potential limitations or caveats of the approach. For example, it's unclear how well the self-learning process would scale to larger, more complex models, or how robust it would be to distributional shift in the training data.
Additionally, the evaluation metrics used to assess self-learning capability may not capture all aspects of the models' learning process. Further research could explore more comprehensive ways to measure and benchmark self-learning in LLMs.
Overall, the paper presents a promising step towards more autonomous and trustworthy language models. Continued refinement and validation of the self-learning framework could yield significant advancements in the field of large language models.
Conclusion
This paper introduces a novel self-learning framework for large language models that enables them to independently identify and learn previously unknown knowledge. The key innovation is the concept of "Points in the Unknown" (PiUs), which allows the model to focus its learning efforts on specific areas where it is uncertain or hallucinating.
The experiments conducted on several model versions, including 7B-Mistral and RWKV5-Eagle, demonstrate the potential of this self-learning approach. By reducing hallucinations and autonomously expanding their knowledge, these models could lead to more efficient and trustworthy LLM updates in the future.
While the paper does not address all potential limitations, the self-learning framework represents an important step forward in the quest to create large language models that can learn and evolve on their own, without constant human supervision. As the field of AI continues to advance, this type of self-directed learning could be crucial for building public trust and unlocking new possibilities for language-based technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
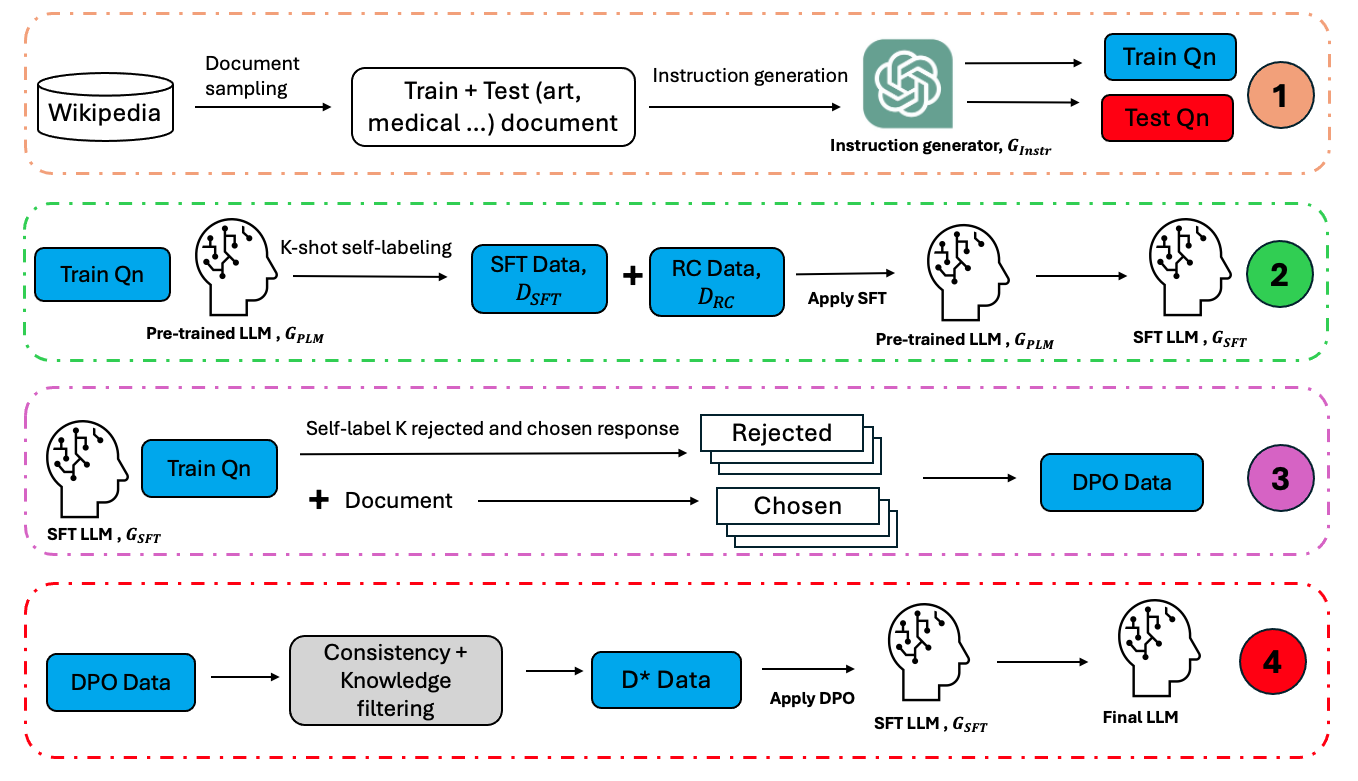
Self-training Large Language Models through Knowledge Detection
Wei Jie Yeo, Teddy Ferdinan, Przemyslaw Kazienko, Ranjan Satapathy, Erik Cambria
0
0
Large language models (LLMs) often necessitate extensive labeled datasets and training compute to achieve impressive performance across downstream tasks. This paper explores a self-training paradigm, where the LLM autonomously curates its own labels and selectively trains on unknown data samples identified through a reference-free consistency method. Empirical evaluations demonstrate significant improvements in reducing hallucination in generation across multiple subjects. Furthermore, the selective training framework mitigates catastrophic forgetting in out-of-distribution benchmarks, addressing a critical limitation in training LLMs. Our findings suggest that such an approach can substantially reduce the dependency on large labeled datasets, paving the way for more scalable and cost-effective language model training.
6/18/2024

LLMs Could Autonomously Learn Without External Supervision
Ke Ji, Junying Chen, Anningzhe Gao, Wenya Xie, Xiang Wan, Benyou Wang
0
0
In the quest for super-human performance, Large Language Models (LLMs) have traditionally been tethered to human-annotated datasets and predefined training objectives-a process that is both labor-intensive and inherently limited. This paper presents a transformative approach: Autonomous Learning for LLMs, a self-sufficient learning paradigm that frees models from the constraints of human supervision. This method endows LLMs with the ability to self-educate through direct interaction with text, akin to a human reading and comprehending literature. Our approach eliminates the reliance on annotated data, fostering an Autonomous Learning environment where the model independently identifies and reinforces its knowledge gaps. Empirical results from our comprehensive experiments, which utilized a diverse array of learning materials and were evaluated against standard public quizzes, reveal that Autonomous Learning outstrips the performance of both Pre-training and Supervised Fine-Tuning (SFT), as well as retrieval-augmented methods. These findings underscore the potential of Autonomous Learning to not only enhance the efficiency and effectiveness of LLM training but also to pave the way for the development of more advanced, self-reliant AI systems.
6/10/2024
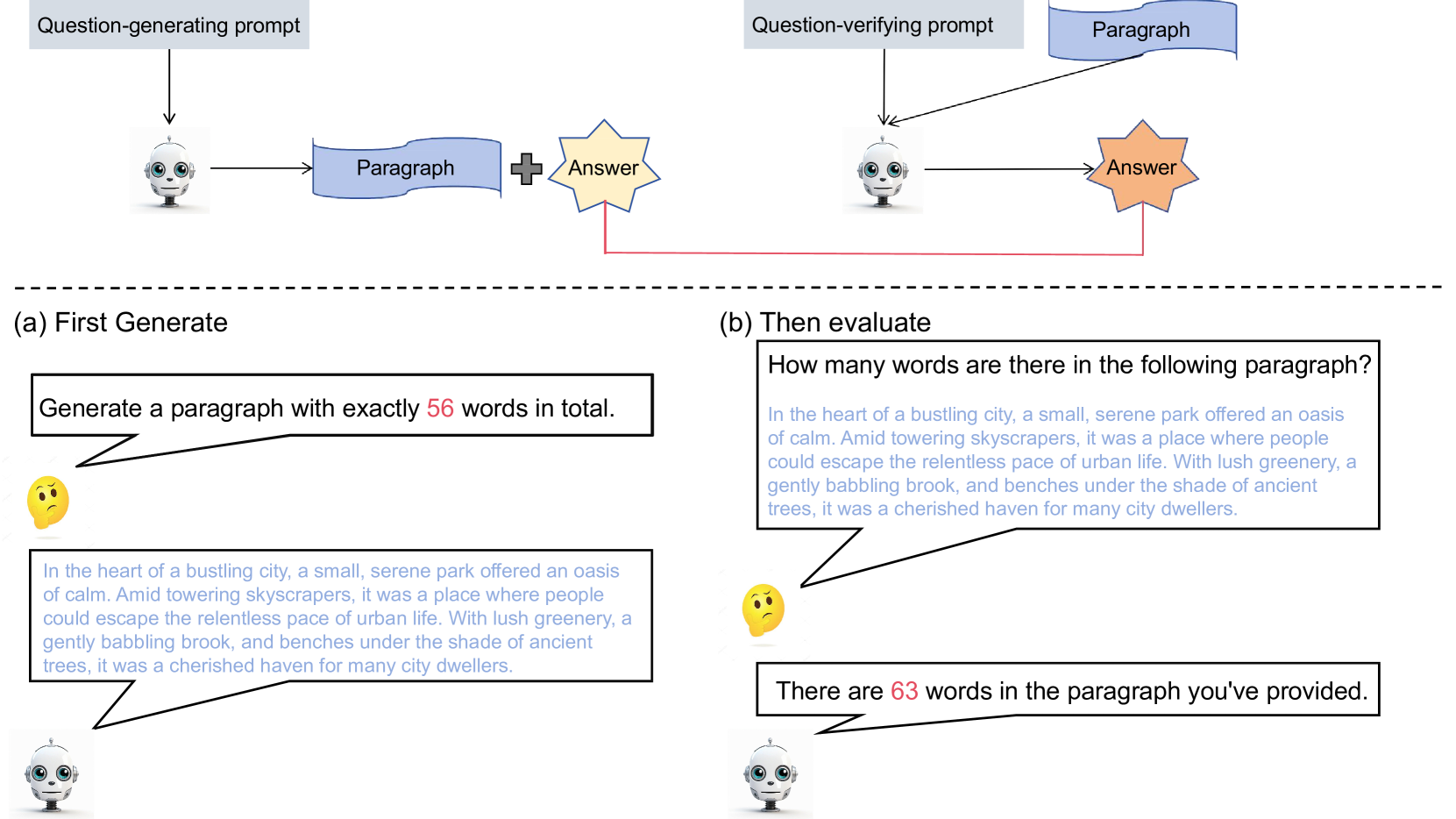
Can I understand what I create? Self-Knowledge Evaluation of Large Language Models
Zhiquan Tan, Lai Wei, Jindong Wang, Xing Xie, Weiran Huang
0
0
Large language models (LLMs) have achieved remarkable progress in linguistic tasks, necessitating robust evaluation frameworks to understand their capabilities and limitations. Inspired by Feynman's principle of understanding through creation, we introduce a self-knowledge evaluation framework that is easy to implement, evaluating models on their ability to comprehend and respond to self-generated questions. Our findings, based on testing multiple models across diverse tasks, reveal significant gaps in the model's self-knowledge ability. Further analysis indicates these gaps may be due to misalignment with human attention mechanisms. Additionally, fine-tuning on self-generated math task may enhance the model's math performance, highlighting the potential of the framework for efficient and insightful model evaluation and may also contribute to the improvement of LLMs.
6/11/2024

Self-Tuning: Instructing LLMs to Effectively Acquire New Knowledge through Self-Teaching
Xiaoying Zhang, Baolin Peng, Ye Tian, Jingyan Zhou, Yipeng Zhang, Haitao Mi, Helen Meng
0
0
Large language models (LLMs) often struggle to provide up-to-date information due to their one-time training and the constantly evolving nature of the world. To keep LLMs current, existing approaches typically involve continued pre-training on new documents. However, they frequently face difficulties in extracting stored knowledge. Motivated by the remarkable success of the Feynman Technique in efficient human learning, we introduce Self-Tuning, a learning framework aimed at improving an LLM's ability to effectively acquire new knowledge from raw documents through self-teaching. Specifically, we develop a Self-Teaching strategy that augments the documents with a set of knowledge-intensive tasks created in a self-supervised manner, focusing on three crucial aspects: memorization, comprehension, and self-reflection. In addition, we introduce three Wiki-Newpages-2023-QA datasets to facilitate an in-depth analysis of an LLM's knowledge acquisition ability concerning memorization, extraction, and reasoning. Extensive experimental results on Llama2 family models reveal that Self-Tuning consistently exhibits superior performance across all knowledge acquisition tasks and excels in preserving previous knowledge.
6/18/2024