Semantic Residual Prompts for Continual Learning

0

Sign in to get full access
Overview
- This paper presents a novel approach called "Semantic Residual Prompts" for continual learning, which aims to address the issue of forgetting in machine learning models as they learn new tasks.
- The method involves using semantic information to create prompts that can be used to fine-tune a language model for new tasks while retaining knowledge from previous tasks.
- The authors evaluate their approach on several benchmark datasets and show that it outperforms existing continual learning methods in terms of maintaining performance on previous tasks while learning new ones.
Plain English Explanation
Continual learning is the ability of a machine learning model to learn new tasks or information without forgetting what it has learned before. This is an important capability, as real-world applications often require models to adapt to new situations over time.
The Semantic Residual Prompts for Continual Learning paper presents a novel approach to address the problem of forgetting in continual learning. The key idea is to use "semantic residual prompts" - short text snippets that capture the semantic meaning of a task - to fine-tune a language model for new tasks.
When the model learns a new task, the semantic residual prompt helps it understand the task's meaning and how it relates to previous knowledge. This allows the model to update its parameters in a way that preserves what it has learned before, rather than overwriting or forgetting that information.
For example, imagine a language model that has been trained on general English text. If the model then needs to learn how to perform sentiment analysis on movie reviews, the semantic residual prompt could capture the key concepts of "sentiment" and "movies." This would help the model adapt to the new task while retaining its existing knowledge of language.
The authors show that their semantic residual prompt approach outperforms other continual learning methods on several benchmark datasets. This suggests that incorporating semantic information into the learning process can be a effective way to enable models to continuously learn new skills without forgetting what they've already learned.
Technical Explanation
The Semantic Residual Prompts for Continual Learning paper introduces a novel continual learning method that leverages semantic information to fine-tune language models for new tasks.
The core idea is to create "semantic residual prompts" - short text sequences that capture the semantic meaning of a task. These prompts are then used to fine-tune a pre-trained language model when learning a new task. The key innovation is that the prompts are designed to preserve the model's existing knowledge, rather than overwriting it.
Specifically, the authors propose a two-stage fine-tuning process:
-
Task Encoding: A task encoder network is trained to map a task description (e.g., "sentiment analysis on movie reviews") into a semantic residual prompt. This prompt encodes the key semantic concepts of the task.
-
Prompt-based Fine-tuning: The pre-trained language model is fine-tuned on the new task, but instead of directly updating the model parameters, the semantic residual prompt is used to guide the updates. This allows the model to adapt to the new task while retaining its previous knowledge.
The authors evaluate their approach on several continual learning benchmarks, including permuted MNIST, Split CIFAR-100, and Split Mini-ImageNet. They show that the semantic residual prompt method outperforms other continual learning techniques, such as Convolutional Prompting Meets Language Models for Continual Learning, REP: Resource-Efficient Prompting for Continual Learning, and Mixture-of-Experts Meets Prompt-based Continual Learning.
The key advantage of the semantic residual prompt approach is its ability to preserve the model's existing knowledge while learning new tasks. By encoding the semantic meaning of the task into the prompt, the model can adapt its parameters in a way that avoids catastrophic forgetting, a common issue in continual learning.
Critical Analysis
The Semantic Residual Prompts for Continual Learning paper presents a promising approach to addressing the continual learning challenge, but there are a few areas that could be further explored or improved upon.
One potential limitation is that the effectiveness of the semantic residual prompts may be dependent on the quality and coverage of the task descriptions used to train the task encoder network. If the task descriptions are not sufficiently expressive or comprehensive, the resulting prompts may not fully capture the semantic meaning of the tasks.
Additionally, the paper focuses on continual learning for language models, but it's unclear how well the approach would generalize to other types of machine learning models, such as vision or multimodal models. Exploring the applicability of semantic residual prompts to a wider range of domains could help validate the broader utility of the method.
Finally, while the paper demonstrates strong performance on standard continual learning benchmarks, it would be valuable to see the method evaluated on more real-world, dynamic task scenarios that better reflect the challenges of continual learning in practical applications.
Overall, the Semantic Residual Prompts for Continual Learning paper presents an innovative approach that effectively leverages semantic information to enable continual learning. Further research to address the potential limitations and explore the method's broader applicability could help strengthen its impact on the field.
Conclusion
The Semantic Residual Prompts for Continual Learning paper introduces a novel continual learning technique that uses semantic information to fine-tune language models for new tasks while preserving their existing knowledge.
By creating "semantic residual prompts" that capture the key concepts of a task, the authors show that their approach can outperform other state-of-the-art continual learning methods on standard benchmarks. This suggests that incorporating semantic information into the learning process can be an effective way to enable models to continuously adapt to new situations without forgetting what they've already learned.
The semantic residual prompt method represents an important step forward in the field of continual learning, with potential applications in a wide range of domains where models need to learn and adapt over time. Further research to address the method's limitations and explore its broader applicability could help unlock even more powerful and flexible AI systems that can learn and grow alongside the real-world challenges they are designed to solve.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Semantic Residual Prompts for Continual Learning
Martin Menabue, Emanuele Frascaroli, Matteo Boschini, Enver Sangineto, Lorenzo Bonicelli, Angelo Porrello, Simone Calderara
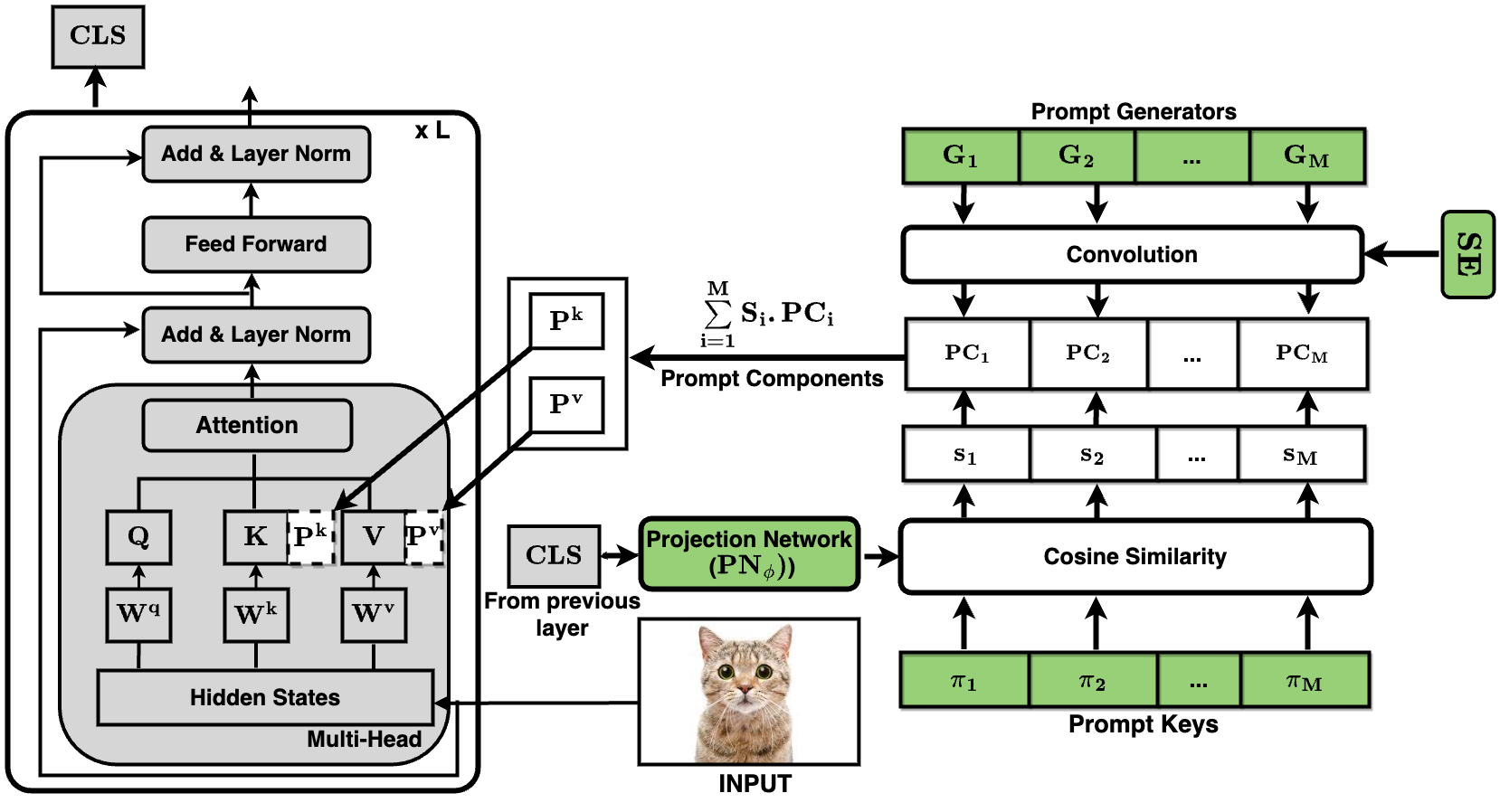
Prompt-tuning methods for Continual Learning (CL) freeze a large pre-trained model and train a few parameter vectors termed prompts. Most of these methods organize these vectors in a pool of key-value pairs and use the input image as query to retrieve the prompts (values). However, as keys are learned while tasks progress, the prompting selection strategy is itself subject to catastrophic forgetting, an issue often overlooked by existing approaches. For instance, prompts introduced to accommodate new tasks might end up interfering with previously learned prompts. To make the selection strategy more stable, we leverage a foundation model (CLIP) to select our prompts within a two-level adaptation mechanism. Specifically, the first level leverages a standard textual prompt pool for the CLIP textual encoder, leading to stable class prototypes. The second level, instead, uses these prototypes along with the query image as keys to index a second pool. The retrieved prompts serve to adapt a pre-trained ViT, granting plasticity. In doing so, we also propose a novel residual mechanism to transfer CLIP semantics to the ViT layers. Through extensive analysis on established CL benchmarks, we show that our method significantly outperforms both state-of-the-art CL approaches and the zero-shot CLIP test. Notably, our findings hold true even for datasets with a substantial domain gap w.r.t. the pre-training knowledge of the backbone model, as showcased by experiments on satellite imagery and medical datasets. The codebase is available at https://github.com/aimagelab/mammoth.
Read more7/19/2024
0
Convolutional Prompting meets Language Models for Continual Learning
Anurag Roy, Riddhiman Moulick, Vinay K. Verma, Saptarshi Ghosh, Abir Das
Continual Learning (CL) enables machine learning models to learn from continuously shifting new training data in absence of data from old tasks. Recently, pretrained vision transformers combined with prompt tuning have shown promise for overcoming catastrophic forgetting in CL. These approaches rely on a pool of learnable prompts which can be inefficient in sharing knowledge across tasks leading to inferior performance. In addition, the lack of fine-grained layer specific prompts does not allow these to fully express the strength of the prompts for CL. We address these limitations by proposing ConvPrompt, a novel convolutional prompt creation mechanism that maintains layer-wise shared embeddings, enabling both layer-specific learning and better concept transfer across tasks. The intelligent use of convolution enables us to maintain a low parameter overhead without compromising performance. We further leverage Large Language Models to generate fine-grained text descriptions of each category which are used to get task similarity and dynamically decide the number of prompts to be learned. Extensive experiments demonstrate the superiority of ConvPrompt and improves SOTA by ~3% with significantly less parameter overhead. We also perform strong ablation over various modules to disentangle the importance of different components.
Read more4/1/2024
🎯
0
CLIP with Generative Latent Replay: a Strong Baseline for Incremental Learning
Emanuele Frascaroli, Aniello Panariello, Pietro Buzzega, Lorenzo Bonicelli, Angelo Porrello, Simone Calderara
With the emergence of Transformers and Vision-Language Models (VLMs) such as CLIP, fine-tuning large pre-trained models has recently become a prevalent strategy in Continual Learning. This has led to the development of numerous prompting strategies to adapt transformer-based models without incurring catastrophic forgetting. However, these strategies often compromise the original zero-shot capabilities of the pre-trained CLIP model and struggle to adapt to domains that significantly deviate from the pre-training data. In this work, we propose Continual Generative training for Incremental prompt-Learning, a simple and novel approach to mitigate forgetting while adapting CLIP. Briefly, we employ Variational Autoencoders (VAEs) to learn class-conditioned distributions within the embedding space of the visual encoder. We then exploit these distributions to sample new synthetic visual embeddings and train the corresponding class-specific textual prompts during subsequent tasks. Through extensive experiments on different domains, we show that such a generative replay approach can adapt to new tasks while improving zero-shot capabilities, evaluated using a novel metric tailored for CL scenarios. Notably, further analysis reveals that our approach can bridge the gap with joint prompt tuning. The codebase is available at https://github.com/aimagelab/mammoth.
Read more8/15/2024

0
CLEFT: Language-Image Contrastive Learning with Efficient Large Language Model and Prompt Fine-Tuning
Yuexi Du, Brian Chang, Nicha C. Dvornek
Recent advancements in Contrastive Language-Image Pre-training (CLIP) have demonstrated notable success in self-supervised representation learning across various tasks. However, the existing CLIP-like approaches often demand extensive GPU resources and prolonged training times due to the considerable size of the model and dataset, making them poor for medical applications, in which large datasets are not always common. Meanwhile, the language model prompts are mainly manually derived from labels tied to images, potentially overlooking the richness of information within training samples. We introduce a novel language-image Contrastive Learning method with an Efficient large language model and prompt Fine-Tuning (CLEFT) that harnesses the strengths of the extensive pre-trained language and visual models. Furthermore, we present an efficient strategy for learning context-based prompts that mitigates the gap between informative clinical diagnostic data and simple class labels. Our method demonstrates state-of-the-art performance on multiple chest X-ray and mammography datasets compared with various baselines. The proposed parameter efficient framework can reduce the total trainable model size by 39% and reduce the trainable language model to only 4% compared with the current BERT encoder.
Read more7/31/2024