SLPL SHROOM at SemEval-2024 Task 06: A comprehensive study on models ability to detect hallucination
2404.04845
0
0
Abstract
Language models, particularly generative models, are susceptible to hallucinations, generating outputs that contradict factual knowledge or the source text. This study explores methods for detecting hallucinations in three SemEval-2024 Task 6 tasks: Machine Translation, Definition Modeling, and Paraphrase Generation. We evaluate two methods: semantic similarity between the generated text and factual references, and an ensemble of language models that judge each other's outputs. Our results show that semantic similarity achieves moderate accuracy and correlation scores in trial data, while the ensemble method offers insights into the complexities of hallucination detection but falls short of expectations. This work highlights the challenges of hallucination detection and underscores the need for further research in this critical area.
Create account to get full access
Overview
- This paper presents a comprehensive study on the ability of language models to detect hallucination, which is the generation of factually incorrect information, in the context of the SemEval2024 Task 6.
- The researchers, from the SLPL SHROOM team, evaluate various models and techniques to address this important challenge in natural language generation and summarization.
- The paper explores knowledge-based and learning-based approaches to hallucination detection, and provides insights into the strengths and limitations of different methods.
Plain English Explanation
The provided research paper focuses on a crucial problem in artificial intelligence called "hallucination." Hallucination occurs when language models, like the ones used in chatbots or summarization tools, generate information that is factually incorrect or made up, rather than based on real facts.
The researchers from the SLPL SHROOM team looked at different ways to help these language models better detect when they are hallucinating, so they can avoid producing false information. They tested a variety of approaches, including ones that rely on existing knowledge and ones that learn from data.
The goal is to make language models more reliable and trustworthy, so people can use them with confidence, whether it's for summarizing long documents or having natural conversations. The insights from this study can help advance the field of natural language processing and generation, and improve the safety and accuracy of AI systems that interact with humans.
Technical Explanation
The SLPL SHROOM team's paper presents a comprehensive evaluation of different methods for detecting hallucination in language models, in the context of the SemEval2024 Task 6. Hallucination is the generation of factually incorrect information, which is a significant challenge in natural language generation and summarization.
The researchers explore both knowledge-based and learning-based approaches to hallucination detection. The knowledge-based methods leverage external knowledge sources, such as Wikipedia or Wikidata, to identify when the generated text contradicts known facts. The learning-based approaches, on the other hand, train models to directly detect hallucination based on patterns in the data, without relying on external knowledge.
The paper also explores the use of large language models and hallucination diversity-aware active learning techniques to improve the models' ability to detect hallucination.
Through extensive experiments, the researchers provide valuable insights into the strengths and limitations of different approaches, as well as the factors that influence hallucination detection performance.
Critical Analysis
The SLPL SHROOM paper presents a thorough and well-designed study on the important problem of hallucination detection in language models. The researchers have explored a range of techniques and provided a comprehensive evaluation, which is a valuable contribution to the field.
However, the paper does acknowledge certain limitations and areas for further research. For example, the knowledge-based approaches may be limited by the coverage and accuracy of the external knowledge sources, while the learning-based methods may struggle with rare or novel types of hallucination not present in the training data.
Additionally, the paper does not delve into the potential biases or ethical implications of hallucination detection systems, which could be an important consideration as these technologies become more widely deployed. It would be helpful for future research to address such concerns and explore ways to mitigate them.
Overall, the SLPL SHROOM team's work is a significant step forward in understanding and addressing the hallucination challenge, but there is still room for further research and development to ensure the safe and responsible use of these technologies.
Conclusion
The SLPL SHROOM paper presents a comprehensive study on the ability of language models to detect hallucination, which is the generation of factually incorrect information. The researchers explore a range of knowledge-based and learning-based approaches, providing valuable insights into the strengths and limitations of different techniques.
The findings from this study can contribute to the ongoing efforts to improve the reliability and trustworthiness of language models, which are becoming increasingly important in a wide range of applications, from chatbots to summarization tools. By enhancing the models' ability to detect and avoid hallucination, the research can help ensure that these AI systems provide accurate and reliable information, ultimately benefiting users and society.
While the paper offers significant advancements, it also highlights the need for further research to address the remaining challenges and potential ethical concerns associated with hallucination detection. Continued innovation in this area can lead to more robust and responsible natural language processing technologies that can be used with greater confidence and trust.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

AILS-NTUA at SemEval-2024 Task 6: Efficient model tuning for hallucination detection and analysis
Natalia Grigoriadou, Maria Lymperaiou, Giorgos Filandrianos, Giorgos Stamou
0
0
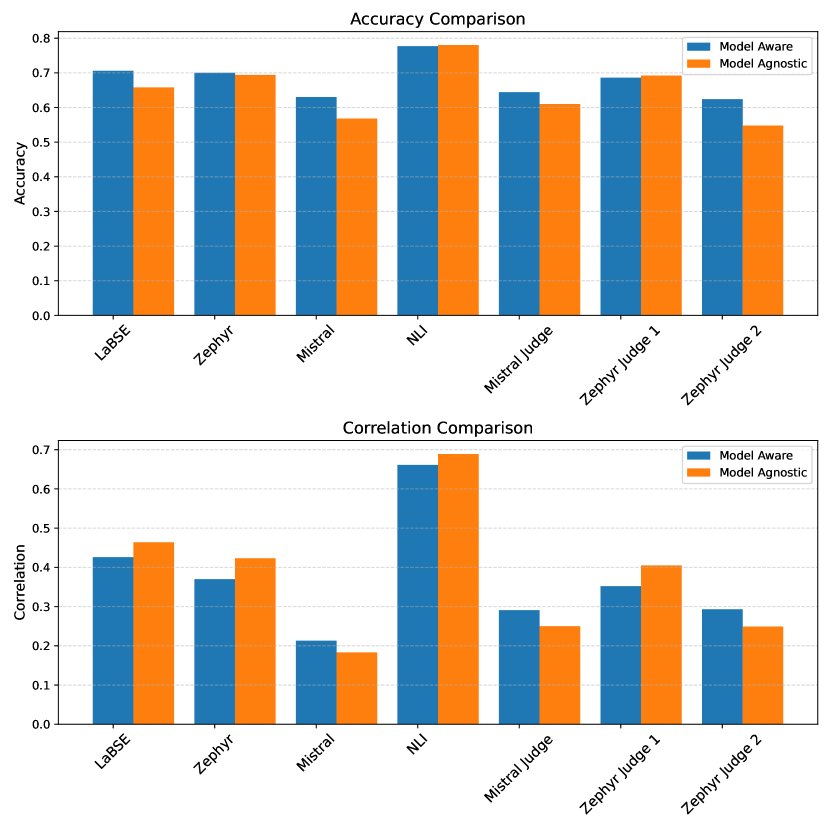
In this paper, we present our team's submissions for SemEval-2024 Task-6 - SHROOM, a Shared-task on Hallucinations and Related Observable Overgeneration Mistakes. The participants were asked to perform binary classification to identify cases of fluent overgeneration hallucinations. Our experimentation included fine-tuning a pre-trained model on hallucination detection and a Natural Language Inference (NLI) model. The most successful strategy involved creating an ensemble of these models, resulting in accuracy rates of 77.8% and 79.9% on model-agnostic and model-aware datasets respectively, outperforming the organizers' baseline and achieving notable results when contrasted with the top-performing results in the competition, which reported accuracies of 84.7% and 81.3% correspondingly.
4/15/2024
SmurfCat at SemEval-2024 Task 6: Leveraging Synthetic Data for Hallucination Detection
Elisei Rykov, Yana Shishkina, Kseniia Petrushina, Kseniia Titova, Sergey Petrakov, Alexander Panchenko
0
0
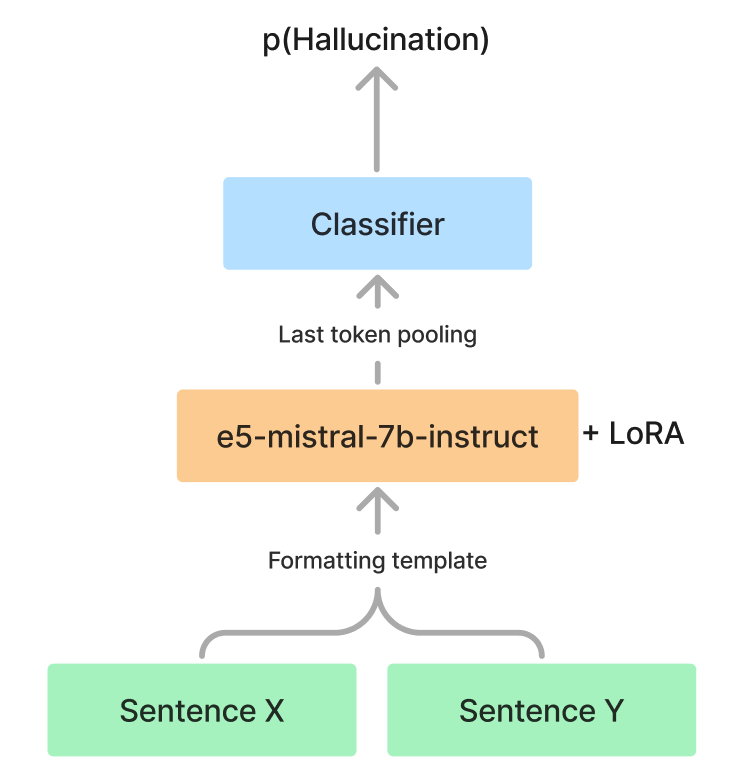
In this paper, we present our novel systems developed for the SemEval-2024 hallucination detection task. Our investigation spans a range of strategies to compare model predictions with reference standards, encompassing diverse baselines, the refinement of pre-trained encoders through supervised learning, and an ensemble approaches utilizing several high-performing models. Through these explorations, we introduce three distinct methods that exhibit strong performance metrics. To amplify our training data, we generate additional training samples from unlabelled training subset. Furthermore, we provide a detailed comparative analysis of our approaches. Notably, our premier method achieved a commendable 9th place in the competition's model-agnostic track and 17th place in model-aware track, highlighting its effectiveness and potential.
4/10/2024

SHROOM-INDElab at SemEval-2024 Task 6: Zero- and Few-Shot LLM-Based Classification for Hallucination Detection
Bradley P. Allen, Fina Polat, Paul Groth
0
0
We describe the University of Amsterdam Intelligent Data Engineering Lab team's entry for the SemEval-2024 Task 6 competition. The SHROOM-INDElab system builds on previous work on using prompt programming and in-context learning with large language models (LLMs) to build classifiers for hallucination detection, and extends that work through the incorporation of context-specific definition of task, role, and target concept, and automated generation of examples for use in a few-shot prompting approach. The resulting system achieved fourth-best and sixth-best performance in the model-agnostic track and model-aware tracks for Task 6, respectively, and evaluation using the validation sets showed that the system's classification decisions were consistent with those of the crowd-sourced human labellers. We further found that a zero-shot approach provided better accuracy than a few-shot approach using automatically generated examples. Code for the system described in this paper is available on Github.
4/8/2024

Don't Believe Everything You Read: Enhancing Summarization Interpretability through Automatic Identification of Hallucinations in Large Language Models
Priyesh Vakharia, Devavrat Joshi, Meenal Chavan, Dhananjay Sonawane, Bhrigu Garg, Parsa Mazaheri
0
0
Large Language Models (LLMs) are adept at text manipulation -- tasks such as machine translation and text summarization. However, these models can also be prone to hallucination, which can be detrimental to the faithfulness of any answers that the model provides. Recent works in combating hallucinations in LLMs deal with identifying hallucinated sentences and categorizing the different ways in which models hallucinate. This paper takes a deep dive into LLM behavior with respect to hallucinations, defines a token-level approach to identifying different kinds of hallucinations, and further utilizes this token-level tagging to improve the interpretability and faithfulness of LLMs in dialogue summarization tasks. Through this, the paper presents a new, enhanced dataset and a new training paradigm.
4/4/2024