FeTT: Continual Class Incremental Learning via Feature Transformation Tuning

0

Sign in to get full access
Overview
- This paper, titled "FeTT: Continual Class Incremental Learning via Feature Transformation Tuning," proposes a novel approach to continual class incremental learning, which is the problem of learning new tasks or classes without forgetting previously learned ones.
- The key idea is to learn feature transformations that adapt the model's representations to new classes, without catastrophically forgetting information about previous classes.
- The authors evaluate their method, FeTT, on several benchmark continual learning datasets and show that it outperforms existing state-of-the-art approaches.
Plain English Explanation
In the field of machine learning, there is a challenge known as continual learning. This is the problem of teaching a model new skills or information without it forgetting what it has already learned. Imagine trying to teach a child new things - you wouldn't want them to completely forget everything they already knew!
The paper introduces a method called FeTT (Feature Transformation Tuning) to address this challenge. The key idea is that instead of just adding new information to the model, FeTT learns how to transform the model's existing "features" (the internal representations it has learned) to adapt to new classes or tasks. This allows the model to incorporate new knowledge while preserving what it has already learned, preventing the dreaded "catastrophic forgetting."
The authors test FeTT on several standard continual learning benchmarks and show that it outperforms other state-of-the-art methods. This suggests that their approach of learning adaptive feature transformations is an effective way to tackle the continual learning problem.
Technical Explanation
The paper introduces a method called FeTT: Feature Transformation Tuning for continual class incremental learning. The core idea is to learn feature transformations that adapt the model's internal representations to new classes, without catastrophically forgetting information about previous classes.
Specifically, the authors propose a two-stage training process. First, they train a base model on an initial set of classes. Then, when presented with a new set of classes, they learn a feature transformation module that maps the base model's representations to the new class-specific features. This transformation is learned end-to-end alongside the classification head for the new classes.
The key advantage of this approach is that it allows the model to incorporate new knowledge without overwriting the original learned representations. The feature transformation acts as an "adapter" that can be applied to the base model, enabling it to recognize the new classes while retaining its knowledge of the old ones.
The authors evaluate FeTT on several standard continual learning benchmarks, including Split CIFAR-100, iCIFAR-100, and Tiny ImageNet. They show that FeTT outperforms existing state-of-the-art continual learning methods, demonstrating the effectiveness of their feature transformation approach.
Critical Analysis
The paper presents a compelling approach to the continual learning problem, and the experimental results are impressive. However, there are a few potential limitations and areas for further research:
-
Scalability to large-scale models: The experiments in the paper focus on relatively small-scale image classification tasks. It remains to be seen how well the FeTT approach would scale to larger and more complex models, such as large language models.
-
Generalization to diverse task domains: The paper only evaluates FeTT on image classification tasks. It would be interesting to see how well the method generalizes to other types of machine learning problems, such as natural language processing or reinforcement learning.
-
Efficiency of feature transformations: The paper does not provide a detailed analysis of the computational and memory overhead of learning and applying the feature transformations. As models become larger and more complex, the efficiency of this process will be an important consideration.
-
Interpretability of feature transformations: While the feature transformations are effective at enabling continual learning, it would be valuable to better understand the nature of these transformations and how they interact with the base model's representations.
Overall, the FeTT approach represents an important contribution to the field of continual learning, and the authors have demonstrated its effectiveness on several benchmark tasks. Further research exploring the scalability, generalization, and interpretability of this method could lead to important advancements in the field.
Conclusion
The paper "FeTT: Continual Class Incremental Learning via Feature Transformation Tuning" presents a novel approach to the problem of continual class incremental learning. By learning feature transformations that adapt the model's internal representations to new classes, FeTT is able to incorporate new knowledge without catastrophically forgetting previous information.
The authors' experiments show that FeTT outperforms existing state-of-the-art continual learning methods on several standard benchmarks. This suggests that the feature transformation approach is a promising direction for addressing the continual learning challenge, which is a crucial aspect of building truly intelligent and adaptable AI systems.
While the paper focuses on image classification tasks, the FeTT method could potentially be extended to other domains, and further research is needed to explore its scalability and generalizability. Nonetheless, this work represents an important advancement in the field of continual learning and lays the groundwork for future developments in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FeTT: Continual Class Incremental Learning via Feature Transformation Tuning
Sunyuan Qiang, Xuxin Lin, Yanyan Liang, Jun Wan, Du Zhang
Continual learning (CL) aims to extend deep models from static and enclosed environments to dynamic and complex scenarios, enabling systems to continuously acquire new knowledge of novel categories without forgetting previously learned knowledge. Recent CL models have gradually shifted towards the utilization of pre-trained models (PTMs) with parameter-efficient fine-tuning (PEFT) strategies. However, continual fine-tuning still presents a serious challenge of catastrophic forgetting due to the absence of previous task data. Additionally, the fine-tune-then-frozen mechanism suffers from performance limitations due to feature channels suppression and insufficient training data in the first CL task. To this end, this paper proposes feature transformation tuning (FeTT) model to non-parametrically fine-tune backbone features across all tasks, which not only operates independently of CL training data but also smooths feature channels to prevent excessive suppression. Then, the extended ensemble strategy incorporating different PTMs with FeTT model facilitates further performance improvement. We further elaborate on the discussions of the fine-tune-then-frozen paradigm and the FeTT model from the perspectives of discrepancy in class marginal distributions and feature channels. Extensive experiments on CL benchmarks validate the effectiveness of our proposed method.
Read more5/21/2024
0
Parameter-Efficient Fine-Tuning for Continual Learning: A Neural Tangent Kernel Perspective
Jingren Liu, Zhong Ji, YunLong Yu, Jiale Cao, Yanwei Pang, Jungong Han, Xuelong Li
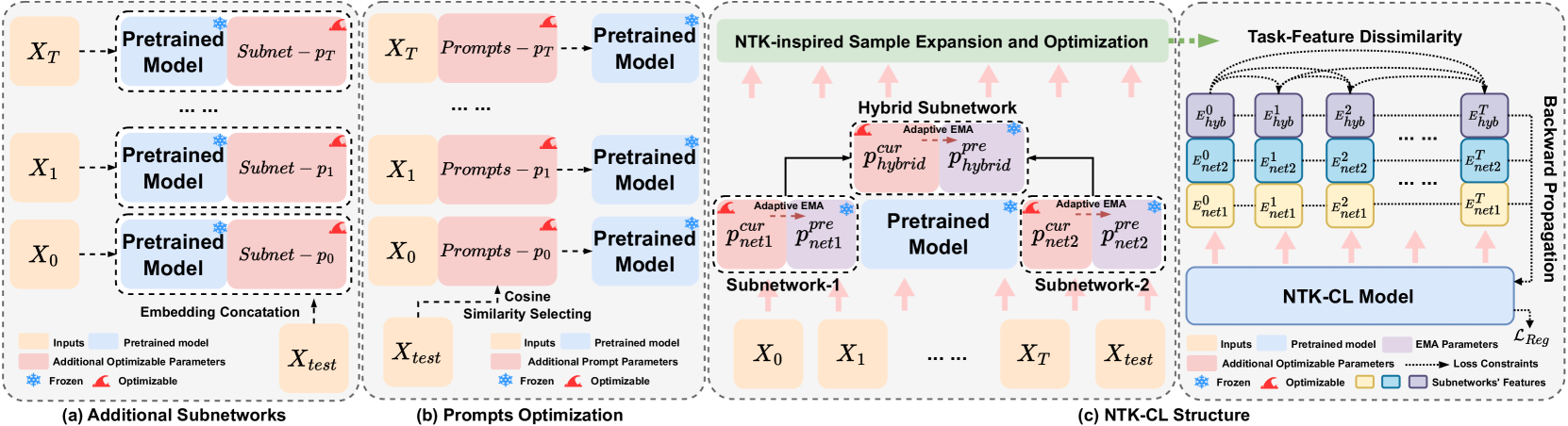
Parameter-efficient fine-tuning for continual learning (PEFT-CL) has shown promise in adapting pre-trained models to sequential tasks while mitigating catastrophic forgetting problem. However, understanding the mechanisms that dictate continual performance in this paradigm remains elusive. To tackle this complexity, we undertake a rigorous analysis of PEFT-CL dynamics to derive relevant metrics for continual scenarios using Neural Tangent Kernel (NTK) theory. With the aid of NTK as a mathematical analysis tool, we recast the challenge of test-time forgetting into the quantifiable generalization gaps during training, identifying three key factors that influence these gaps and the performance of PEFT-CL: training sample size, task-level feature orthogonality, and regularization. To address these challenges, we introduce NTK-CL, a novel framework that eliminates task-specific parameter storage while adaptively generating task-relevant features. Aligning with theoretical guidance, NTK-CL triples the feature representation of each sample, theoretically and empirically reducing the magnitude of both task-interplay and task-specific generalization gaps. Grounded in NTK analysis, our approach imposes an adaptive exponential moving average mechanism and constraints on task-level feature orthogonality, maintaining intra-task NTK forms while attenuating inter-task NTK forms. Ultimately, by fine-tuning optimizable parameters with appropriate regularization, NTK-CL achieves state-of-the-art performance on established PEFT-CL benchmarks. This work provides a theoretical foundation for understanding and improving PEFT-CL models, offering insights into the interplay between feature representation, task orthogonality, and generalization, contributing to the development of more efficient continual learning systems.
Read more7/25/2024

0
Reflecting on the State of Rehearsal-free Continual Learning with Pretrained Models
Lukas Thede, Karsten Roth, Olivier J. H'enaff, Matthias Bethge, Zeynep Akata
With the advent and recent ubiquity of foundation models, continual learning (CL) has recently shifted from continual training from scratch to the continual adaptation of pretrained models, seeing particular success on rehearsal-free CL benchmarks (RFCL). To achieve this, most proposed methods adapt and restructure parameter-efficient finetuning techniques (PEFT) to suit the continual nature of the problem. Based most often on input-conditional query-mechanisms or regularizations on top of prompt- or adapter-based PEFT, these PEFT-style RFCL (P-RFCL) approaches report peak performances; often convincingly outperforming existing CL techniques. However, on the other end, critical studies have recently highlighted competitive results by training on just the first task or via simple non-parametric baselines. Consequently, questions arise about the relationship between methodological choices in P-RFCL and their reported high benchmark scores. In this work, we tackle these questions to better understand the true drivers behind strong P-RFCL performances, their placement w.r.t. recent first-task adaptation studies, and their relation to preceding CL standards such as EWC or SI. In particular, we show: (1) P-RFCL techniques relying on input-conditional query mechanisms work not because, but rather despite them by collapsing towards standard PEFT shortcut solutions. (2) Indeed, we show how most often, P-RFCL techniques can be matched by a simple and lightweight PEFT baseline. (3) Using this baseline, we identify the implicit bound on tunable parameters when deriving RFCL approaches from PEFT methods as a potential denominator behind P-RFCL efficacy. Finally, we (4) better disentangle continual versus first-task adaptation, and (5) motivate standard RFCL techniques s.a. EWC or SI in light of recent P-RFCL methods.
Read more6/14/2024

0
Learning to Learn without Forgetting using Attention
Anna Vettoruzzo, Joaquin Vanschoren, Mohamed-Rafik Bouguelia, Thorsteinn Rognvaldsson
Continual learning (CL) refers to the ability to continually learn over time by accommodating new knowledge while retaining previously learned experience. While this concept is inherent in human learning, current machine learning methods are highly prone to overwrite previously learned patterns and thus forget past experience. Instead, model parameters should be updated selectively and carefully, avoiding unnecessary forgetting while optimally leveraging previously learned patterns to accelerate future learning. Since hand-crafting effective update mechanisms is difficult, we propose meta-learning a transformer-based optimizer to enhance CL. This meta-learned optimizer uses attention to learn the complex relationships between model parameters across a stream of tasks, and is designed to generate effective weight updates for the current task while preventing catastrophic forgetting on previously encountered tasks. Evaluations on benchmark datasets like SplitMNIST, RotatedMNIST, and SplitCIFAR-100 affirm the efficacy of the proposed approach in terms of both forward and backward transfer, even on small sets of labeled data, highlighting the advantages of integrating a meta-learned optimizer within the continual learning framework.
Read more8/15/2024