Exploring Explainability in Video Action Recognition
2404.09067
0
0

Abstract
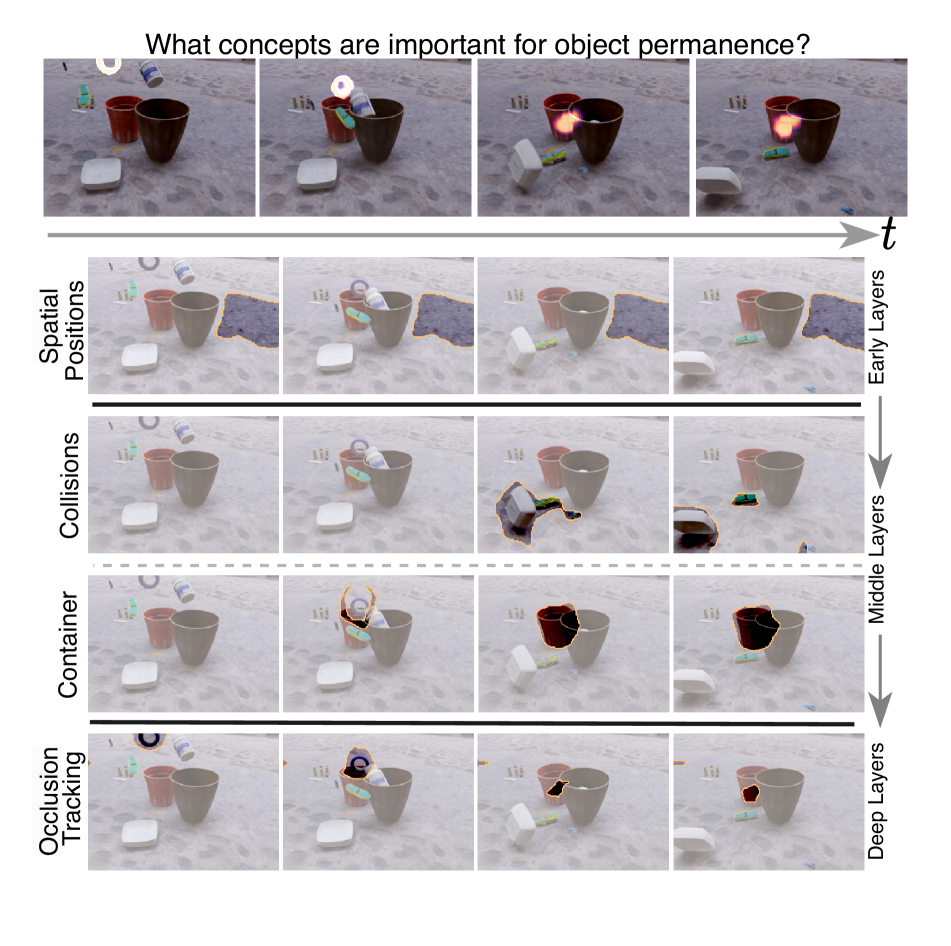
Image Classification and Video Action Recognition are perhaps the two most foundational tasks in computer vision. Consequently, explaining the inner workings of trained deep neural networks is of prime importance. While numerous efforts focus on explaining the decisions of trained deep neural networks in image classification, exploration in the domain of its temporal version, video action recognition, has been scant. In this work, we take a deeper look at this problem. We begin by revisiting Grad-CAM, one of the popular feature attribution methods for Image Classification, and its extension to Video Action Recognition tasks and examine the method's limitations. To address these, we introduce Video-TCAV, by building on TCAV for Image Classification tasks, which aims to quantify the importance of specific concepts in the decision-making process of Video Action Recognition models. As the scalable generation of concepts is still an open problem, we propose a machine-assisted approach to generate spatial and spatiotemporal concepts relevant to Video Action Recognition for testing Video-TCAV. We then establish the importance of temporally-varying concepts by demonstrating the superiority of dynamic spatiotemporal concepts over trivial spatial concepts. In conclusion, we introduce a framework for investigating hypotheses in action recognition and quantitatively testing them, thus advancing research in the explainability of deep neural networks used in video action recognition.
Create account to get full access
Overview
- This paper explores methods for explaining the decision-making process of video action recognition models.
- The authors extend the popular Grad-CAM technique to work with video inputs, allowing for visualization of the model's attention on important spatial and temporal regions.
- They also propose a new method, Temporal Grad-CAM, which can highlight the temporal aspects of the model's reasoning.
- The paper includes experiments on benchmark video datasets to evaluate the proposed techniques and compare them to existing video explanation methods.
Plain English Explanation
The paper focuses on making video recognition models more understandable. These models are used to analyze videos and identify the actions or events that are happening. However, it can be difficult to understand how these complex models arrive at their predictions.
The researchers build on a technique called Grad-CAM, which was originally developed for image recognition. Grad-CAM allows you to see which parts of an image the model is paying attention to when making a prediction. The authors extend this idea to work with videos, so you can see both the spatial regions and the specific moments in time that the model is focusing on.
They also introduce a new method called Temporal Grad-CAM, which provides an even more detailed view of the model's reasoning. This allows you to see not just where the model is looking, but when it is looking at different parts of the video.
Through experiments on standard video datasets, the researchers demonstrate that these new explanation techniques can provide valuable insights into how video recognition models work. This can help researchers and developers better understand the strengths and limitations of these models, and potentially improve them in the future.
Technical Explanation
The paper builds on the Grad-CAM technique for explaining the decision-making process of convolutional neural networks. Grad-CAM visualizes the important spatial regions that the model focuses on when making a prediction.
To extend Grad-CAM to video inputs, the authors propose a two-step process. First, they compute Grad-CAM maps for each frame of the video. Then, they aggregate these frame-level maps over time to obtain a video-level explanation. This allows the model to highlight not just the important spatial regions, but also the key temporal moments that contribute to the final prediction.
The authors further introduce a new method called Temporal Grad-CAM, which separates the spatial and temporal aspects of the model's reasoning. This technique computes separate Grad-CAM maps for the spatial and temporal dimensions, providing a more detailed view of the model's decision-making process.
The proposed techniques are evaluated on standard video action recognition datasets, including UCF-101 and HMDB-51. The experiments demonstrate that the extended Grad-CAM and Temporal Grad-CAM methods can effectively highlight the salient spatial and temporal features used by the model, and outperform existing video explanation approaches.
Critical Analysis
The paper presents a thorough and well-designed study on improving the explainability of video action recognition models. The authors' extension of Grad-CAM to the video domain, as well as the introduction of Temporal Grad-CAM, are valuable contributions that can help researchers and developers better understand the inner workings of these complex models.
One potential limitation of the work is that the evaluation is primarily focused on the visualization and qualitative analysis of the explanation maps, rather than a more formal quantitative assessment. While the examples provided are compelling, it would be beneficial to see a deeper analysis of how the explanations correlate with human intuitions or model performance.
Additionally, the paper does not address the potential biases or limitations that may be present in the video datasets used for evaluation. It would be important to consider how these datasets and their associated biases could impact the model's decision-making and the resulting explanations.
Further research could also explore the integration of these explanation techniques with video action recognition models that use more advanced architectures, such as video transformers or language-guided approaches. This could provide a more comprehensive understanding of the strengths and limitations of these explanation methods across a broader range of video recognition models.
Conclusion
This paper presents important advancements in the field of explainable video action recognition. By extending Grad-CAM to work with videos and introducing Temporal Grad-CAM, the authors have developed techniques that can provide valuable insights into the decision-making process of these models.
The ability to visualize the spatial and temporal aspects of a model's reasoning can help researchers and developers better understand the model's strengths and weaknesses, and potentially lead to improvements in video recognition technology. This, in turn, could have a significant impact on applications ranging from video surveillance to autonomous driving and beyond.
While the paper has a few areas for potential improvement, the overall contribution is a significant step forward in making video recognition models more transparent and trustworthy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Understanding Video Transformers via Universal Concept Discovery
Matthew Kowal, Achal Dave, Rares Ambrus, Adrien Gaidon, Konstantinos G. Derpanis, Pavel Tokmakov
0
0
This paper studies the problem of concept-based interpretability of transformer representations for videos. Concretely, we seek to explain the decision-making process of video transformers based on high-level, spatiotemporal concepts that are automatically discovered. Prior research on concept-based interpretability has concentrated solely on image-level tasks. Comparatively, video models deal with the added temporal dimension, increasing complexity and posing challenges in identifying dynamic concepts over time. In this work, we systematically address these challenges by introducing the first Video Transformer Concept Discovery (VTCD) algorithm. To this end, we propose an efficient approach for unsupervised identification of units of video transformer representations - concepts, and ranking their importance to the output of a model. The resulting concepts are highly interpretable, revealing spatio-temporal reasoning mechanisms and object-centric representations in unstructured video models. Performing this analysis jointly over a diverse set of supervised and self-supervised representations, we discover that some of these mechanism are universal in video transformers. Finally, we show that VTCD can be used for fine-grained action recognition and video object segmentation.
4/11/2024

A Semantic and Motion-Aware Spatiotemporal Transformer Network for Action Detection
Matthew Korban, Peter Youngs, Scott T. Acton
0
0
This paper presents a novel spatiotemporal transformer network that introduces several original components to detect actions in untrimmed videos. First, the multi-feature selective semantic attention model calculates the correlations between spatial and motion features to model spatiotemporal interactions between different action semantics properly. Second, the motion-aware network encodes the locations of action semantics in video frames utilizing the motion-aware 2D positional encoding algorithm. Such a motion-aware mechanism memorizes the dynamic spatiotemporal variations in action frames that current methods cannot exploit. Third, the sequence-based temporal attention model captures the heterogeneous temporal dependencies in action frames. In contrast to standard temporal attention used in natural language processing, primarily aimed at finding similarities between linguistic words, the proposed sequence-based temporal attention is designed to determine both the differences and similarities between video frames that jointly define the meaning of actions. The proposed approach outperforms the state-of-the-art solutions on four spatiotemporal action datasets: AVA 2.2, AVA 2.1, UCF101-24, and EPIC-Kitchens.
5/15/2024
🤿
A Survey on Backbones for Deep Video Action Recognition
Zixuan Tang, Youjun Zhao, Yuhang Wen, Mengyuan Liu
0
0
Action recognition is a key technology in building interactive metaverses. With the rapid development of deep learning, methods in action recognition have also achieved great advancement. Researchers design and implement the backbones referring to multiple standpoints, which leads to the diversity of methods and encountering new challenges. This paper reviews several action recognition methods based on deep neural networks. We introduce these methods in three parts: 1) Two-Streams networks and their variants, which, specifically in this paper, use RGB video frame and optical flow modality as input; 2) 3D convolutional networks, which make efforts in taking advantage of RGB modality directly while extracting different motion information is no longer necessary; 3) Transformer-based methods, which introduce the model from natural language processing into computer vision and video understanding. We offer objective sights in this review and hopefully provide a reference for future research.
5/10/2024

Vamos: Versatile Action Models for Video Understanding
Shijie Wang, Qi Zhao, Minh Quan Do, Nakul Agarwal, Kwonjoon Lee, Chen Sun
0
0
What makes good representations for video understanding, such as anticipating future activities, or answering video-conditioned questions? While earlier approaches focus on end-to-end learning directly from video pixels, we propose to revisit text-based representations, such as general-purpose video captions, which are interpretable and can be directly consumed by large language models (LLMs). Intuitively, different video understanding tasks may require representations that are complementary and at different granularity. To this end, we propose versatile action models (Vamos), a learning framework powered by a large language model as the ``reasoner'', and can flexibly leverage visual embedding and free-form text descriptions as its input. To interpret the important text evidence for question answering, we generalize the concept bottleneck model to work with tokens and nonlinear models, which uses hard attention to select a small subset of tokens from the free-form text as inputs to the LLM reasoner. We evaluate Vamos on four complementary video understanding benchmarks, Ego4D, NeXT-QA, IntentQA, and EgoSchema, on its capability to model temporal dynamics, encode visual history, and perform reasoning. Surprisingly, we observe that text-based representations consistently achieve competitive performance on all benchmarks, and that visual embeddings provide marginal or no performance improvement, demonstrating the effectiveness of text-based video representation in the LLM era. We also demonstrate that our token bottleneck model is able to select relevant evidence from free-form text, support test-time intervention, and achieves nearly 5 times inference speedup while keeping a competitive question answering performance. Code and models are publicly released at https://brown-palm.github.io/Vamos/.
5/29/2024