Semantic Human Mesh Reconstruction with Textures
2403.02561
0
0

Abstract
The field of 3D detailed human mesh reconstruction has made significant progress in recent years. However, current methods still face challenges when used in industrial applications due to unstable results, low-quality meshes, and a lack of UV unwrapping and skinning weights. In this paper, we present SHERT, a novel pipeline that can reconstruct semantic human meshes with textures and high-precision details. SHERT applies semantic- and normal-based sampling between the detailed surface (e.g. mesh and SDF) and the corresponding SMPL-X model to obtain a partially sampled semantic mesh and then generates the complete semantic mesh by our specifically designed self-supervised completion and refinement networks. Using the complete semantic mesh as a basis, we employ a texture diffusion model to create human textures that are driven by both images and texts. Our reconstructed meshes have stable UV unwrapping, high-quality triangle meshes, and consistent semantic information. The given SMPL-X model provides semantic information and shape priors, allowing SHERT to perform well even with incorrect and incomplete inputs. The semantic information also makes it easy to substitute and animate different body parts such as the face, body, and hands. Quantitative and qualitative experiments demonstrate that SHERT is capable of producing high-fidelity and robust semantic meshes that outperform state-of-the-art methods.
Create account to get full access
Overview
- This research paper presents a method for reconstructing 3D human models from a single image, including both the mesh geometry and realistic textures.
- The approach combines a neural network-based 3D shape estimation with a texture mapping process to generate detailed 3D human models.
- The method can produce high-quality 3D reconstructions that capture both the shape and appearance of the human subject.
Plain English Explanation
The researchers have developed a way to create 3D digital models of people from a single photograph. Their technique combines two key steps - first, it estimates the 3D shape of the person's body, and then it adds realistic textures and details to the 3D model to make it look like the original person.
This is a challenging task because 3D shape and texture information is lost when a 3D scene is captured in a 2D photo. The researchers' approach uses an advanced neural network to analyze the photo and reconstruct the underlying 3D geometry. It then maps the visual details and colors from the 2D image onto the 3D shape to create a lifelike 3D model.
The resulting 3D human models are highly detailed and accurate, capturing not just the overall body shape but also finer details like facial features, clothing, and hair. This could have applications in areas like computer animation, virtual reality, and even digital fashion and shopping.
Technical Explanation
The paper presents a method for semantic human mesh reconstruction that generates 3D human models with high-quality textures from a single input image. The approach consists of two main components:
-
3D Shape Estimation: A neural network is used to predict the 3D mesh of the human body from the input image. This takes into account both the overall body shape as well as semantic segmentation of different body parts.
-
Texture Mapping: A separate texture mapping process is applied to add realistic surface details and colors to the 3D mesh. This combines information from the input image with a learned texture model to generate a high-fidelity texture map.
The authors evaluate their method on several benchmark datasets, demonstrating its ability to produce detailed 3D human reconstructions that accurately capture both shape and appearance. Qualitative and quantitative results show the method outperforming previous state-of-the-art techniques.
Critical Analysis
The paper presents a compelling approach for generating detailed 3D human models from single images. The combination of 3D shape estimation and texture mapping is a clever way to address the challenge of recovering the full 3D structure and appearance from 2D visual inputs.
However, the authors acknowledge some important limitations. The method relies on having a good initial 3D shape estimate, which could be affected by factors like clothing, occlusions, or unusual poses. There are also open questions about the ability to generalize to diverse human subjects beyond the training data.
Additionally, the texture mapping process assumes that the input image provides a good view of the entire human subject. In real-world scenarios, there may often be partial occlusions or cropped views that could degrade the texture quality.
Further research could explore ways to make the method more robust to these practical challenges, as well as investigating applications beyond just static 3D reconstruction, such as dynamic human modeling for animation or virtual environments.
Conclusion
This research presents an advanced technique for creating highly detailed 3D human models from single images. By combining shape estimation and texture mapping, the method can generate lifelike digital representations that capture both the geometry and appearance of the original person.
The ability to reconstruct 3D humans with such fidelity could enable new applications in areas like computer graphics, virtual reality, digital fashion, and beyond. While the current approach has some limitations, the core ideas demonstrate the potential for using deep learning to bridge the gap between 2D visual inputs and 3D reconstructions.
As this field continues to progress, we may see increasingly sophisticated tools for creating realistic digital humans that can be used in a wide range of innovative ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
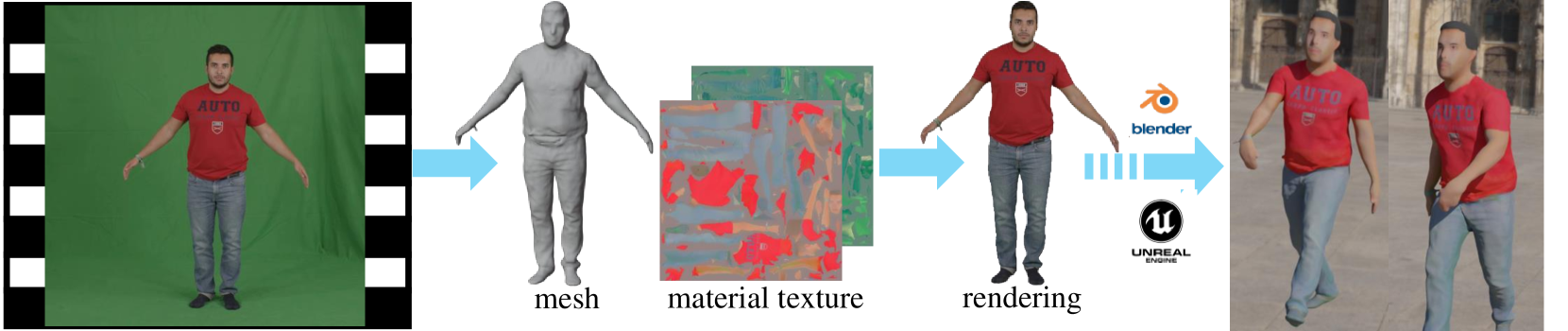
HR Human: Modeling Human Avatars with Triangular Mesh and High-Resolution Textures from Videos
Qifeng Chen, Rengan Xie, Kai Huang, Qi Wang, Wenting Zheng, Rong Li, Yuchi Huo
0
0
Recently, implicit neural representation has been widely used to generate animatable human avatars. However, the materials and geometry of those representations are coupled in the neural network and hard to edit, which hinders their application in traditional graphics engines. We present a framework for acquiring human avatars that are attached with high-resolution physically-based material textures and triangular mesh from monocular video. Our method introduces a novel information fusion strategy to combine the information from the monocular video and synthesize virtual multi-view images to tackle the sparsity of the input view. We reconstruct humans as deformable neural implicit surfaces and extract triangle mesh in a well-behaved pose as the initial mesh of the next stage. In addition, we introduce an approach to correct the bias for the boundary and size of the coarse mesh extracted. Finally, we adapt prior knowledge of the latent diffusion model at super-resolution in multi-view to distill the decomposed texture. Experiments show that our approach outperforms previous representations in terms of high fidelity, and this explicit result supports deployment on common renderers.
5/21/2024
🔎
SCULPT: Shape-Conditioned Unpaired Learning of Pose-dependent Clothed and Textured Human Meshes
Soubhik Sanyal, Partha Ghosh, Jinlong Yang, Michael J. Black, Justus Thies, Timo Bolkart
0
0
We present SCULPT, a novel 3D generative model for clothed and textured 3D meshes of humans. Specifically, we devise a deep neural network that learns to represent the geometry and appearance distribution of clothed human bodies. Training such a model is challenging, as datasets of textured 3D meshes for humans are limited in size and accessibility. Our key observation is that there exist medium-sized 3D scan datasets like CAPE, as well as large-scale 2D image datasets of clothed humans and multiple appearances can be mapped to a single geometry. To effectively learn from the two data modalities, we propose an unpaired learning procedure for pose-dependent clothed and textured human meshes. Specifically, we learn a pose-dependent geometry space from 3D scan data. We represent this as per vertex displacements w.r.t. the SMPL model. Next, we train a geometry conditioned texture generator in an unsupervised way using the 2D image data. We use intermediate activations of the learned geometry model to condition our texture generator. To alleviate entanglement between pose and clothing type, and pose and clothing appearance, we condition both the texture and geometry generators with attribute labels such as clothing types for the geometry, and clothing colors for the texture generator. We automatically generated these conditioning labels for the 2D images based on the visual question answering model BLIP and CLIP. We validate our method on the SCULPT dataset, and compare to state-of-the-art 3D generative models for clothed human bodies. Our code and data can be found at https://sculpt.is.tue.mpg.de.
5/7/2024
3D Human Reconstruction in the Wild with Synthetic Data Using Generative Models
Yongtao Ge, Wenjia Wang, Yongfan Chen, Hao Chen, Chunhua Shen
0
0
In this work, we show that synthetic data created by generative models is complementary to computer graphics (CG) rendered data for achieving remarkable generalization performance on diverse real-world scenes for 3D human pose and shape estimation (HPS). Specifically, we propose an effective approach based on recent diffusion models, termed HumanWild, which can effortlessly generate human images and corresponding 3D mesh annotations. We first collect a large-scale human-centric dataset with comprehensive annotations, e.g., text captions and surface normal images. Then, we train a customized ControlNet model upon this dataset to generate diverse human images and initial ground-truth labels. At the core of this step is that we can easily obtain numerous surface normal images from a 3D human parametric model, e.g., SMPL-X, by rendering the 3D mesh onto the image plane. As there exists inevitable noise in the initial labels, we then apply an off-the-shelf foundation segmentation model, i.e., SAM, to filter negative data samples. Our data generation pipeline is flexible and customizable to facilitate different real-world tasks, e.g., ego-centric scenes and perspective-distortion scenes. The generated dataset comprises 0.79M images with corresponding 3D annotations, covering versatile viewpoints, scenes, and human identities. We train various HPS regressors on top of the generated data and evaluate them on a wide range of benchmarks (3DPW, RICH, EgoBody, AGORA, SSP-3D) to verify the effectiveness of the generated data. By exclusively employing generative models, we generate large-scale in-the-wild human images and high-quality annotations, eliminating the need for real-world data collection.
4/12/2024

R2Human: Real-Time 3D Human Appearance Rendering from a Single Image
Yuanwang Yang, Qiao Feng, Yu-Kun Lai, Kun Li
0
0
Rendering 3D human appearance in different views is crucial for achieving holographic communication and immersive VR/AR. Existing methods either rely on multi-camera setups or have low-quality rendered images from a single image. In this paper, we propose R2Human, the first approach for real-time inference and rendering of photorealistic 3D human appearance from a single image. The core of our approach is to combine the strengths of implicit texture fields and explicit neural rendering with our novel representation, namely Z-map. Based on this, we present an end-to-end network that performs high-fidelity color reconstruction of visible areas and provides reliable color inference for occluded regions. To further enhance the 3D perception ability of our network, we leverage the Fourier occupancy field as a prior for generating the texture field and providing a sampling surface in the rendering stage. We also propose a consistency loss and a spatio-temporal fusion strategy to ensure the multi-view coherence. Experimental results show that our method outperforms the state-of-the-art methods on both synthetic data and challenging real-world images, in real time.
6/17/2024