A Semantic and Motion-Aware Spatiotemporal Transformer Network for Action Detection
2405.08204
0
0

Abstract
This paper presents a novel spatiotemporal transformer network that introduces several original components to detect actions in untrimmed videos. First, the multi-feature selective semantic attention model calculates the correlations between spatial and motion features to model spatiotemporal interactions between different action semantics properly. Second, the motion-aware network encodes the locations of action semantics in video frames utilizing the motion-aware 2D positional encoding algorithm. Such a motion-aware mechanism memorizes the dynamic spatiotemporal variations in action frames that current methods cannot exploit. Third, the sequence-based temporal attention model captures the heterogeneous temporal dependencies in action frames. In contrast to standard temporal attention used in natural language processing, primarily aimed at finding similarities between linguistic words, the proposed sequence-based temporal attention is designed to determine both the differences and similarities between video frames that jointly define the meaning of actions. The proposed approach outperforms the state-of-the-art solutions on four spatiotemporal action datasets: AVA 2.2, AVA 2.1, UCF101-24, and EPIC-Kitchens.
Create account to get full access
Overview
- Introduces a new Transformer-based network called ActNetFormer for human action detection in videos
- Incorporates semantic and motion-aware spatiotemporal attention to capture the complex dynamics of human actions
- Demonstrates state-of-the-art performance on several action detection benchmarks
Plain English Explanation
The paper presents a new deep learning model called ActNetFormer for detecting human actions in video. Action detection is the task of identifying what actions are happening and when they occur in a video. This is an important capability for applications like video understanding, surveillance, and robotics.
ActNetFormer uses a Transformer-based architecture, which is a type of neural network that excels at modeling long-range dependencies and complex patterns. Crucially, ActNetFormer incorporates two novel components: semantic and motion-aware spatiotemporal attention.
The semantic attention module allows the model to understand the high-level meaning and context of the actions, while the motion-aware attention focuses on the dynamic movement patterns that characterize different actions. By combining these two types of attention, ActNetFormer can better capture the full spatiotemporal nature of human actions, leading to improved detection performance.
The authors validate ActNetFormer on several popular action detection benchmarks, where it achieves state-of-the-art results. This suggests the model's effectiveness at modeling the rich semantics and motion dynamics involved in human activities.
Technical Explanation
The core of ActNetFormer is a Transformer-based architecture that takes in video frames and outputs action detections. The key innovations are the semantic and motion-aware spatiotemporal attention modules.
The semantic attention module learns to focus on the high-level semantics and context of the actions, drawing on visual and linguistic representations. This allows the model to better understand the meaning and purpose of the observed activities.
The motion-aware attention module, on the other hand, concentrates on the dynamic motion patterns that characterize different actions. It models the spatiotemporal evolution of the video, capturing the distinctive movement trajectories and poses associated with each action.
By combining these two types of attention, ActNetFormer can comprehensively model both the semantic and motion aspects of human actions, leading to more accurate detection. The authors also incorporate a semi-supervised training approach to leverage unlabeled video data and further boost performance.
The authors evaluate ActNetFormer on several action detection benchmarks, including THUMOS14, ActivityNet, and Charades, where it outperforms previous state-of-the-art methods. This demonstrates the effectiveness of the model's Transformer-based architecture and its semantic and motion-aware attention mechanisms.
Critical Analysis
The paper presents a well-designed and technically sound approach to human action detection. The incorporation of semantic and motion-aware attention is a clever way to capture the complex spatiotemporal nature of actions, going beyond previous methods that may have focused more narrowly on visual features or motion patterns alone.
That said, the authors acknowledge some limitations of their work. For example, the mixture-of-experts approach used in ActNetFormer could potentially be further refined to improve its ability to handle diverse action types and scales. Additionally, the semi-supervised training strategy, while effective, may be sensitive to the quality and quantity of the unlabeled data used.
Future research could explore ways to make ActNetFormer more robust and generalizable, such as by incorporating additional modalities (e.g., audio, text) or investigating more advanced semi-supervised or self-supervised learning techniques. Applying the model to real-world applications and studying its performance under real-world conditions would also be valuable.
Overall, the ActNetFormer model represents an important step forward in video action detection, demonstrating the power of Transformer-based architectures and the benefits of integrating semantic and motion-aware representations. The research paves the way for continued advancements in this crucial field of computer vision.
Conclusion
The paper introduces ActNetFormer, a novel Transformer-based network for human action detection in videos. By incorporating semantic and motion-aware spatiotemporal attention, the model is able to effectively capture the complex dynamics of human actions, leading to state-of-the-art performance on several benchmarks.
This research highlights the value of combining high-level semantic understanding with low-level motion patterns for video understanding tasks. The authors' work contributes to the ongoing efforts to develop more robust and comprehensive action detection systems, with potential applications in areas like surveillance, video analysis, and human-robot interaction.
Overall, ActNetFormer represents an exciting advancement in the field of computer vision, showcasing the power of Transformer-based architectures and the importance of integrating diverse representational cues for complex scene understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

An Effective-Efficient Approach for Dense Multi-Label Action Detection
Faegheh Sardari, Armin Mustafa, Philip J. B. Jackson, Adrian Hilton
0
0
Unlike the sparse label action detection task, where a single action occurs in each timestamp of a video, in a dense multi-label scenario, actions can overlap. To address this challenging task, it is necessary to simultaneously learn (i) temporal dependencies and (ii) co-occurrence action relationships. Recent approaches model temporal information by extracting multi-scale features through hierarchical transformer-based networks. However, the self-attention mechanism in transformers inherently loses temporal positional information. We argue that combining this with multiple sub-sampling processes in hierarchical designs can lead to further loss of positional information. Preserving this information is essential for accurate action detection. In this paper, we address this issue by proposing a novel transformer-based network that (a) employs a non-hierarchical structure when modelling different ranges of temporal dependencies and (b) embeds relative positional encoding in its transformer layers. Furthermore, to model co-occurrence action relationships, current methods explicitly embed class relations into the transformer network. However, these approaches are not computationally efficient, as the network needs to compute all possible pair action class relations. We also overcome this challenge by introducing a novel learning paradigm that allows the network to benefit from explicitly modelling temporal co-occurrence action dependencies without imposing their additional computational costs during inference. We evaluate the performance of our proposed approach on two challenging dense multi-label benchmark datasets and show that our method improves the current state-of-the-art results.
6/11/2024

ActNetFormer: Transformer-ResNet Hybrid Method for Semi-Supervised Action Recognition in Videos
Sharana Dharshikgan Suresh Dass, Hrishav Bakul Barua, Ganesh Krishnasamy, Raveendran Paramesran, Raphael C. -W. Phan
0
0
Human action or activity recognition in videos is a fundamental task in computer vision with applications in surveillance and monitoring, self-driving cars, sports analytics, human-robot interaction and many more. Traditional supervised methods require large annotated datasets for training, which are expensive and time-consuming to acquire. This work proposes a novel approach using Cross-Architecture Pseudo-Labeling with contrastive learning for semi-supervised action recognition. Our framework leverages both labeled and unlabelled data to robustly learn action representations in videos, combining pseudo-labeling with contrastive learning for effective learning from both types of samples. We introduce a novel cross-architecture approach where 3D Convolutional Neural Networks (3D CNNs) and video transformers (VIT) are utilised to capture different aspects of action representations; hence we call it ActNetFormer. The 3D CNNs excel at capturing spatial features and local dependencies in the temporal domain, while VIT excels at capturing long-range dependencies across frames. By integrating these complementary architectures within the ActNetFormer framework, our approach can effectively capture both local and global contextual information of an action. This comprehensive representation learning enables the model to achieve better performance in semi-supervised action recognition tasks by leveraging the strengths of each of these architectures. Experimental results on standard action recognition datasets demonstrate that our approach performs better than the existing methods, achieving state-of-the-art performance with only a fraction of labeled data. The official website of this work is available at: https://github.com/rana2149/ActNetFormer.
4/10/2024

SpATr: MoCap 3D Human Action Recognition based on Spiral Auto-encoder and Transformer Network
Hamza Bouzid, Lahoucine Ballihi
0
0
Recent technological advancements have significantly expanded the potential of human action recognition through harnessing the power of 3D data. This data provides a richer understanding of actions, including depth information that enables more accurate analysis of spatial and temporal characteristics. In this context, We study the challenge of 3D human action recognition.Unlike prior methods, that rely on sampling 2D depth images, skeleton points, or point clouds, often leading to substantial memory requirements and the ability to handle only short sequences, we introduce a novel approach for 3D human action recognition, denoted as SpATr (Spiral Auto-encoder and Transformer Network), specifically designed for fixed-topology mesh sequences. The SpATr model disentangles space and time in the mesh sequences. A lightweight auto-encoder, based on spiral convolutions, is employed to extract spatial geometrical features from each 3D mesh. These convolutions are lightweight and specifically designed for fix-topology mesh data. Subsequently, a temporal transformer, based on self-attention, captures the temporal context within the feature sequence. The self-attention mechanism enables long-range dependencies capturing and parallel processing, ensuring scalability for long sequences. The proposed method is evaluated on three prominent 3D human action datasets: Babel, MoVi, and BMLrub, from the Archive of Motion Capture As Surface Shapes (AMASS). Our results analysis demonstrates the competitive performance of our SpATr model in 3D human action recognition while maintaining efficient memory usage. The code and the training results will soon be made publicly available at https://github.com/h-bouzid/spatr.
5/31/2024
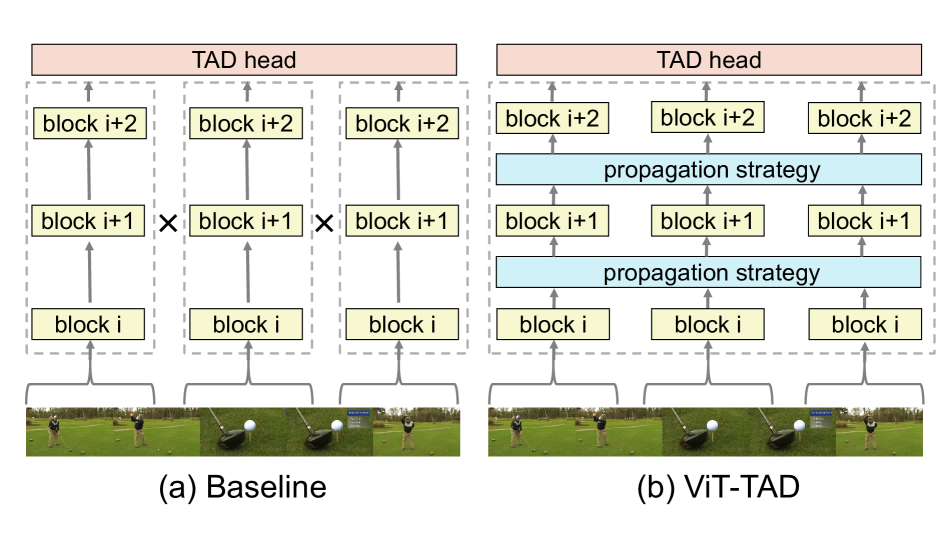
Adapting Short-Term Transformers for Action Detection in Untrimmed Videos
Min Yang, Huan Gao, Ping Guo, Limin Wang
0
0
Vision Transformer (ViT) has shown high potential in video recognition, owing to its flexible design, adaptable self-attention mechanisms, and the efficacy of masked pre-training. Yet, it remains unclear how to adapt these pre-trained short-term ViTs for temporal action detection (TAD) in untrimmed videos. The existing works treat them as off-the-shelf feature extractors for each short-trimmed snippet without capturing the fine-grained relation among different snippets in a broader temporal context. To mitigate this issue, this paper focuses on designing a new mechanism for adapting these pre-trained ViT models as a unified long-form video transformer to fully unleash its modeling power in capturing inter-snippet relation, while still keeping low computation overhead and memory consumption for efficient TAD. To this end, we design effective cross-snippet propagation modules to gradually exchange short-term video information among different snippets from two levels. For inner-backbone information propagation, we introduce a cross-snippet propagation strategy to enable multi-snippet temporal feature interaction inside the backbone.For post-backbone information propagation, we propose temporal transformer layers for further clip-level modeling. With the plain ViT-B pre-trained with VideoMAE, our end-to-end temporal action detector (ViT-TAD) yields a very competitive performance to previous temporal action detectors, riching up to 69.5 average mAP on THUMOS14, 37.40 average mAP on ActivityNet-1.3 and 17.20 average mAP on FineAction.
4/16/2024