Semi-Supervised 3D Object Detection with Chanel Augmentation using Transformation Equivariance

0
Sign in to get full access
Overview
- This paper presents a semi-supervised 3D object detection method that uses channel augmentation and transformation equivariance.
- The proposed approach aims to improve 3D object detection performance by leveraging unlabeled data through a channel augmentation technique and exploiting transformation equivariance.
- The method is evaluated on the KITTI and Waymo Open datasets, demonstrating improved performance compared to existing semi-supervised and fully-supervised 3D object detection techniques.
Plain English Explanation
The paper describes a new way to improve the accuracy of 3D object detection systems, which are used in self-driving cars and other applications to identify and locate objects in 3D space.
The key idea is to use "channel augmentation", which means adding extra information channels to the input data, along with "transformation equivariance", which means the system is designed to be robust to changes in the orientation or position of the objects.
By leveraging these techniques, the researchers were able to achieve better 3D object detection performance, especially when using a combination of labeled and unlabeled data. This is important because collecting and annotating large 3D datasets can be time-consuming and expensive, so being able to effectively use unlabeled data can significantly improve the capabilities of these systems.
The method was tested on two popular 3D object detection datasets, KITTI and Waymo Open, and was shown to outperform existing semi-supervised and fully-supervised techniques. This suggests the proposed approach could be a valuable contribution to the field of 3D computer vision and self-driving car technology.
Technical Explanation
The paper introduces a semi-supervised 3D object detection framework that uses channel augmentation and transformation equivariance to improve performance.
The channel augmentation technique involves adding extra information channels to the input data, such as semantic segmentation maps or depth information. This provides the model with additional cues to aid in object detection.
The transformation equivariance property ensures that the model's outputs are consistent with transformations (e.g., rotation, translation) applied to the input. This helps the model generalize better to variations in object pose and orientation.
The framework is designed to effectively utilize both labeled and unlabeled 3D data. The semi-supervised approach combines a supervised loss on the labeled data with an unsupervised consistency loss that encourages the model's predictions to be consistent under various transformations of the unlabeled data.
The authors evaluate their method on the KITTI and Waymo Open 3D object detection datasets, comparing it to state-of-the-art fully-supervised and semi-supervised techniques. The results demonstrate that their approach outperforms these existing methods, particularly in scenarios with limited labeled data.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed semi-supervised 3D object detection framework. The use of channel augmentation and transformation equivariance are novel and well-motivated approaches to improving 3D object detection performance.
One potential limitation is the reliance on specific datasets (KITTI and Waymo Open) for evaluation. It would be valuable to see how the method generalizes to other 3D object detection datasets or real-world scenarios.
Additionally, the paper does not provide much insight into the computational complexity or inference time of the proposed approach compared to existing methods. This information would be useful for understanding the practical deployment implications of the technique.
Overall, the research presented in this paper is a significant contribution to the field of 3D computer vision and could have important implications for the development of more robust and efficient self-driving car technologies.
Conclusion
This paper introduces a novel semi-supervised 3D object detection framework that leverages channel augmentation and transformation equivariance to improve performance, especially in scenarios with limited labeled data. The method was shown to outperform state-of-the-art fully-supervised and semi-supervised techniques on popular 3D object detection benchmarks.
The key innovations of this work, including the use of channel augmentation and the exploitation of transformation equivariance, demonstrate the potential for semi-supervised learning to enhance 3D computer vision capabilities. This research represents an important step forward in the development of more efficient and effective 3D object detection systems, with applications in self-driving cars, robotics, and other industries.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Semi-Supervised 3D Object Detection with Chanel Augmentation using Transformation Equivariance
Minju Kang, Taehun Kong, Tae-Kyun Kim
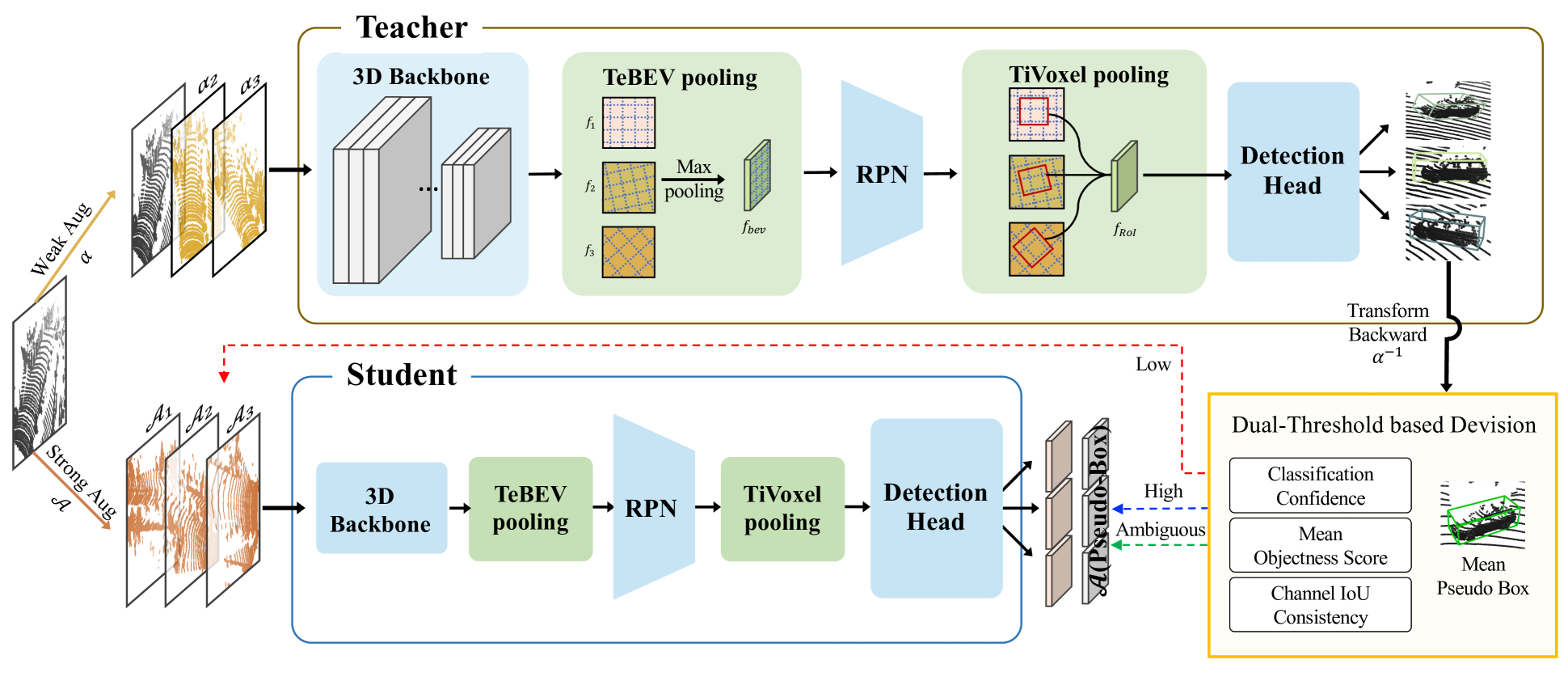
Accurate 3D object detection is crucial for autonomous vehicles and robots to navigate and interact with the environment safely and effectively. Meanwhile, the performance of 3D detector relies on the data size and annotation which is expensive. Consequently, the demand of training with limited labeled data is growing. We explore a novel teacher-student framework employing channel augmentation for 3D semi-supervised object detection. The teacher-student SSL typically adopts a weak augmentation and strong augmentation to teacher and student, respectively. In this work, we apply multiple channel augmentations to both networks using the transformation equivariance detector (TED). The TED allows us to explore different combinations of augmentation on point clouds and efficiently aggregates multi-channel transformation equivariance features. In principle, by adopting fixed channel augmentations for the teacher network, the student can train stably on reliable pseudo-labels. Adopting strong channel augmentations can enrich the diversity of data, fostering robustness to transformations and enhancing generalization performance of the student network. We use SOTA hierarchical supervision as a baseline and adapt its dual-threshold to TED, which is called channel IoU consistency. We evaluate our method with KITTI dataset, and achieved a significant performance leap, surpassing SOTA 3D semi-supervised object detection models.
Read more9/24/2024
0
Power of Cooperative Supervision: Multiple Teachers Framework for Enhanced 3D Semi-Supervised Object Detection
Jin-Hee Lee, Jae-Keun Lee, Je-Seok Kim, Soon Kwon
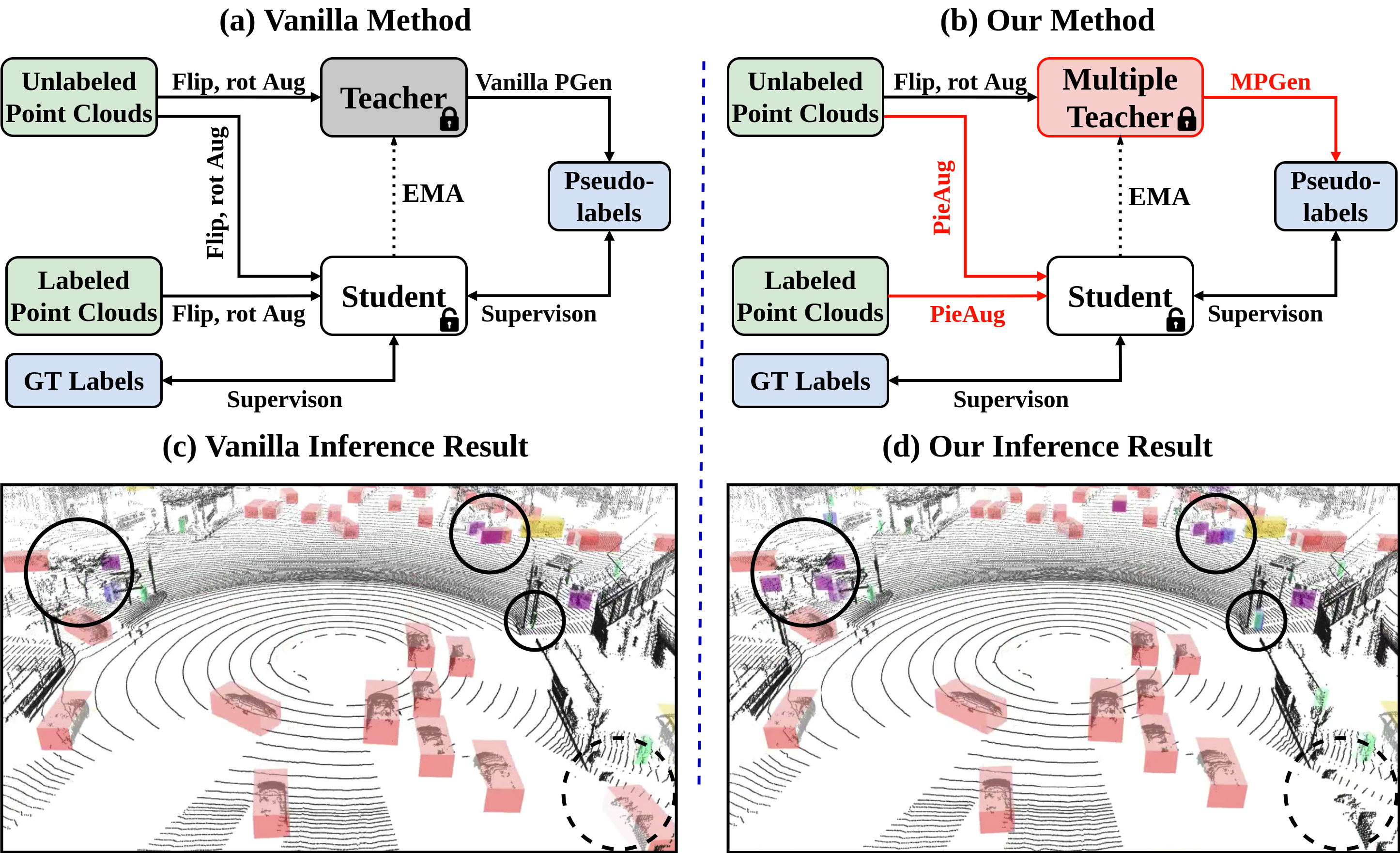
To ensure safe urban driving for autonomous platforms, it is crucial not only to develop high-performance object detection techniques but also to establish a diverse and representative dataset that captures various urban environments and object characteristics. To address these two issues, we have constructed a multi-class 3D LiDAR dataset reflecting diverse urban environments and object characteristics, and developed a robust 3D semi-supervised object detection (SSOD) based on a multiple teachers framework. This SSOD framework categorizes similar classes and assigns specialized teachers to each category. Through collaborative supervision among these category-specialized teachers, the student network becomes increasingly proficient, leading to a highly effective object detector. We propose a simple yet effective augmentation technique, Pie-based Point Compensating Augmentation (PieAug), to enable the teacher network to generate high-quality pseudo-labels. Extensive experiments on the WOD, KITTI, and our datasets validate the effectiveness of our proposed method and the quality of our dataset. Experimental results demonstrate that our approach consistently outperforms existing state-of-the-art 3D semi-supervised object detection methods across all datasets. We plan to release our multi-class LiDAR dataset and the source code available on our Github repository in the near future.
Read more6/3/2024

0
CT3D++: Improving 3D Object Detection with Keypoint-induced Channel-wise Transformer
Hualian Sheng, Sijia Cai, Na Zhao, Bing Deng, Qiao Liang, Min-Jian Zhao, Jieping Ye
The field of 3D object detection from point clouds is rapidly advancing in computer vision, aiming to accurately and efficiently detect and localize objects in three-dimensional space. Current 3D detectors commonly fall short in terms of flexibility and scalability, with ample room for advancements in performance. In this paper, our objective is to address these limitations by introducing two frameworks for 3D object detection with minimal hand-crafted design. Firstly, we propose CT3D, which sequentially performs raw-point-based embedding, a standard Transformer encoder, and a channel-wise decoder for point features within each proposal. Secondly, we present an enhanced network called CT3D++, which incorporates geometric and semantic fusion-based embedding to extract more valuable and comprehensive proposal-aware information. Additionally, CT3D ++ utilizes a point-to-key bidirectional encoder for more efficient feature encoding with reduced computational cost. By replacing the corresponding components of CT3D with these novel modules, CT3D++ achieves state-of-the-art performance on both the KITTI dataset and the large-scale Way-mo Open Dataset. The source code for our frameworks will be made accessible at https://github.com/hlsheng1/CT3D-plusplus.
Read more6/13/2024

0
TrajSSL: Trajectory-Enhanced Semi-Supervised 3D Object Detection
Philip Jacobson, Yichen Xie, Mingyu Ding, Chenfeng Xu, Masayoshi Tomizuka, Wei Zhan, Ming C. Wu
Semi-supervised 3D object detection is a common strategy employed to circumvent the challenge of manually labeling large-scale autonomous driving perception datasets. Pseudo-labeling approaches to semi-supervised learning adopt a teacher-student framework in which machine-generated pseudo-labels on a large unlabeled dataset are used in combination with a small manually-labeled dataset for training. In this work, we address the problem of improving pseudo-label quality through leveraging long-term temporal information captured in driving scenes. More specifically, we leverage pre-trained motion-forecasting models to generate object trajectories on pseudo-labeled data to further enhance the student model training. Our approach improves pseudo-label quality in two distinct manners: first, we suppress false positive pseudo-labels through establishing consistency across multiple frames of motion forecasting outputs. Second, we compensate for false negative detections by directly inserting predicted object tracks into the pseudo-labeled scene. Experiments on the nuScenes dataset demonstrate the effectiveness of our approach, improving the performance of standard semi-supervised approaches in a variety of settings.
Read more9/18/2024