Semi-Structured Chain-of-Thought: Integrating Multiple Sources of Knowledge for Improved Language Model Reasoning

0
💬
Sign in to get full access
Overview
- Large language models have the potential to tackle knowledge-intensive tasks, but effectively integrating different knowledge sources (model's own knowledge, external structured data, external unstructured data) remains a challenge.
- Existing methods either rely on limited knowledge sources or require repeatedly invoking large language models, which can be inefficient.
- This work introduces a novel "semi-structured prompting" approach that seamlessly combines the model's own knowledge with external structured and unstructured knowledge sources.
- Experiments on open-domain question answering show this method significantly outperforms existing techniques, even exceeding approaches that require fine-tuning the model.
Plain English Explanation
Large language models, like those used for tasks like answering questions or generating text, have access to a huge amount of knowledge. However, tapping into that knowledge effectively can be tricky. These models have their own internal "memory" of what they've learned, but they can also access additional information from external sources like databases and documents.
The challenge is finding the best way to combine all these different knowledge sources to tackle complex, knowledge-intensive tasks. Previous methods have either relied too heavily on just one or two of these sources, or required repeatedly running the language model, which can be slow and inefficient.
This new "semi-structured prompting" approach provides a more elegant solution. It lets the language model smoothly integrate its own internal knowledge with relevant information pulled from structured databases and unstructured text documents. This allows the model to draw on a rich tapestry of knowledge to tackle open-ended questions and problems.
The researchers tested this method on open-domain question answering, where the goal is to answer broad, fact-based questions. Compared to existing techniques, this new prompting approach showed significant improvements, even outperforming methods that required extra training of the language model. This suggests it's an effective way to harness the full power of large language models for knowledge-intensive applications.
Technical Explanation
The core innovation in this work is a novel "semi-structured prompting" technique that enables large language models to seamlessly integrate three key knowledge sources:
- The model's own parametric memory - the knowledge it has acquired through training.
- External structured knowledge from knowledge graphs and databases.
- External unstructured knowledge from text documents.
Previous prompting methods have typically relied on only one or two of these sources, or required repeatedly invoking the language model in an inefficient manner.
In contrast, the semi-structured prompting approach crafts prompts that guide the language model to query and integrate information from all three knowledge sources. This is done by structuring the prompt in a way that provides a logical flow for the model to follow, while still allowing it to leverage its own inherent language understanding capabilities.
The researchers evaluated this method on open-domain multi-hop question answering datasets, where questions require combining information from multiple sources. The results show this semi-structured prompting approach significantly outperforms existing prompting techniques, even surpassing approaches that require fine-tuning the language model on the specific task.
Critical Analysis
The paper provides a compelling solution to an important challenge in leveraging large language models for knowledge-intensive tasks. By elegantly integrating multiple knowledge sources, the semi-structured prompting technique avoids the limitations of previous methods.
That said, the paper does not extensively explore the potential weaknesses or limitations of this approach. For example, it's unclear how well the method would scale to extremely complex multi-step reasoning tasks, or how sensitive it is to the quality and coverage of the external knowledge sources.
Additionally, the paper focuses on evaluating the technique on question answering, but there may be other knowledge-intensive applications where the benefits are less pronounced. Further research is needed to fully understand the strengths and weaknesses of semi-structured prompting across a wider range of use cases.
Overall, this is a promising advance that demonstrates the value of thoughtfully integrating diverse knowledge sources to unlock the full potential of large language models. However, as with any research, readers should think critically about the findings and consider ways the approach could be further improved or expanded upon.
Conclusion
This work introduces a novel "semi-structured prompting" technique that allows large language models to effectively combine their own internal knowledge with relevant information from external structured and unstructured sources. Experiments show this approach significantly outperforms existing prompting methods on open-domain question answering, highlighting its potential to advance the state of the art in knowledge-intensive applications.
By seamlessly integrating multiple knowledge sources, this semi-structured prompting technique represents an important step forward in unleashing the full capabilities of large language models. As AI systems increasingly tackle complex, real-world problems, innovations like this will be crucial for building systems that can truly understand and reason about the world around them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Semi-Structured Chain-of-Thought: Integrating Multiple Sources of Knowledge for Improved Language Model Reasoning
Xin Su, Tiep Le, Steven Bethard, Phillip Howard
An important open question in the use of large language models for knowledge-intensive tasks is how to effectively integrate knowledge from three sources: the model's parametric memory, external structured knowledge, and external unstructured knowledge. Most existing prompting methods either rely on one or two of these sources, or require repeatedly invoking large language models to generate similar or identical content. In this work, we overcome these limitations by introducing a novel semi-structured prompting approach that seamlessly integrates the model's parametric memory with unstructured knowledge from text documents and structured knowledge from knowledge graphs. Experimental results on open-domain multi-hop question answering datasets demonstrate that our prompting method significantly surpasses existing techniques, even exceeding those that require fine-tuning.
Read more4/3/2024

0
Knowledge Graph Structure as Prompt: Improving Small Language Models Capabilities for Knowledge-based Causal Discovery
Yuni Susanti, Michael Farber
Causal discovery aims to estimate causal structures among variables based on observational data. Large Language Models (LLMs) offer a fresh perspective to tackle the causal discovery problem by reasoning on the metadata associated with variables rather than their actual data values, an approach referred to as knowledge-based causal discovery. In this paper, we investigate the capabilities of Small Language Models (SLMs, defined as LLMs with fewer than 1 billion parameters) with prompt-based learning for knowledge-based causal discovery. Specifically, we present KG Structure as Prompt, a novel approach for integrating structural information from a knowledge graph, such as common neighbor nodes and metapaths, into prompt-based learning to enhance the capabilities of SLMs. Experimental results on three types of biomedical and open-domain datasets under few-shot settings demonstrate the effectiveness of our approach, surpassing most baselines and even conventional fine-tuning approaches trained on full datasets. Our findings further highlight the strong capabilities of SLMs: in combination with knowledge graphs and prompt-based learning, SLMs demonstrate the potential to surpass LLMs with larger number of parameters. Our code and datasets are available on GitHub.
Read more7/31/2024
0
Counter-intuitive: Large Language Models Can Better Understand Knowledge Graphs Than We Thought
Xinbang Dai, Yuncheng Hua, Tongtong Wu, Yang Sheng, Qiu Ji, Guilin Qi
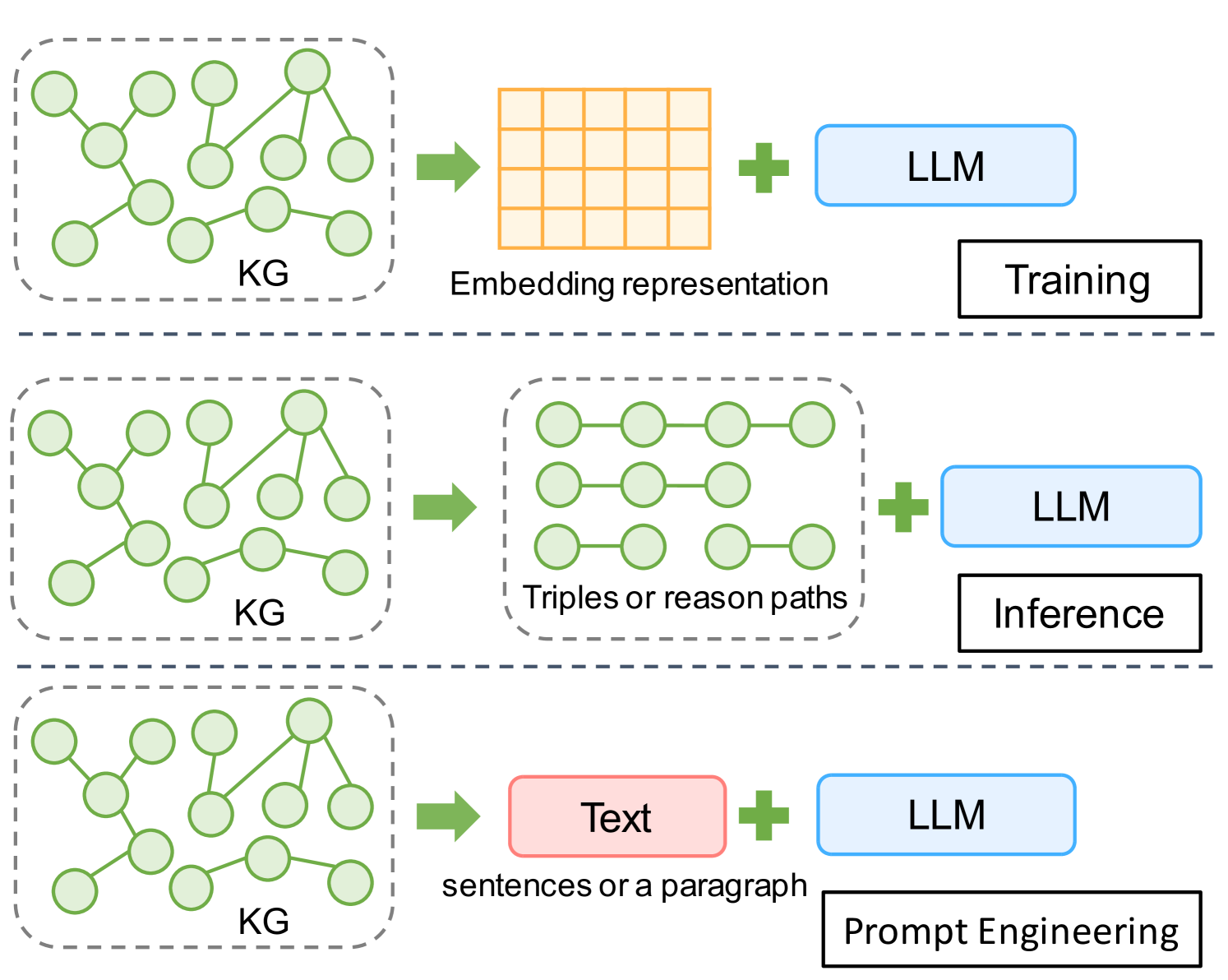
As the parameter scale of large language models (LLMs) grows, jointly training knowledge graph (KG) embeddings with model parameters to enhance LLM capabilities becomes increasingly costly. Consequently, the community has shown interest in developing prompt strategies that effectively integrate KG information into LLMs. However, the format for incorporating KGs into LLMs lacks standardization; for instance, KGs can be transformed into linearized triples or natural language (NL) text. Current prompting methods often rely on a trial-and-error approach, leaving researchers with an incomplete understanding of which KG input format best facilitates LLM comprehension of KG content. To elucidate this, we design a series of experiments to explore LLMs' understanding of different KG input formats within the context of prompt engineering. Our analysis examines both literal and attention distribution levels. Through extensive experiments, we indicate a counter-intuitive phenomenon: when addressing fact-related questions, unordered linearized triples are more effective for LLMs' understanding of KGs compared to fluent NL text. Furthermore, noisy, incomplete, or marginally relevant subgraphs can still enhance LLM performance. Finally, different LLMs have distinct preferences for different formats of organizing unordered triples.
Read more6/18/2024

0
Brainstorming Brings Power to Large Language Models of Knowledge Reasoning
Zining Qin, Chenhao Wang, Huiling Qin, Weijia Jia
Large Language Models (LLMs) have demonstrated amazing capabilities in language generation, text comprehension, and knowledge reasoning. While a single powerful model can already handle multiple tasks, relying on a single perspective can lead to biased and unstable results. Recent studies have further improved the model's reasoning ability on a wide range of tasks by introducing multi-model collaboration. However, models with different capabilities may produce conflicting answers on the same problem, and how to reasonably obtain the correct answer from multiple candidate models has become a challenging problem. In this paper, we propose the multi-model brainstorming based on prompt. It incorporates different models into a group for brainstorming, and after multiple rounds of reasoning elaboration and re-inference, a consensus answer is reached within the group. We conducted experiments on three different types of datasets, and demonstrate that the brainstorming can significantly improve the effectiveness in logical reasoning and fact extraction. Furthermore, we find that two small-parameter models can achieve accuracy approximating that of larger-parameter models through brainstorming, which provides a new solution for distributed deployment of LLMs.
Read more6/12/2024