R2Human: Real-Time 3D Human Appearance Rendering from a Single Image
2312.05826
0
0

Abstract
Rendering 3D human appearance in different views is crucial for achieving holographic communication and immersive VR/AR. Existing methods either rely on multi-camera setups or have low-quality rendered images from a single image. In this paper, we propose R2Human, the first approach for real-time inference and rendering of photorealistic 3D human appearance from a single image. The core of our approach is to combine the strengths of implicit texture fields and explicit neural rendering with our novel representation, namely Z-map. Based on this, we present an end-to-end network that performs high-fidelity color reconstruction of visible areas and provides reliable color inference for occluded regions. To further enhance the 3D perception ability of our network, we leverage the Fourier occupancy field as a prior for generating the texture field and providing a sampling surface in the rendering stage. We also propose a consistency loss and a spatio-temporal fusion strategy to ensure the multi-view coherence. Experimental results show that our method outperforms the state-of-the-art methods on both synthetic data and challenging real-world images, in real time.
Create account to get full access
Overview
- Presents a novel method called R²Human for real-time 3D human appearance rendering from a single input image
- Enables creating realistic-looking 3D avatars of people from a single photograph
- Combines 3D human reconstruction, appearance modeling, and rendering techniques to achieve high-quality results
Plain English Explanation
The R²Human system allows you to create a detailed 3D model of a person's appearance from just a single photograph. This can be useful for applications like virtual avatars, gaming, or visual effects.
The key innovations are:
- Reconstructing a 3D model of the person's body shape and pose from the 2D image.
- Modeling the detailed appearance of the person's skin, hair, and clothing.
- Rendering the 3D avatar in real-time to produce a realistic final result.
By combining these techniques, R²Human can generate a high-quality 3D avatar that captures the unique visual characteristics of the individual in the input photo. This saves time and effort compared to manually creating 3D models from scratch.
The Human 3D Diffusion and HR-Human models have also explored 3D human reconstruction and avatar creation from images. The InstantAvatar and SSR methods are related in terms of 3D reconstruction from 2D inputs. The Joint2Human work also looks at high-quality 3D human modeling.
Technical Explanation
The R²Human system first uses a 3D human reconstruction model to estimate the 3D body shape and pose of the person in the input image. It then applies an appearance model to add realistic skin, hair, and clothing textures to the 3D avatar. Finally, the 3D model is rendered in real-time to produce the final result.
Key technical components include:
- A neural network-based 3D human reconstruction module that infers the 3D body shape, pose, and camera parameters from a single 2D image.
- An appearance modeling module that generates detailed textures for the skin, hair, and clothing of the 3D human model.
- A real-time rendering pipeline that can efficiently display the final 3D avatar.
The paper presents detailed experiments and evaluations to demonstrate the effectiveness of the R²Human approach. Comparisons are made to existing 3D human reconstruction and avatar creation methods.
Critical Analysis
The R²Human paper presents a promising approach for generating realistic 3D avatars from single images. However, some limitations and areas for further research are noted:
- The appearance modeling is currently limited to a fixed set of clothing and hair styles. Expanding the range of supported styles could improve flexibility.
- The real-time rendering performance may be challenging to achieve on lower-end hardware, limiting the deployment scenarios.
- Further work is needed to ensure the generated avatars are fully photo-realistic and perceptually indistinguishable from real people.
Additionally, ethical considerations around the use of such avatar creation technology should be carefully examined, particularly around potential misuse for deception or manipulation.
Conclusion
The R²Human system represents an important advancement in the field of 3D human modeling and avatar creation. By combining 3D reconstruction, appearance modeling, and real-time rendering, it enables the generation of highly realistic digital representations of people from single input images.
This technology could have significant applications in areas like virtual communication, gaming, and visual effects. However, the potential societal impacts, both positive and negative, should be thoughtfully considered as the capabilities of such systems continue to evolve.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion Models
Yuxuan Xue, Xianghui Xie, Riccardo Marin, Gerard Pons-Moll
0
0
Creating realistic avatars from a single RGB image is an attractive yet challenging problem. Due to its ill-posed nature, recent works leverage powerful prior from 2D diffusion models pretrained on large datasets. Although 2D diffusion models demonstrate strong generalization capability, they cannot provide multi-view shape priors with guaranteed 3D consistency. We propose Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion. Our key insight is that 2D multi-view diffusion and 3D reconstruction models provide complementary information for each other, and by coupling them in a tight manner, we can fully leverage the potential of both models. We introduce a novel image-conditioned generative 3D Gaussian Splats reconstruction model that leverages the priors from 2D multi-view diffusion models, and provides an explicit 3D representation, which further guides the 2D reverse sampling process to have better 3D consistency. Experiments show that our proposed framework outperforms state-of-the-art methods and enables the creation of realistic avatars from a single RGB image, achieving high-fidelity in both geometry and appearance. Extensive ablations also validate the efficacy of our design, (1) multi-view 2D priors conditioning in generative 3D reconstruction and (2) consistency refinement of sampling trajectory via the explicit 3D representation. Our code and models will be released on https://yuxuan-xue.com/human-3diffusion.
6/13/2024
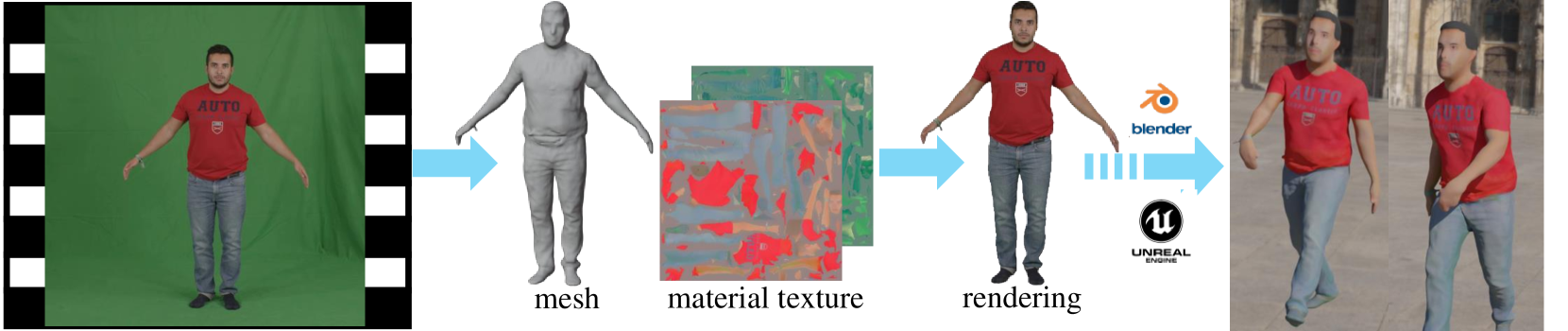
HR Human: Modeling Human Avatars with Triangular Mesh and High-Resolution Textures from Videos
Qifeng Chen, Rengan Xie, Kai Huang, Qi Wang, Wenting Zheng, Rong Li, Yuchi Huo
0
0
Recently, implicit neural representation has been widely used to generate animatable human avatars. However, the materials and geometry of those representations are coupled in the neural network and hard to edit, which hinders their application in traditional graphics engines. We present a framework for acquiring human avatars that are attached with high-resolution physically-based material textures and triangular mesh from monocular video. Our method introduces a novel information fusion strategy to combine the information from the monocular video and synthesize virtual multi-view images to tackle the sparsity of the input view. We reconstruct humans as deformable neural implicit surfaces and extract triangle mesh in a well-behaved pose as the initial mesh of the next stage. In addition, we introduce an approach to correct the bias for the boundary and size of the coarse mesh extracted. Finally, we adapt prior knowledge of the latent diffusion model at super-resolution in multi-view to distill the decomposed texture. Experiments show that our approach outperforms previous representations in terms of high fidelity, and this explicit result supports deployment on common renderers.
5/21/2024
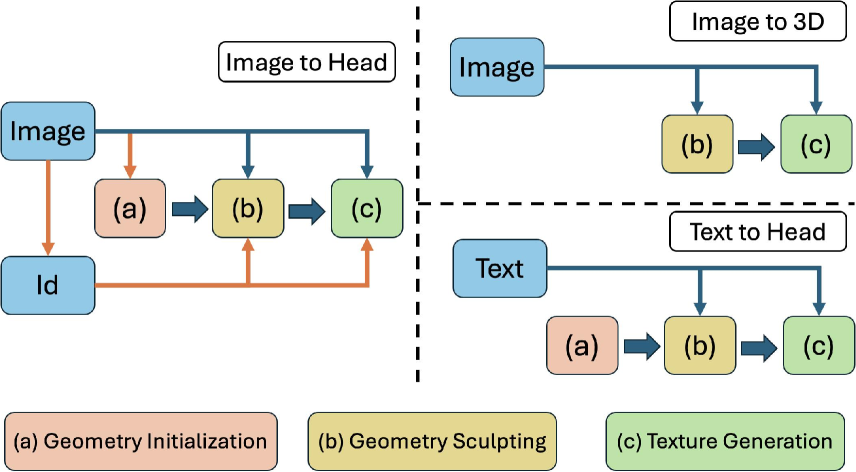
Portrait3D: 3D Head Generation from Single In-the-wild Portrait Image
Jinkun Hao, Junshu Tang, Jiangning Zhang, Ran Yi, Yijia Hong, Moran Li, Weijian Cao, Yating Wang, Lizhuang Ma
0
0
While recent works have achieved great success on one-shot 3D common object generation, high quality and fidelity 3D head generation from a single image remains a great challenge. Previous text-based methods for generating 3D heads were limited by text descriptions and image-based methods struggled to produce high-quality head geometry. To handle this challenging problem, we propose a novel framework, Portrait3D, to generate high-quality 3D heads while preserving their identities. Our work incorporates the identity information of the portrait image into three parts: 1) geometry initialization, 2) geometry sculpting, and 3) texture generation stages. Given a reference portrait image, we first align the identity features with text features to realize ID-aware guidance enhancement, which contains the control signals representing the face information. We then use the canny map, ID features of the portrait image, and a pre-trained text-to-normal/depth diffusion model to generate ID-aware geometry supervision, and 3D-GAN inversion is employed to generate ID-aware geometry initialization. Furthermore, with the ability to inject identity information into 3D head generation, we use ID-aware guidance to calculate ID-aware Score Distillation (ISD) for geometry sculpting. For texture generation, we adopt the ID Consistent Texture Inpainting and Refinement which progressively expands the view for texture inpainting to obtain an initialization UV texture map. We then use the id-aware guidance to provide image-level supervision for noisy multi-view images to obtain a refined texture map. Extensive experiments demonstrate that we can generate high-quality 3D heads with accurate geometry and texture from single in-the-wild portrait images. The project page is at https://jinkun-hao.github.io/Portrait3D/.
6/26/2024
🤷
InstantAvatar: Efficient 3D Head Reconstruction via Surface Rendering
Antonio Canela, Pol Caselles, Ibrar Malik, Eduard Ramon, Jaime Garc'ia, Jordi S'anchez-Riera, Gil Triginer, Francesc Moreno-Noguer
0
0
Recent advances in full-head reconstruction have been obtained by optimizing a neural field through differentiable surface or volume rendering to represent a single scene. While these techniques achieve an unprecedented accuracy, they take several minutes, or even hours, due to the expensive optimization process required. In this work, we introduce InstantAvatar, a method that recovers full-head avatars from few images (down to just one) in a few seconds on commodity hardware. In order to speed up the reconstruction process, we propose a system that combines, for the first time, a voxel-grid neural field representation with a surface renderer. Notably, a naive combination of these two techniques leads to unstable optimizations that do not converge to valid solutions. In order to overcome this limitation, we present a novel statistical model that learns a prior distribution over 3D head signed distance functions using a voxel-grid based architecture. The use of this prior model, in combination with other design choices, results into a system that achieves 3D head reconstructions with comparable accuracy as the state-of-the-art with a 100x speed-up.
4/8/2024