Semantically-Shifted Incremental Adapter-Tuning is A Continual ViTransformer

0
Sign in to get full access
Introduction
The provided text discusses the challenges of class-incremental learning (CIL) compared to traditional deep learning. In traditional deep learning, the model can access all the data at once and learning is performed on a static dataset. However, in real-world applications, data usually arrives in a stream format with new classes, requiring the model to learn continuously.
The primary objective of CIL is to enable the model to learn continuously from non-stationary data streams, facilitating adaptation to new classes and mitigating catastrophic forgetting. Several methods have been proposed to alleviate catastrophic forgetting, such as replay-based, regularization-based, and isolation-based approaches. However, these methods assume that models are trained from scratch, while ignoring the potential benefits of using a strong pre-trained model in the CIL setting.
The text summarizes recent research on using pre-trained vision transformer models for continual incremental learning (CIL). Key points:
- Pre-trained vision transformer models have shown excellent performance on various vision tasks and are being explored for CIL.
- CIL methods based on pre-trained models can achieve significant performance improvements over traditional SOTA methods trained from scratch.
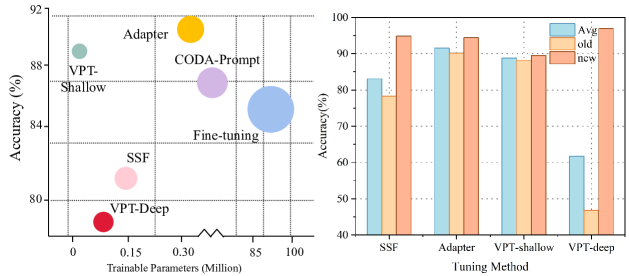
- CIL with pre-trained models typically uses parameter-efficient tuning (PET) approaches like adapters, prompts, and semantic soft projection (SSF), rather than fully fine-tuning the entire model.
- Prompt-based PET methods require constructing a pool of task-specific prompts, which increases storage and computation overhead.
- Other PET methods like adapter tuning are shown to be better continual learners than prompt tuning or SSF, avoiding catastrophic forgetting of old classes.
- The paper proposes a new approach that fine-tunes only the adapter and a task-specific classifier, without regularization, and retrains the classifier using semantic shift-based prototype updates.
- Extensive experiments demonstrate this simple but effective approach achieves state-of-the-art performance on CIL benchmarks.
Related Work
The provided text discusses various approaches to class-incremental learning (CIL) and parameter-efficient tuning (PET) on pre-trained models.
CIL requires the model to be continuously updated with new class instances while retaining old knowledge. Traditional CIL methods can be categorized into replay-based, regularization-based, and parameter isolation-based. Replay-based methods involve retaining or generating samples of previous classes. Regularization-based methods add constraints to limit the update of parameters important for old classes. Isolation-based methods focus on updating only a subset of parameters to mitigate catastrophic forgetting. Methods have also been proposed to expand the network's representative capacity without compromising existing knowledge.
PET refers to inserting and fine-tuning specific sub-modules within a pre-trained network, rather than performing full fine-tuning. This approach has shown effective transfer learning results in both NLP and vision transformer models. Prompt-based PET methods have also been applied to vision-language models.
The text also discusses CIL methods that involve pre-trained models, such as L2P, DualPrompt, CODAPrompt, SLCA, Adam, and LAE. These methods utilize the strong feature representation ability of pre-trained models and employ various strategies to learn new tasks while retaining old knowledge.
Methodology
The paper introduces a class-incremental learning (CIL) formulation where a neural network must learn a series of training sessions while avoiding catastrophic forgetting of previous classes. The authors propose a baseline approach that incrementally tunes a shared adapter module without parameter constraints, which outperforms other parameter-efficient tuning methods like prompt tuning and scale-and-shift factors.
The authors analyze why the adapter-based approach is effective for CIL. They show that constraining parameter updates to mitigate forgetting can hinder the plasticity needed to learn new classes, as the sensitivity of parameters is similar across tasks. The authors then introduce a semantic shift estimation technique to align classifiers across learning sessions without access to past samples.
Experimental results on several CIL benchmarks demonstrate the effectiveness of the proposed baseline approach, which achieves state-of-the-art performance compared to existing parameter-efficient tuning methods.
Experiments
Conclusion
Appendix
A. More experiments on parameter sensitivity

B. More Ablation Experiments
More Implementation Details
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Semantically-Shifted Incremental Adapter-Tuning is A Continual ViTransformer
Yuwen Tan, Qinhao Zhou, Xiang Xiang, Ke Wang, Yuchuan Wu, Yongbin Li
Class-incremental learning (CIL) aims to enable models to continuously learn new classes while overcoming catastrophic forgetting. The introduction of pre-trained models has brought new tuning paradigms to CIL. In this paper, we revisit different parameter-efficient tuning (PET) methods within the context of continual learning. We observe that adapter tuning demonstrates superiority over prompt-based methods, even without parameter expansion in each learning session. Motivated by this, we propose incrementally tuning the shared adapter without imposing parameter update constraints, enhancing the learning capacity of the backbone. Additionally, we employ feature sampling from stored prototypes to retrain a unified classifier, further improving its performance. We estimate the semantic shift of old prototypes without access to past samples and update stored prototypes session by session. Our proposed method eliminates model expansion and avoids retaining any image samples. It surpasses previous pre-trained model-based CIL methods and demonstrates remarkable continual learning capabilities. Experimental results on five CIL benchmarks validate the effectiveness of our approach, achieving state-of-the-art (SOTA) performance.
Read more4/1/2024
↗️
0
Class-Incremental Learning: A Survey
Da-Wei Zhou, Qi-Wei Wang, Zhi-Hong Qi, Han-Jia Ye, De-Chuan Zhan, Ziwei Liu
Deep models, e.g., CNNs and Vision Transformers, have achieved impressive achievements in many vision tasks in the closed world. However, novel classes emerge from time to time in our ever-changing world, requiring a learning system to acquire new knowledge continually. Class-Incremental Learning (CIL) enables the learner to incorporate the knowledge of new classes incrementally and build a universal classifier among all seen classes. Correspondingly, when directly training the model with new class instances, a fatal problem occurs -- the model tends to catastrophically forget the characteristics of former ones, and its performance drastically degrades. There have been numerous efforts to tackle catastrophic forgetting in the machine learning community. In this paper, we survey comprehensively recent advances in class-incremental learning and summarize these methods from several aspects. We also provide a rigorous and unified evaluation of 17 methods in benchmark image classification tasks to find out the characteristics of different algorithms empirically. Furthermore, we notice that the current comparison protocol ignores the influence of memory budget in model storage, which may result in unfair comparison and biased results. Hence, we advocate fair comparison by aligning the memory budget in evaluation, as well as several memory-agnostic performance measures. The source code is available at https://github.com/zhoudw-zdw/CIL_Survey/
Read more7/16/2024
🌿
0
Parameter-Efficient Fine-Tuning With Adapters
Keyu Chen, Yuan Pang, Zi Yang
In the arena of language model fine-tuning, the traditional approaches, such as Domain-Adaptive Pretraining (DAPT) and Task-Adaptive Pretraining (TAPT), although effective, but computational intensive. This research introduces a novel adaptation method utilizing the UniPELT framework as a base and added a PromptTuning Layer, which significantly reduces the number of trainable parameters while maintaining competitive performance across various benchmarks. Our method employs adapters, which enable efficient transfer of pretrained models to new tasks with minimal retraining of the base model parameters. We evaluate our approach using three diverse datasets: the GLUE benchmark, a domain-specific dataset comprising four distinct areas, and the Stanford Question Answering Dataset 1.1 (SQuAD). Our results demonstrate that our customized adapter-based method achieves performance comparable to full model fine-tuning, DAPT+TAPT and UniPELT strategies while requiring fewer or equivalent amount of parameters. This parameter efficiency not only alleviates the computational burden but also expedites the adaptation process. The study underlines the potential of adapters in achieving high performance with significantly reduced resource consumption, suggesting a promising direction for future research in parameter-efficient fine-tuning.
Read more5/10/2024

0
FeTT: Continual Class Incremental Learning via Feature Transformation Tuning
Sunyuan Qiang, Xuxin Lin, Yanyan Liang, Jun Wan, Du Zhang
Continual learning (CL) aims to extend deep models from static and enclosed environments to dynamic and complex scenarios, enabling systems to continuously acquire new knowledge of novel categories without forgetting previously learned knowledge. Recent CL models have gradually shifted towards the utilization of pre-trained models (PTMs) with parameter-efficient fine-tuning (PEFT) strategies. However, continual fine-tuning still presents a serious challenge of catastrophic forgetting due to the absence of previous task data. Additionally, the fine-tune-then-frozen mechanism suffers from performance limitations due to feature channels suppression and insufficient training data in the first CL task. To this end, this paper proposes feature transformation tuning (FeTT) model to non-parametrically fine-tune backbone features across all tasks, which not only operates independently of CL training data but also smooths feature channels to prevent excessive suppression. Then, the extended ensemble strategy incorporating different PTMs with FeTT model facilitates further performance improvement. We further elaborate on the discussions of the fine-tune-then-frozen paradigm and the FeTT model from the perspectives of discrepancy in class marginal distributions and feature channels. Extensive experiments on CL benchmarks validate the effectiveness of our proposed method.
Read more5/21/2024