Separating Style from Substance: Enhancing Cross-Genre Authorship Attribution through Data Selection and Presentation

0
📊
Sign in to get full access
Overview
- This paper explores ways to enhance cross-genre authorship attribution by separating style from substance.
- The authors propose a data selection and presentation approach to improve the performance of authorship attribution models.
- The research aims to address the challenge of accurately attributing authorship across different genres of written text.
Plain English Explanation
The main idea of this paper is to find a way to better identify the author of a piece of writing, even if the writing is in a different style or genre than what the model was trained on. For example, if a model was trained to identify authors based on news articles, can it still accurately identify the author of a novel or a blog post?
The researchers tried two approaches to improve the model's performance in this "cross-genre" scenario:
-
Data Selection: They experimented with selecting the most relevant training data for the model, focusing on features that capture the author's unique writing style rather than just the content of the text.
-
Data Presentation: They explored different ways of presenting the training data to the model, such as abstracting away some of the content-related information and highlighting the stylistic elements.
The goal was to help the model focus on the author's distinctive writing style, rather than getting distracted by the specific topic or genre of the text. This could lead to more accurate authorship attribution, even when the model is applied to texts in different genres than what it was trained on.
Technical Explanation
The paper proposes a two-pronged approach to enhance cross-genre authorship attribution:
-
Data Selection: The authors explored different methods for selecting the most relevant training data for the authorship attribution task. This included techniques like link to identify stylistic features that are most indicative of an author's writing, and using those features to curate the training data.
-
Data Presentation: In addition to data selection, the researchers experimented with different ways of presenting the training data to the model. This involved link techniques like abstracting away content-related information and emphasizing stylistic elements, with the goal of helping the model focus on the author's unique writing style rather than the specific topic or genre.
The authors evaluated their approaches on a range of authorship attribution tasks across different genres, including link and link. Their results suggest that the combination of data selection and presentation can significantly improve the model's performance, especially in cross-genre scenarios where the training and test data come from different genres.
Critical Analysis
The paper presents a well-designed and thorough investigation into enhancing cross-genre authorship attribution. The authors' focus on separating style from substance is a novel and promising approach, as traditional authorship attribution models can often be biased by the content or genre of the text.
However, the paper does acknowledge some limitations of the proposed approaches. For example, link the authors note that their methods may be less effective when dealing with shorter texts, or in cases where an author's style is heavily influenced by the genre or topic of the writing.
Additionally, the paper does not explore the potential impact of factors like link on the authorship attribution task. Further research may be needed to understand how these factors interact with the authors' data selection and presentation techniques.
Overall, the paper presents a thoughtful and well-executed study that could have significant implications for the field of authorship attribution. The authors' focus on separating style from substance is a valuable contribution, and their findings suggest promising avenues for future research in this area.
Conclusion
This paper introduces a novel approach to enhancing cross-genre authorship attribution by focusing on separating an author's writing style from the content or genre of the text. The authors' two-pronged strategy of data selection and presentation demonstrates the potential to improve the performance of authorship attribution models, particularly in scenarios where the training and test data come from different genres.
While the paper acknowledges some limitations, the overall findings suggest that this approach could have important implications for a wide range of applications, from literary analysis to forensic investigations. By shedding light on the nuances of an author's distinctive writing style, this research could pave the way for more accurate and reliable authorship attribution across diverse textual domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Separating Style from Substance: Enhancing Cross-Genre Authorship Attribution through Data Selection and Presentation
Steven Fincke, Elizabeth Boschee
The task of deciding whether two documents are written by the same author is challenging for both machines and humans. This task is even more challenging when the two documents are written about different topics (e.g. baseball vs. politics) or in different genres (e.g. a blog post vs. an academic article). For machines, the problem is complicated by the relative lack of real-world training examples that cross the topic boundary and the vanishing scarcity of cross-genre data. We propose targeted methods for training data selection and a novel learning curriculum that are designed to discourage a model's reliance on topic information for authorship attribution and correspondingly force it to incorporate information more robustly indicative of style no matter the topic. These refinements yield a 62.7% relative improvement in average cross-genre authorship attribution, as well as 16.6% in the per-genre condition.
Read more8/12/2024

0
Capturing Style in Author and Document Representation
Enzo Terreau, Antoine Gourru, Julien Velcin
A wide range of Deep Natural Language Processing (NLP) models integrates continuous and low dimensional representations of words and documents. Surprisingly, very few models study representation learning for authors. These representations can be used for many NLP tasks, such as author identification and classification, or in recommendation systems. A strong limitation of existing works is that they do not explicitly capture writing style, making them hardly applicable to literary data. We therefore propose a new architecture based on Variational Information Bottleneck (VIB) that learns embeddings for both authors and documents with a stylistic constraint. Our model fine-tunes a pre-trained document encoder. We stimulate the detection of writing style by adding predefined stylistic features making the representation axis interpretable with respect to writing style indicators. We evaluate our method on three datasets: a literary corpus extracted from the Gutenberg Project, the Blog Authorship Corpus and IMDb62, for which we show that it matches or outperforms strong/recent baselines in authorship attribution while capturing much more accurately the authors stylistic aspects.
Read more7/19/2024
🗣️
0
Can Authorship Attribution Models Distinguish Speakers in Speech Transcripts?
Cristina Aggazzotti, Nicholas Andrews, Elizabeth Allyn Smith
Authorship verification is the task of determining if two distinct writing samples share the same author and is typically concerned with the attribution of written text. In this paper, we explore the attribution of transcribed speech, which poses novel challenges. The main challenge is that many stylistic features, such as punctuation and capitalization, are not informative in this setting. On the other hand, transcribed speech exhibits other patterns, such as filler words and backchannels (e.g., 'um', 'uh-huh'), which may be characteristic of different speakers. We propose a new benchmark for speaker attribution focused on human-transcribed conversational speech transcripts. To limit spurious associations of speakers with topic, we employ both conversation prompts and speakers participating in the same conversation to construct verification trials of varying difficulties. We establish the state of the art on this new benchmark by comparing a suite of neural and non-neural baselines, finding that although written text attribution models achieve surprisingly good performance in certain settings, they perform markedly worse as conversational topic is increasingly controlled. We present analyses of the impact of transcription style on performance as well as the ability of fine-tuning on speech transcripts to improve performance.
Read more6/17/2024
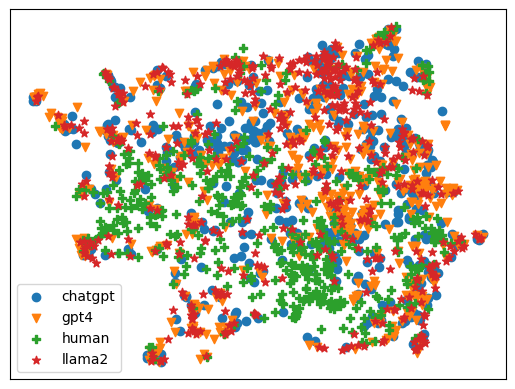
0
Few-Shot Detection of Machine-Generated Text using Style Representations
Rafael Rivera Soto, Kailin Koch, Aleem Khan, Barry Chen, Marcus Bishop, Nicholas Andrews
The advent of instruction-tuned language models that convincingly mimic human writing poses a significant risk of abuse. However, such abuse may be counteracted with the ability to detect whether a piece of text was composed by a language model rather than a human author. Some previous approaches to this problem have relied on supervised methods by training on corpora of confirmed human- and machine- written documents. Unfortunately, model under-specification poses an unavoidable challenge for neural network-based detectors, making them brittle in the face of data shifts, such as the release of newer language models producing still more fluent text than the models used to train the detectors. Other approaches require access to the models that may have generated a document in question, which is often impractical. In light of these challenges, we pursue a fundamentally different approach not relying on samples from language models of concern at training time. Instead, we propose to leverage representations of writing style estimated from human-authored text. Indeed, we find that features effective at distinguishing among human authors are also effective at distinguishing human from machine authors, including state-of-the-art large language models like Llama-2, ChatGPT, and GPT-4. Furthermore, given a handful of examples composed by each of several specific language models of interest, our approach affords the ability to predict which model generated a given document. The code and data to reproduce our experiments are available at https://github.com/LLNL/LUAR/tree/main/fewshot_iclr2024.
Read more5/9/2024