Semantic Understanding and Data Imputation using Large Language Model to Accelerate Recommendation System

0
Sign in to get full access
Overview
- Leverages large language models (LLMs) to improve recommendation systems
- Focuses on semantic understanding and data imputation to accelerate recommendations
- Explores techniques to effectively utilize LLMs in recommendation systems
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. This paper explores how to use LLMs to make recommendation systems, which suggest products or content to users, work better.
The key ideas are:
-
Semantic Understanding: LLMs can understand the deeper meaning and context of items, not just their surface-level attributes. This helps the recommendation system better grasp what users might actually like.
-
Data Imputation: LLMs can fill in missing information about items, like descriptions or metadata. This allows the recommendation system to make better suggestions even when the data is incomplete.
By leveraging these LLM capabilities, the researchers aim to create recommendation systems that are more accurate, personalized, and efficient. This could lead to improved user experiences and business outcomes for companies using recommendation systems, like e-commerce or content platforms.
Technical Explanation
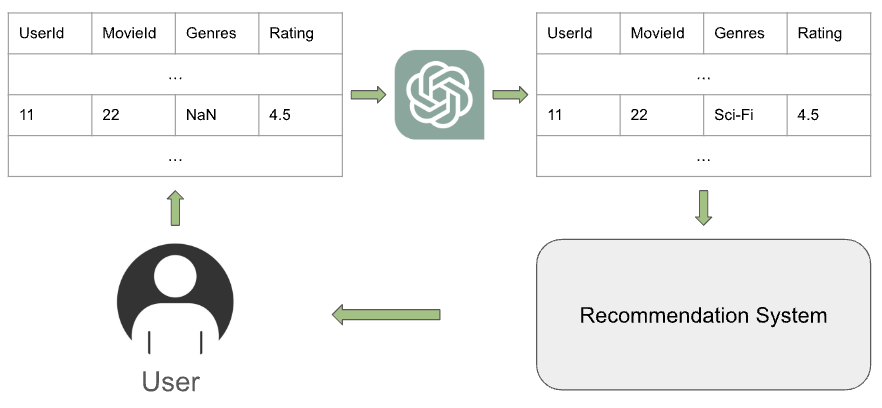
The paper proposes a framework that combines LLMs with traditional recommendation system components to enhance semantic understanding and enable data imputation.
The architecture integrates an LLM module that learns rich item representations by pretraining on large text corpora. This allows the model to capture deep semantic relationships between items beyond just their explicit features.
The LLM module is then used to:
- Enrich item representations: The LLM encodes items into dense vectors that capture their underlying semantics.
- Impute missing item data: The LLM generates plausible completions for missing item attributes or metadata.
These enhanced item representations and imputed data are then fed into a downstream recommendation model to generate personalized suggestions for users.
The researchers evaluate their approach on several real-world datasets and find it outperforms baseline recommendation systems in terms of accuracy, coverage, and efficiency.
Critical Analysis
The paper presents a promising approach to leveraging LLMs to improve recommendation systems. The key strengths are the emphasis on semantic understanding and data imputation, which are important challenges in recommendation systems.
However, the paper does not fully address potential limitations and drawbacks of this approach:
- The reliance on LLMs introduces additional complexity and computational cost, which may be challenging to deploy at scale.
- The quality of imputed data is crucial, and the paper does not extensively evaluate the accuracy and reliability of the data imputation process.
- There may be privacy and ethical concerns around using LLMs trained on large, potentially biased datasets to power recommendation systems.
Further research is needed to address these concerns and explore ways to more seamlessly integrate LLMs into recommendation systems while maintaining performance, efficiency, and responsible deployment.
Conclusion
This paper demonstrates how large language models can be leveraged to enhance recommendation systems by improving semantic understanding and enabling data imputation. By capturing deep item relationships and filling in missing information, the proposed framework can potentially lead to more accurate, personalized, and efficient recommendations.
While the approach shows promise, there are still challenges to address around complexity, data quality, and ethical considerations. Continued research and development in this area could further advance the state of the art in recommendation systems and unlock new possibilities for AI-powered personalization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Semantic Understanding and Data Imputation using Large Language Model to Accelerate Recommendation System
Zhicheng Ding, Jiahao Tian, Zhenkai Wang, Jinman Zhao, Siyang Li
This paper aims to address the challenge of sparse and missing data in recommendation systems, a significant hurdle in the age of big data. Traditional imputation methods struggle to capture complex relationships within the data. We propose a novel approach that fine-tune Large Language Model (LLM) and use it impute missing data for recommendation systems. LLM which is trained on vast amounts of text, is able to understand complex relationship among data and intelligently fill in missing information. This enriched data is then used by the recommendation system to generate more accurate and personalized suggestions, ultimately enhancing the user experience. We evaluate our LLM-based imputation method across various tasks within the recommendation system domain, including single classification, multi-classification, and regression compared to traditional data imputation methods. By demonstrating the superiority of LLM imputation over traditional methods, we establish its potential for improving recommendation system performance.
Read more7/16/2024
0
Item-Language Model for Conversational Recommendation
Li Yang, Anushya Subbiah, Hardik Patel, Judith Yue Li, Yanwei Song, Reza Mirghaderi, Vikram Aggarwal
Large-language Models (LLMs) have been extremely successful at tasks like complex dialogue understanding, reasoning and coding due to their emergent abilities. These emergent abilities have been extended with multi-modality to include image, audio, and video capabilities. Recommender systems, on the other hand, have been critical for information seeking and item discovery needs. Recently, there have been attempts to apply LLMs for recommendations. One difficulty of current attempts is that the underlying LLM is usually not trained on the recommender system data, which largely contains user interaction signals and is often not publicly available. Another difficulty is user interaction signals often have a different pattern from natural language text, and it is currently unclear if the LLM training setup can learn more non-trivial knowledge from interaction signals compared with traditional recommender system methods. Finally, it is difficult to train multiple LLMs for different use-cases, and to retain the original language and reasoning abilities when learning from recommender system data. To address these three limitations, we propose an Item-Language Model (ILM), which is composed of an item encoder to produce text-aligned item representations that encode user interaction signals, and a frozen LLM that can understand those item representations with preserved pretrained knowledge. We conduct extensive experiments which demonstrate both the importance of the language-alignment and of user interaction knowledge in the item encoder.
Read more6/6/2024
💬
0
Knowledge Adaptation from Large Language Model to Recommendation for Practical Industrial Application
Jian Jia, Yipei Wang, Yan Li, Honggang Chen, Xuehan Bai, Zhaocheng Liu, Jian Liang, Quan Chen, Han Li, Peng Jiang, Kun Gai
Contemporary recommender systems predominantly rely on collaborative filtering techniques, employing ID-embedding to capture latent associations among users and items. However, this approach overlooks the wealth of semantic information embedded within textual descriptions of items, leading to suboptimal performance in cold-start scenarios and long-tail user recommendations. Leveraging the capabilities of Large Language Models (LLMs) pretrained on massive text corpus presents a promising avenue for enhancing recommender systems by integrating open-world domain knowledge. In this paper, we propose an Llm-driven knowlEdge Adaptive RecommeNdation (LEARN) framework that synergizes open-world knowledge with collaborative knowledge. We address computational complexity concerns by utilizing pretrained LLMs as item encoders and freezing LLM parameters to avoid catastrophic forgetting and preserve open-world knowledge. To bridge the gap between the open-world and collaborative domains, we design a twin-tower structure supervised by the recommendation task and tailored for practical industrial application. Through offline experiments on the large-scale industrial dataset and online experiments on A/B tests, we demonstrate the efficacy of our approach.
Read more5/8/2024
💬
1
A Survey on Large Language Models for Recommendation
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, Hui Xiong, Enhong Chen
Large Language Models (LLMs) have emerged as powerful tools in the field of Natural Language Processing (NLP) and have recently gained significant attention in the domain of Recommendation Systems (RS). These models, trained on massive amounts of data using self-supervised learning, have demonstrated remarkable success in learning universal representations and have the potential to enhance various aspects of recommendation systems by some effective transfer techniques such as fine-tuning and prompt tuning, and so on. The crucial aspect of harnessing the power of language models in enhancing recommendation quality is the utilization of their high-quality representations of textual features and their extensive coverage of external knowledge to establish correlations between items and users. To provide a comprehensive understanding of the existing LLM-based recommendation systems, this survey presents a taxonomy that categorizes these models into two major paradigms, respectively Discriminative LLM for Recommendation (DLLM4Rec) and Generative LLM for Recommendation (GLLM4Rec), with the latter being systematically sorted out for the first time. Furthermore, we systematically review and analyze existing LLM-based recommendation systems within each paradigm, providing insights into their methodologies, techniques, and performance. Additionally, we identify key challenges and several valuable findings to provide researchers and practitioners with inspiration. We have also created a GitHub repository to index relevant papers on LLMs for recommendation, https://github.com/WLiK/LLM4Rec.
Read more6/19/2024