SemEval-2024 Shared Task 6: SHROOM, a Shared-task on Hallucinations and Related Observable Overgeneration Mistakes
2403.07726
0
0
Abstract
This paper presents the results of the SHROOM, a shared task focused on detecting hallucinations: outputs from natural language generation (NLG) systems that are fluent, yet inaccurate. Such cases of overgeneration put in jeopardy many NLG applications, where correctness is often mission-critical. The shared task was conducted with a newly constructed dataset of 4000 model outputs labeled by 5 annotators each, spanning 3 NLP tasks: machine translation, paraphrase generation and definition modeling. The shared task was tackled by a total of 58 different users grouped in 42 teams, out of which 27 elected to write a system description paper; collectively, they submitted over 300 prediction sets on both tracks of the shared task. We observe a number of key trends in how this approach was tackled -- many participants rely on a handful of model, and often rely either on synthetic data for fine-tuning or zero-shot prompting strategies. While a majority of the teams did outperform our proposed baseline system, the performances of top-scoring systems are still consistent with a random handling of the more challenging items.
Create account to get full access
Introduction
The modern natural language generation (NLG) landscape faces two interlinked problems. Current neural models tend to produce fluent but inaccurate outputs. At the same time, the metrics used to evaluate these models are better suited for measuring fluency rather than correctness. This leads neural networks to "hallucinate" - produce fluent but incorrect outputs that are difficult to detect automatically.
For example, when trying to paraphrase the input "I am not sure where my phone is", the model instead generated the output "How can I find the location of any Android mobile." For many NLG applications, the correctness of the output is crucial. Producing plausible-sounding but inconsistent translations can undermine the usefulness of a machine translation system.
![]()
The paper organizes a shared task on Hallucinations and Related Observable Overgeneration Mistakes, or SHROOM. The goal is to foster interest in this topic by inviting participants to perform binary classification to identify cases of fluent overgeneration hallucinations. The task involves a post hoc setting, where models have already been trained and outputs already produced. Participants must detect grammatically sound outputs which contain incorrect or unsupported semantic information, with or without access to the model that produced the output. The dataset consists of checkpoints, inputs, references and outputs of systems covering three different NLG tasks: definition modeling, machine translation, and paraphrase generation.
The task aims to establish whether hallucinations are best construed as a categorical or gradient phenomenon. Participants are scored on both accuracy and calibration. The shared task attracted a total of 58 different users grouped in 42 teams, with 27 writing system description papers. A large pool of participants allows the identification of key trends in how the task was tackled, with many relying on synthetic data or zero-shot prompting strategies. While most teams outperformed the baseline, the performances of top-scoring systems are still consistent with a random handling of the more challenging items. The paper provides an overview of the current research landscape, defines the theoretical framework, and summarizes the data collection process before presenting and discussing the shared task results.
Connecting with the past: related works and state of the art
The provided text discusses the issue of hallucinations in natural language generation (NLG) models. It notes that while hallucinations are widely recognized as a problem, there is a lack of consensus on the optimal framework for addressing it. This is due in part to the diversity of tasks that NLG encompasses.
The text then critiques a proposed taxonomy of hallucinations by Guerreiro et al. (2023), finding it inadequate for several reasons. These include conflating fluency and semantic correctness, focusing only on extreme cases of hallucinations, and limiting the scope to machine translation (MT) tasks.
The text also examines alternative studies that have attempted to address hallucination detection, such as the HaluEval benchmark proposed by Li et al. (2023). However, these studies are found to have their own limitations, such as requiring annotators to search the internet for facts or working with closed, non-transparent commercial language models.
Overall, the text highlights the lack of a comprehensive and effective framework for addressing the problem of hallucinations in NLG models, and calls for further research and development in this area.
Tripping over hallucinations: task definition and annotation
This paper focuses on cases of fluent overgeneration, where model outputs contain information not present in the input reference. The authors use inferential semantics to determine if an output can be inferred from the reference, in which case it is considered a semantically sound inference rather than overgeneration.
The paper introduces the SHROOM task which considers two key distinctions: model-aware vs. model-agnostic approaches, and source-referential vs. dual-referential datapoints. Model-aware approaches can lead to more accurate diagnoses but may not be practical for end users. Source-referential tasks, like summarization, are excluded due to annotation challenges.
The paper provides multiple semantic annotations and a gold majority label for each datapoint, given the low consensus in semantic annotations reported in prior work. An example datapoint is presented, which includes the input source, target, model output, task type, referentiality, annotations, gold label, and proportion of annotators labeling it as a hallucination. For the model-aware track, the model name is also provided.
Foraging and harvesting season: Collected data
The SHROOM dataset consists of annotated test and development sets, as well as unlabeled training data, for three sequence-to-generation tasks: dialogue modeling (DM), machine translation (MT), and paraphrase generation (PG). The data and models used to generate the outputs are available under a CC-BY license.
To ensure the test and development sets contain a range of output quality, the researchers pre-filtered the outputs using automated metrics like perplexity and BERTScore. For the model-aware tracks, the researchers manually selected fluent outputs. The annotation process involved five annotators per item judging whether the output was supported by the reference.
Analysis of the annotation distributions reveals several key points:
- There is not a clear consensus among annotators on whether an output is hallucinated or not. Many items have intermediate annotation distributions, rather than being clearly labeled as hallucinated or not.
- Hallucinations are relatively rare, especially for the PG task. The DM task tends to have more hallucinated outputs than MT, which in turn has more than PG. This suggests task complexity is related to hallucination rates.
- The annotation distributions are broadly similar between the model-aware and model-agnostic tracks, indicating the key differences are at the task level rather than the model level.
They got so high: shared task results
The competition was held via Codalab. The leaderboard was left hidden during the evaluation phase, but participants were allowed to make a high number of submissions (50). Systems are evaluated on accuracy and calibration.
A baseline system using an LLM is presented. On the model-agnostic track, the baseline achieves an accuracy of 0.697 and calibration of 0.403. On the model-aware track, the accuracy is 0.745 and calibration is 0.488.
A total of 59 individual users grouped in 42 teams participated, with 27 writing system description papers. 512 submissions were received, with 368 being successful.
The top performing teams and their results are presented in two tables, one for the model-agnostic track and one for the model-aware track. Top teams achieve accuracies around 0.84-0.85 and calibration around 0.72-0.77.
The paper notes a high correlation between accuracy and calibration scores, suggesting participants could not effectively leverage the supplementary data available in the model-aware track. It also discusses a performance ceiling, with the most effective systems still misclassifying 15-19% of items.
A bunch of fun guys: qualitative analysis of participants systems
The analysis is based on system description papers as well as self-reports from a small number of participants who chose not to fully describe their systems. This covers 33 out of the 42 teams that took part in the shared task, with 6 of these not providing a complete description. More details are available in Table 2 in the Appendix.

The teams used a variety of methods to address the hallucination detection problem, including ensemble techniques, fine-tuning pre-trained language models (LLMs), and prompt engineering. Most teams used popular pre-trained LLMs such as GPT, LLaMA, DeBERTa, RoBERTa, and XLM-RoBERTa. The Vectara hallucination evaluation model was particularly popular, with over a quarter of teams reporting its use.
The approaches covered a wide range, from fine-tuning on hallucination data or optimizing with prompts, to in-context learning with role-playing, automatic prompt generation, and ensemble methods. Some teams focused on zero-shot and few-shot approaches, while others used synthetic data generation and semi-supervised learning.
The top-scoring systems tend to use fine-tuning or ensembling, suggesting high performance requires adapting existing models rather than using them out-of-the-box. Several top teams used the closed-source GPT-3.5 and GPT-4 models, but this was not a strict requirement, as one high-ranking team did not use these models.
Another trend observed is that the number of submissions per team is inversely correlated with their final rank, indicating that more thorough involvement, both in model training and prediction set submissions, tends to yield better results.
Overall, the high diversity of methods highlights the complexity of hallucination detection, even within the simple inferential semantics framework of this task.
Much room to grow: conclusions and future perspectives
The SHROOM shared task focused on detecting hallucinations in natural language generation (NLG) systems. The data showed hallucinations exist on a spectrum, and different people have varying opinions on what constitutes a hallucination. The task also highlighted that ambiguous items remain challenging, and current state-of-the-art systems can perform no better than random guesses in these cases.
The diversity of methodologies used by participants underscores that out-of-the-box solutions are insufficient - the top-performing teams relied on techniques like fine-tuning and model ensembling. Access to model parameters provided limited help, as few teams attempted model-specific investigations, and performance was lower in the model-aware track compared to the model-agnostic track.
Several important questions remain to be answered, such as how these results translate to larger, better-trained language models, whether sentence-level predictions can identify token-level issues, and whether the difficulties observed in English extend to other languages. Answering these questions will require further research, potentially through future iterations of this shared task.
Overall, the success of this task is attributed to the committed participation of over 350 submissions from around the world, providing a useful snapshot of the current state of the field and the gaps that need to be addressed.
oing SHROOM responsibly: ethical considerations
The text summarizes the broader impact and data considerations for a study on detecting hallucinated outputs from large language models. The key points are:
Detecting hallucinated outputs is important to mitigate the spread of disinformation and misleading narratives, contributing to the development of more trustworthy generative language models.
The annotators were suitably compensated for their work. However, the dataset released may contain false or misleading statements, especially in the unannotated portions. The annotated data labels these statements, but the unannotated parts may also contain offensive, obscene, or otherwise problematic content, as no special precautions were taken for that portion.
Acknowledgments
The construction of the SHROOM dataset was made possible by a grant from the Oskar Öfflund Foundation. This work is also supported by the ICT 2023 project "Uncertainty-aware neural language models" funded by the Academy of Finland (grant agreement № 345999). Computational resources were provided by the CSC-IT Center for Science Ltd. The shared task logo uses the "Retro Cool" font from Nirmana Visual, which is available for personal and non-commercial uses.
Appendix A Shared consciousnesses: Overview of approaches used by SHROOM teams
Table 2 presents a summary of the different teams, the models and datasets they used, and a brief description of their approach. This provides an overview of the various methods and resources employed by the teams.
Appendix B Annotation guidelines
The paper includes an exact copy of the annotation guidelines given to the annotators in Figure 8.

This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

AILS-NTUA at SemEval-2024 Task 6: Efficient model tuning for hallucination detection and analysis
Natalia Grigoriadou, Maria Lymperaiou, Giorgos Filandrianos, Giorgos Stamou
0
0
In this paper, we present our team's submissions for SemEval-2024 Task-6 - SHROOM, a Shared-task on Hallucinations and Related Observable Overgeneration Mistakes. The participants were asked to perform binary classification to identify cases of fluent overgeneration hallucinations. Our experimentation included fine-tuning a pre-trained model on hallucination detection and a Natural Language Inference (NLI) model. The most successful strategy involved creating an ensemble of these models, resulting in accuracy rates of 77.8% and 79.9% on model-agnostic and model-aware datasets respectively, outperforming the organizers' baseline and achieving notable results when contrasted with the top-performing results in the competition, which reported accuracies of 84.7% and 81.3% correspondingly.
4/15/2024

SHROOM-INDElab at SemEval-2024 Task 6: Zero- and Few-Shot LLM-Based Classification for Hallucination Detection
Bradley P. Allen, Fina Polat, Paul Groth
0
0
We describe the University of Amsterdam Intelligent Data Engineering Lab team's entry for the SemEval-2024 Task 6 competition. The SHROOM-INDElab system builds on previous work on using prompt programming and in-context learning with large language models (LLMs) to build classifiers for hallucination detection, and extends that work through the incorporation of context-specific definition of task, role, and target concept, and automated generation of examples for use in a few-shot prompting approach. The resulting system achieved fourth-best and sixth-best performance in the model-agnostic track and model-aware tracks for Task 6, respectively, and evaluation using the validation sets showed that the system's classification decisions were consistent with those of the crowd-sourced human labellers. We further found that a zero-shot approach provided better accuracy than a few-shot approach using automatically generated examples. Code for the system described in this paper is available on Github.
4/8/2024
SLPL SHROOM at SemEval-2024 Task 06: A comprehensive study on models ability to detect hallucination
Pouya Fallah, Soroush Gooran, Mohammad Jafarinasab, Pouya Sadeghi, Reza Farnia, Amirreza Tarabkhah, Zainab Sadat Taghavi, Hossein Sameti
0
0
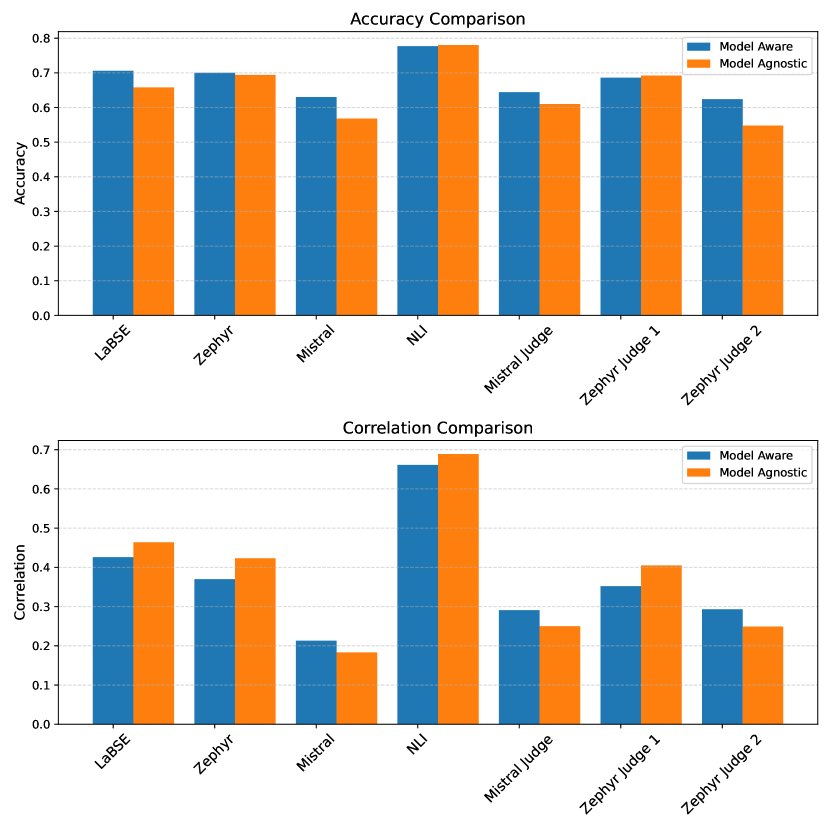
Language models, particularly generative models, are susceptible to hallucinations, generating outputs that contradict factual knowledge or the source text. This study explores methods for detecting hallucinations in three SemEval-2024 Task 6 tasks: Machine Translation, Definition Modeling, and Paraphrase Generation. We evaluate two methods: semantic similarity between the generated text and factual references, and an ensemble of language models that judge each other's outputs. Our results show that semantic similarity achieves moderate accuracy and correlation scores in trial data, while the ensemble method offers insights into the complexities of hallucination detection but falls short of expectations. This work highlights the challenges of hallucination detection and underscores the need for further research in this critical area.
4/10/2024
The Hallucinations Leaderboard -- An Open Effort to Measure Hallucinations in Large Language Models
Giwon Hong, Aryo Pradipta Gema, Rohit Saxena, Xiaotang Du, Ping Nie, Yu Zhao, Laura Perez-Beltrachini, Max Ryabinin, Xuanli He, Pasquale Minervini
0
0
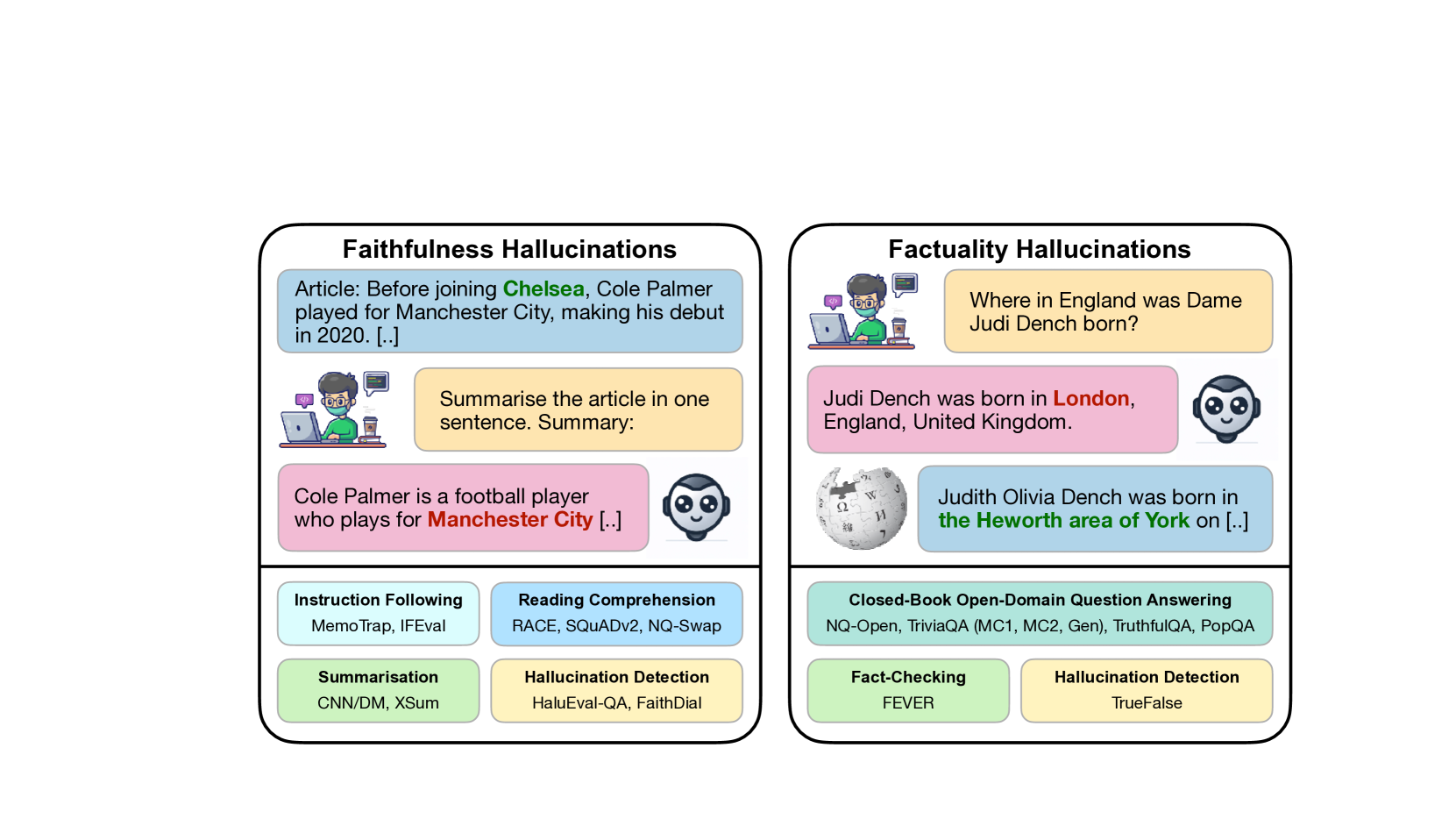
Large Language Models (LLMs) have transformed the Natural Language Processing (NLP) landscape with their remarkable ability to understand and generate human-like text. However, these models are prone to ``hallucinations'' -- outputs that do not align with factual reality or the input context. This paper introduces the Hallucinations Leaderboard, an open initiative to quantitatively measure and compare the tendency of each model to produce hallucinations. The leaderboard uses a comprehensive set of benchmarks focusing on different aspects of hallucinations, such as factuality and faithfulness, across various tasks, including question-answering, summarisation, and reading comprehension. Our analysis provides insights into the performance of different models, guiding researchers and practitioners in choosing the most reliable models for their applications.
4/10/2024