The Hallucinations Leaderboard -- An Open Effort to Measure Hallucinations in Large Language Models
2404.05904
0
0
Abstract
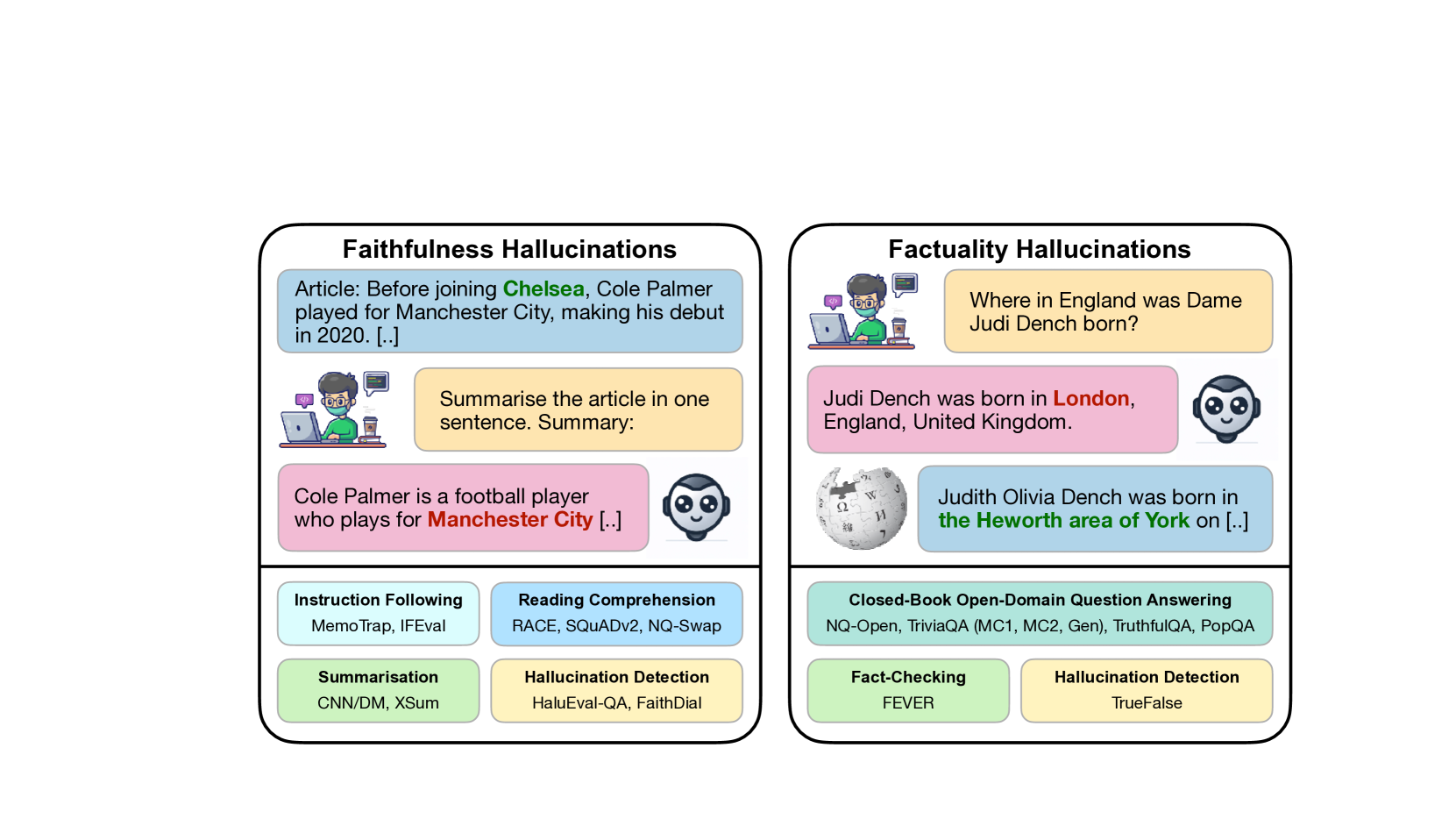
Large Language Models (LLMs) have transformed the Natural Language Processing (NLP) landscape with their remarkable ability to understand and generate human-like text. However, these models are prone to ``hallucinations'' -- outputs that do not align with factual reality or the input context. This paper introduces the Hallucinations Leaderboard, an open initiative to quantitatively measure and compare the tendency of each model to produce hallucinations. The leaderboard uses a comprehensive set of benchmarks focusing on different aspects of hallucinations, such as factuality and faithfulness, across various tasks, including question-answering, summarisation, and reading comprehension. Our analysis provides insights into the performance of different models, guiding researchers and practitioners in choosing the most reliable models for their applications.
Create account to get full access
Overview
- This paper introduces the Hallucinations Leaderboard, an open effort to measure hallucinations (generating content that is not supported by the input) in large language models (LLMs).
- The goal is to create a standardized benchmark for evaluating the factual accuracy and hallucination rates of different LLM models.
- The paper describes the evaluation framework, including techniques for measuring factuality and hallucination, and presents initial results from applying this framework to several popular LLMs.
Plain English Explanation
The paper discusses the Hallucinations Leaderboard, which is an open effort to measure how often large language models (LLMs) generate information that is not supported by their input. LLMs are powerful AI systems that can produce human-like text, but they can sometimes make up or "hallucinate" facts that are not true.
The researchers created a framework to evaluate the factual accuracy and hallucination rates of different LLMs. This involves testing the models on a variety of tasks and carefully measuring how often they provide information that is not grounded in the input. The goal is to establish a standardized benchmark that can be used to compare the reliability of different LLM models.
The paper presents the initial results of applying this evaluation framework to several well-known LLMs. This provides useful insights into the strengths and limitations of these models when it comes to generating factual and truthful content.
Technical Explanation
The paper introduces the Hallucinations Leaderboard, a new framework for measuring hallucinations in large language models. The researchers developed techniques to evaluate the factual accuracy and hallucination rates of LLMs across a variety of tasks.
The evaluation framework consists of two main components:
- Factuality Evaluation: This assesses whether the model's outputs accurately reflect information present in the input, using techniques like fact-checking and entity grounding.
- Hallucination Detection: This identifies instances where the model generates content that is not supported by the input, leveraging approaches like commonsense reasoning and knowledge base lookups.
The researchers applied this framework to several popular LLMs, including GPT-3, InstructGPT, and Meena. Their results reveal significant variability in factual accuracy and hallucination rates across the models, providing valuable insights into their strengths and limitations.
Critical Analysis
The Hallucinations Leaderboard represents an important step forward in addressing the issue of hallucinations in large language models. By establishing a standardized evaluation framework, the researchers have created a valuable tool for the research community to assess and compare the reliability of different LLMs.
However, the paper also acknowledges several limitations and areas for further research. For example, the current evaluation focuses primarily on factual accuracy and does not fully capture other important aspects of hallucinations, such as their diversity and impact on downstream tasks.
Additionally, the paper notes that the evaluation techniques used, while rigorous, may not be a perfect proxy for real-world performance. There is a need for continued refinement and validation of the evaluation methods to ensure they accurately reflect the models' behavior in practical applications.
Overall, the Hallucinations Leaderboard is a valuable contribution to the field of large language model research. By providing a standardized benchmark and shedding light on the hallucination tendencies of popular LLMs, the paper lays the groundwork for further improvements in model reliability and trustworthiness.
Conclusion
The Hallucinations Leaderboard is an important initiative to address the issue of hallucinations in large language models. By establishing a standardized evaluation framework, the researchers have created a tool that can be used to assess and compare the factual accuracy and hallucination rates of different LLMs.
The initial results presented in the paper provide valuable insights into the strengths and limitations of popular LLM models, highlighting the need for continued research and development to improve their reliability and trustworthiness. As the field of large language models continues to evolve, the Hallucinations Leaderboard will likely play a crucial role in guiding these efforts and ensuring that these powerful AI systems can be deployed safely and ethically.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, Wei Peng
0
0
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
5/7/2024
💬
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, Mike Zheng Shou
0
0
This survey presents a comprehensive analysis of the phenomenon of hallucination in multimodal large language models (MLLMs), also known as Large Vision-Language Models (LVLMs), which have demonstrated significant advancements and remarkable abilities in multimodal tasks. Despite these promising developments, MLLMs often generate outputs that are inconsistent with the visual content, a challenge known as hallucination, which poses substantial obstacles to their practical deployment and raises concerns regarding their reliability in real-world applications. This problem has attracted increasing attention, prompting efforts to detect and mitigate such inaccuracies. We review recent advances in identifying, evaluating, and mitigating these hallucinations, offering a detailed overview of the underlying causes, evaluation benchmarks, metrics, and strategies developed to address this issue. Additionally, we analyze the current challenges and limitations, formulating open questions that delineate potential pathways for future research. By drawing the granular classification and landscapes of hallucination causes, evaluation benchmarks, and mitigation methods, this survey aims to deepen the understanding of hallucinations in MLLMs and inspire further advancements in the field. Through our thorough and in-depth review, we contribute to the ongoing dialogue on enhancing the robustness and reliability of MLLMs, providing valuable insights and resources for researchers and practitioners alike. Resources are available at: https://github.com/showlab/Awesome-MLLM-Hallucination.
4/30/2024

Don't Believe Everything You Read: Enhancing Summarization Interpretability through Automatic Identification of Hallucinations in Large Language Models
Priyesh Vakharia, Devavrat Joshi, Meenal Chavan, Dhananjay Sonawane, Bhrigu Garg, Parsa Mazaheri
0
0
Large Language Models (LLMs) are adept at text manipulation -- tasks such as machine translation and text summarization. However, these models can also be prone to hallucination, which can be detrimental to the faithfulness of any answers that the model provides. Recent works in combating hallucinations in LLMs deal with identifying hallucinated sentences and categorizing the different ways in which models hallucinate. This paper takes a deep dive into LLM behavior with respect to hallucinations, defines a token-level approach to identifying different kinds of hallucinations, and further utilizes this token-level tagging to improve the interpretability and faithfulness of LLMs in dialogue summarization tasks. Through this, the paper presents a new, enhanced dataset and a new training paradigm.
4/4/2024
HaluEval-Wild: Evaluating Hallucinations of Language Models in the Wild
Zhiying Zhu, Yiming Yang, Zhiqing Sun
0
0
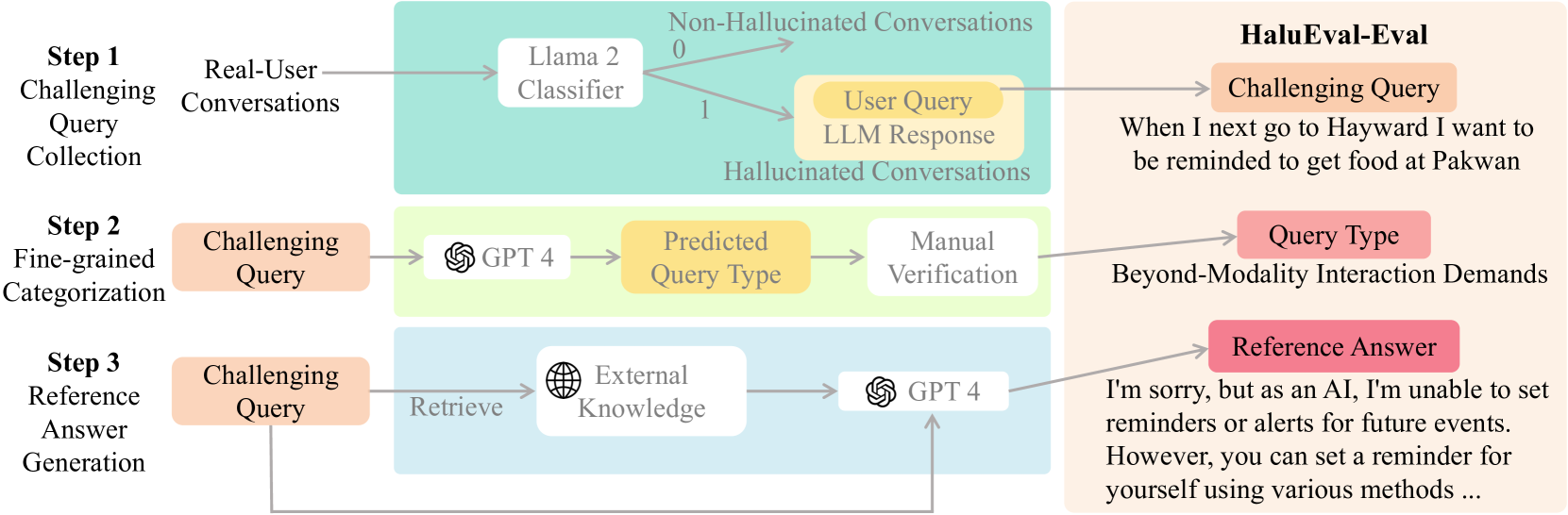
Hallucinations pose a significant challenge to the reliability of large language models (LLMs) in critical domains. Recent benchmarks designed to assess LLM hallucinations within conventional NLP tasks, such as knowledge-intensive question answering (QA) and summarization, are insufficient for capturing the complexities of user-LLM interactions in dynamic, real-world settings. To address this gap, we introduce HaluEval-Wild, the first benchmark specifically designed to evaluate LLM hallucinations in the wild. We meticulously collect challenging (adversarially filtered by Alpaca) user queries from existing real-world user-LLM interaction datasets, including ShareGPT, to evaluate the hallucination rates of various LLMs. Upon analyzing the collected queries, we categorize them into five distinct types, which enables a fine-grained analysis of the types of hallucinations LLMs exhibit, and synthesize the reference answers with the powerful GPT-4 model and retrieval-augmented generation (RAG). Our benchmark offers a novel approach towards enhancing our comprehension and improvement of LLM reliability in scenarios reflective of real-world interactions. Our benchmark is available at https://github.com/Dianezzy/HaluEval-Wild.
5/7/2024