Semi-Supervised Laplace Learning on Stiefel Manifolds

0
🤯
Sign in to get full access
Overview
- Addresses the limitations of canonical Laplace learning algorithms in low label rate settings
- Reformulates graph-based semi-supervised learning as a nonconvex generalization of the Trust-Region Subproblem (TRS)
- Develops a Sequential Subspace Optimization framework for efficient optimization
- Proposes a novel measure of sample centrality to identify informative supervised samples
Plain English Explanation
The paper aims to improve the performance of semi-supervised learning algorithms, which use both labeled and unlabeled data to train models, in scenarios with very few labeled samples. The researchers propose a new way of framing the semi-supervised learning problem as a Trust-Region Subproblem, a well-studied optimization problem.
This reformulation is based on the observation that the eigenvectors of the graph Laplacian, a key component in many semi-supervised learning algorithms, become well-defined as the amount of unlabeled data approaches infinity. The researchers then show that solving this Trust-Region Subproblem is equivalent to aligning the model's predictions with the principal eigenvectors of a certain submatrix of the graph Laplacian.
To efficiently solve this optimization problem, the authors develop a Sequential Subspace Optimization framework, which iteratively refines the model by optimizing within a sequence of subspaces.
Additionally, the paper introduces a novel measure of sample "centrality" based on the principal eigenvectors of the graph Laplacian submatrix. This metric is used to identify the most informative labeled samples, which can then be used to train the model more effectively in low-label rate scenarios.
Technical Explanation
The paper proposes a new formulation of graph-based semi-supervised learning as a nonconvex generalization of the Trust-Region Subproblem (TRS). This reformulation is motivated by the well-posedness of the Laplacian eigenvectors in the limit of infinite unlabeled data.
The researchers first show that a first-order condition on the TRS formulation implies the solution of a manifold alignment problem, where the goal is to align the model's predictions with the principal eigenvectors of a certain submatrix of the graph Laplacian. They further demonstrate that solutions to the classical Orthogonal Procrustes problem can be used to efficiently find good classifiers that are amenable to further refinement.
To tackle the refinement step, the authors develop a Sequential Subspace Optimization framework for graph-based semi-supervised learning. This iterative optimization approach optimizes the model within a sequence of subspaces, leading to improved performance.
Additionally, the paper addresses the critical issue of selecting informative supervised samples in low-label rate scenarios. The authors propose a novel measure of sample "centrality" derived from the principal eigenvectors of the graph Laplacian submatrix. This centrality metric is used to identify the most informative labeled samples, which can then be used to train the model more effectively.
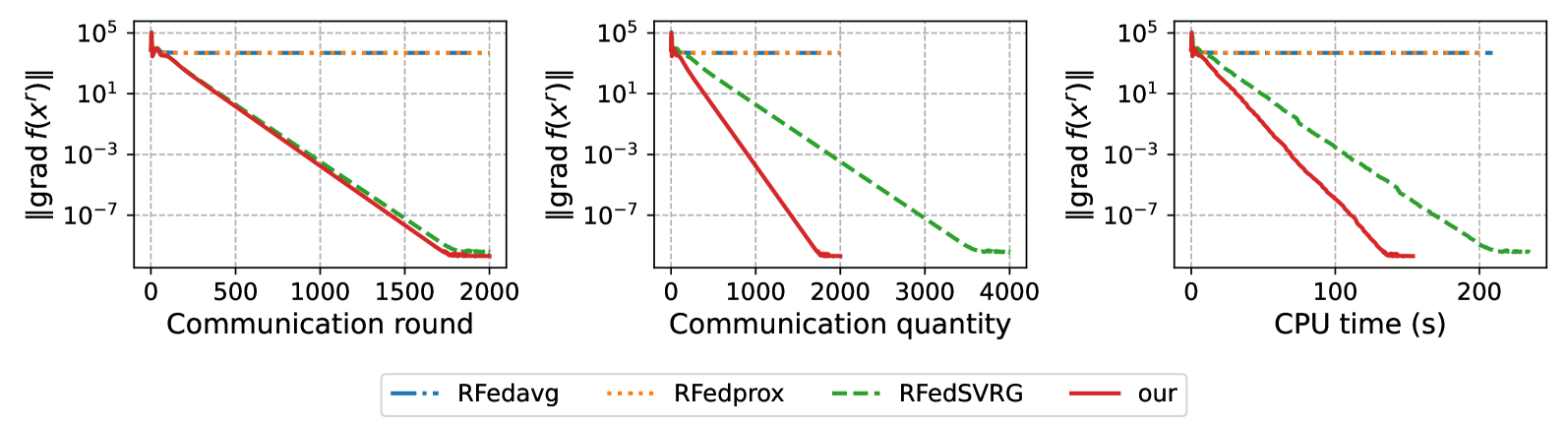
The proposed framework is evaluated on several benchmark datasets, demonstrating lower classification error compared to recent state-of-the-art and classical semi-supervised learning methods across a range of label rates.
Critical Analysis
The paper presents a novel and theoretically grounded approach to graph-based semi-supervised learning, addressing the key challenge of poor performance in low-label rate scenarios. The reformulation of the problem as a Trust-Region Subproblem and the development of the Sequential Subspace Optimization framework are well-motivated and contribute to the field.
However, the paper does not delve into the potential limitations or caveats of the proposed approach. For example, it would be valuable to understand the computational complexity of the optimization procedure and its scalability to larger datasets. Additionally, the authors could explore the sensitivity of the method to the choice of graph construction and the centrality metric used for sample selection.
Furthermore, while the experimental results demonstrate the effectiveness of the approach, it would be helpful to see a more in-depth analysis of the failure cases or scenarios where the method may not perform as well as the state-of-the-art. This could help readers better understand the strengths and weaknesses of the proposed framework.
Overall, the paper presents a promising direction for improving semi-supervised learning in low-label rate settings, but further research is needed to fully understand the practical implications and limitations of the approach.
Conclusion
The paper introduces a novel formulation of graph-based semi-supervised learning as a nonconvex generalization of the Trust-Region Subproblem, which leverages the well-posedness of Laplacian eigenvectors in the limit of infinite unlabeled data. The researchers develop an efficient Sequential Subspace Optimization framework to solve this problem and propose a novel centrality-based measure to identify informative supervised samples, particularly in low-label rate scenarios.
The experimental results demonstrate the effectiveness of the proposed approach, which outperforms recent state-of-the-art and classical semi-supervised learning methods across a range of label rates. This work contributes to the ongoing efforts to address the limitations of canonical semi-supervised learning algorithms and can have significant implications for real-world applications with limited labeled data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
Semi-Supervised Laplace Learning on Stiefel Manifolds
Chester Holtz, Pengwen Chen, Alexander Cloninger, Chung-Kuan Cheng, Gal Mishne
Motivated by the need to address the degeneracy of canonical Laplace learning algorithms in low label rates, we propose to reformulate graph-based semi-supervised learning as a nonconvex generalization of a emph{Trust-Region Subproblem} (TRS). This reformulation is motivated by the well-posedness of Laplacian eigenvectors in the limit of infinite unlabeled data. To solve this problem, we first show that a first-order condition implies the solution of a manifold alignment problem and that solutions to the classical emph{Orthogonal Procrustes} problem can be used to efficiently find good classifiers that are amenable to further refinement. To tackle refinement, we develop the framework of Sequential Subspace Optimization for graph-based SSL. Next, we address the criticality of selecting supervised samples at low-label rates. We characterize informative samples with a novel measure of centrality derived from the principal eigenvectors of a certain submatrix of the graph Laplacian. We demonstrate that our framework achieves lower classification error compared to recent state-of-the-art and classical semi-supervised learning methods at extremely low, medium, and high label rates.
Read more8/15/2024
0
Nonconvex Federated Learning on Compact Smooth Submanifolds With Heterogeneous Data
Jiaojiao Zhang, Jiang Hu, Anthony Man-Cho So, Mikael Johansson
Many machine learning tasks, such as principal component analysis and low-rank matrix completion, give rise to manifold optimization problems. Although there is a large body of work studying the design and analysis of algorithms for manifold optimization in the centralized setting, there are currently very few works addressing the federated setting. In this paper, we consider nonconvex federated learning over a compact smooth submanifold in the setting of heterogeneous client data. We propose an algorithm that leverages stochastic Riemannian gradients and a manifold projection operator to improve computational efficiency, uses local updates to improve communication efficiency, and avoids client drift. Theoretically, we show that our proposed algorithm converges sub-linearly to a neighborhood of a first-order optimal solution by using a novel analysis that jointly exploits the manifold structure and properties of the loss functions. Numerical experiments demonstrate that our algorithm has significantly smaller computational and communication overhead than existing methods.
Read more6/13/2024
0
FORML: A Riemannian Hessian-free Method for Meta-learning on Stiefel Manifolds
Hadi Tabealhojeh, Soumava Kumar Roy, Peyman Adibi, Hossein Karshenas
Meta-learning problem is usually formulated as a bi-level optimization in which the task-specific and the meta-parameters are updated in the inner and outer loops of optimization, respectively. However, performing the optimization in the Riemannian space, where the parameters and meta-parameters are located on Riemannian manifolds is computationally intensive. Unlike the Euclidean methods, the Riemannian backpropagation needs computing the second-order derivatives that include backward computations through the Riemannian operators such as retraction and orthogonal projection. This paper introduces a Hessian-free approach that uses a first-order approximation of derivatives on the Stiefel manifold. Our method significantly reduces the computational load and memory footprint. We show how using a Stiefel fully-connected layer that enforces orthogonality constraint on the parameters of the last classification layer as the head of the backbone network, strengthens the representation reuse of the gradient-based meta-learning methods. Our experimental results across various few-shot learning datasets, demonstrate the superiority of our proposed method compared to the state-of-the-art methods, especially MAML, its Euclidean counterpart.
Read more6/4/2024

0
Learning on manifolds without manifold learning
H. N. Mhaskar, Ryan O'Dowd
Function approximation based on data drawn randomly from an unknown distribution is an important problem in machine learning. The manifold hypothesis assumes that the data is sampled from an unknown submanifold of a high dimensional Euclidean space. A great deal of research deals with obtaining information about this manifold, such as the eigendecomposition of the Laplace-Beltrami operator or coordinate charts, and using this information for function approximation. This two-step approach implies some extra errors in the approximation stemming from estimating the basic quantities of the data manifold in addition to the errors inherent in function approximation. In this paper, we project the unknown manifold as a submanifold of an ambient hypersphere and study the question of constructing a one-shot approximation using a specially designed sequence of localized spherical polynomial kernels on the hypersphere. Our approach does not require preprocessing of the data to obtain information about the manifold other than its dimension. We give optimal rates of approximation for relatively ``rough'' functions.
Read more8/20/2024