Few-Shot Detection of Machine-Generated Text using Style Representations
2401.06712
0
1
Abstract
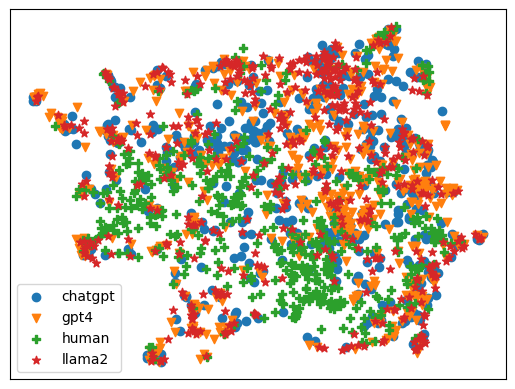
The advent of instruction-tuned language models that convincingly mimic human writing poses a significant risk of abuse. However, such abuse may be counteracted with the ability to detect whether a piece of text was composed by a language model rather than a human author. Some previous approaches to this problem have relied on supervised methods by training on corpora of confirmed human- and machine- written documents. Unfortunately, model under-specification poses an unavoidable challenge for neural network-based detectors, making them brittle in the face of data shifts, such as the release of newer language models producing still more fluent text than the models used to train the detectors. Other approaches require access to the models that may have generated a document in question, which is often impractical. In light of these challenges, we pursue a fundamentally different approach not relying on samples from language models of concern at training time. Instead, we propose to leverage representations of writing style estimated from human-authored text. Indeed, we find that features effective at distinguishing among human authors are also effective at distinguishing human from machine authors, including state-of-the-art large language models like Llama-2, ChatGPT, and GPT-4. Furthermore, given a handful of examples composed by each of several specific language models of interest, our approach affords the ability to predict which model generated a given document. The code and data to reproduce our experiments are available at https://github.com/LLNL/LUAR/tree/main/fewshot_iclr2024.
Create account to get full access
Overview
- This paper explores a novel approach to detecting machine-generated text using style representations.
- The key idea is to leverage fine-grained textual features, such as lexical and syntactic patterns, to build a few-shot classifier that can distinguish human-written text from machine-generated text.
- The researchers demonstrate that their method outperforms existing state-of-the-art techniques for detecting AI-generated content, particularly in low-resource settings where only a small amount of labeled data is available.
Plain English Explanation
The paper introduces a new way to detect text that has been generated by artificial intelligence (AI) systems, rather than written by a human. The core insight is that even if the content of the text might be convincing, the underlying writing style and patterns can still reveal whether it was produced by a machine.
The researchers developed a machine learning model that can identify these subtle stylistic differences between human and AI-generated text. Importantly, their approach requires only a small amount of labeled examples to train the model - hence the "few-shot" in the title. This is a significant advantage over previous methods that needed much larger datasets.
The key is that the model looks at low-level textual features, like the choice of words, sentence structure, and even things like punctuation usage. These fine-grained style representations capture the unique "fingerprint" of how a human writer composes text, versus the more uniform patterns of current AI language models.
By leveraging these style-based signals, the researchers showed their model can effectively detect AI-generated content, even in situations where the machine-written text is quite realistic and difficult for humans to identify. This has important implications for combating the spread of misinformation and deepfakes, as well as upholding the integrity of online discourse.
Technical Explanation
The paper proposes a few-shot detection of machine-generated text using style representations. The key insight is that even if the content of the text is convincing, the underlying writing style and patterns can still reveal whether it was produced by a machine.
The authors develop a machine learning model that leverages fine-grained textual features, such as lexical and syntactic patterns, to build a few-shot classifier that can distinguish human-written text from machine-generated text. This contrasts with previous approaches that have focused more on higher-level semantic signals.
The experimental results demonstrate that the proposed style-based approach outperforms existing state-of-the-art techniques for detecting AI-generated content, particularly in low-resource settings where only a small amount of labeled data is available. This is a significant advantage, as obtaining large annotated datasets for this task can be challenging.
The authors also investigate the robustness and transferability of their style-based detection model, showing that it generalizes well to a variety of machine-generated text sources and can be effectively applied in cross-domain settings.
Critical Analysis
The paper presents a compelling approach to the important problem of detecting machine-generated text. The style-based detection method is a promising direction, as it can potentially overcome some of the limitations of existing techniques that rely more on higher-level semantic signals.
However, the authors acknowledge that their method may have difficulty detecting more advanced or customized machine-generated text that is designed to specifically mimic human writing patterns. Additionally, the paper does not explore the potential for adversarial attacks, where the machine-generated text could be intentionally crafted to evade the style-based detection.
Further research is needed to understand the long-term robustness of this approach, as well as its scalability to handle the rapidly evolving landscape of AI-generated content. Incorporating additional contextual or behavioral signals, beyond just textual style, could also strengthen the detection capabilities.
Overall, this paper represents an important step forward in the ongoing efforts to combat the spread of misinformation and uphold the integrity of online discourse. The style-based detection method is a valuable contribution to the field, and the authors' findings highlight the need for continued research and innovation in this critical area.
Conclusion
The paper presents a novel approach to detecting machine-generated text using style representations. By leveraging fine-grained textual features, the researchers developed a few-shot classifier that can effectively distinguish human-written text from AI-generated content, even in low-resource settings.
This style-based detection method offers significant advantages over existing techniques, particularly in its ability to generalize and perform well with limited training data. The findings have important implications for addressing the growing challenge of misinformation and ensuring the authenticity of online discourse.
While the paper represents an important step forward, further research is needed to explore the long-term robustness and scalability of this approach, as well as potential ways to enhance its detection capabilities. Nonetheless, the style-based detection method introduced in this work is a valuable contribution to the ongoing efforts to combat the spread of AI-generated disinformation and uphold the integrity of the digital landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Exploring the Limitations of Detecting Machine-Generated Text
Jad Doughman, Osama Mohammed Afzal, Hawau Olamide Toyin, Shady Shehata, Preslav Nakov, Zeerak Talat
0
0
Recent improvements in the quality of the generations by large language models have spurred research into identifying machine-generated text. Systems proposed for the task often achieve high performance. However, humans and machines can produce text in different styles and in different domains, and it remains unclear whether machine generated-text detection models favour particular styles or domains. In this paper, we critically examine the classification performance for detecting machine-generated text by evaluating on texts with varying writing styles. We find that classifiers are highly sensitive to stylistic changes and differences in text complexity, and in some cases degrade entirely to random classifiers. We further find that detection systems are particularly susceptible to misclassify easy-to-read texts while they have high performance for complex texts.
6/18/2024

Deciphering Textual Authenticity: A Generalized Strategy through the Lens of Large Language Semantics for Detecting Human vs. Machine-Generated Text
Mazal Bethany, Brandon Wherry, Emet Bethany, Nishant Vishwamitra, Anthony Rios, Peyman Najafirad
0
0
With the recent proliferation of Large Language Models (LLMs), there has been an increasing demand for tools to detect machine-generated text. The effective detection of machine-generated text face two pertinent problems: First, they are severely limited in generalizing against real-world scenarios, where machine-generated text is produced by a variety of generators, including but not limited to GPT-4 and Dolly, and spans diverse domains, ranging from academic manuscripts to social media posts. Second, existing detection methodologies treat texts produced by LLMs through a restrictive binary classification lens, neglecting the nuanced diversity of artifacts generated by different LLMs. In this work, we undertake a systematic study on the detection of machine-generated text in real-world scenarios. We first study the effectiveness of state-of-the-art approaches and find that they are severely limited against text produced by diverse generators and domains in the real world. Furthermore, t-SNE visualizations of the embeddings from a pretrained LLM's encoder show that they cannot reliably distinguish between human and machine-generated text. Based on our findings, we introduce a novel system, T5LLMCipher, for detecting machine-generated text using a pretrained T5 encoder combined with LLM embedding sub-clustering to address the text produced by diverse generators and domains in the real world. We evaluate our approach across 9 machine-generated text systems and 9 domains and find that our approach provides state-of-the-art generalization ability, with an average increase in F1 score on machine-generated text of 19.6% on unseen generators and domains compared to the top performing existing approaches and correctly attributes the generator of text with an accuracy of 93.6%.
4/4/2024
🔎
Efficient Detection of LLM-generated Texts with a Bayesian Surrogate Model
Yibo Miao, Hongcheng Gao, Hao Zhang, Zhijie Deng
0
0
The detection of machine-generated text, especially from large language models (LLMs), is crucial in preventing serious social problems resulting from their misuse. Some methods train dedicated detectors on specific datasets but fall short in generalizing to unseen test data, while other zero-shot ones often yield suboptimal performance. Although the recent DetectGPT has shown promising detection performance, it suffers from significant inefficiency issues, as detecting a single candidate requires querying the source LLM with hundreds of its perturbations. This paper aims to bridge this gap. Concretely, we propose to incorporate a Bayesian surrogate model, which allows us to select typical samples based on Bayesian uncertainty and interpolate scores from typical samples to other samples, to improve query efficiency. Empirical results demonstrate that our method significantly outperforms existing approaches under a low query budget. Notably, when detecting the text generated by LLaMA family models, our method with just 2 or 3 queries can outperform DetectGPT with 200 queries.
6/5/2024
🔎
Deepfake Text Detection in the Wild
Yafu Li, Qintong Li, Leyang Cui, Wei Bi, Zhilin Wang, Longyue Wang, Linyi Yang, Shuming Shi, Yue Zhang
0
0
Large language models (LLMs) have achieved human-level text generation, emphasizing the need for effective AI-generated text detection to mitigate risks like the spread of fake news and plagiarism. Existing research has been constrained by evaluating detection methods on specific domains or particular language models. In practical scenarios, however, the detector faces texts from various domains or LLMs without knowing their sources. To this end, we build a comprehensive testbed by gathering texts from diverse human writings and texts generated by different LLMs. Empirical results show challenges in distinguishing machine-generated texts from human-authored ones across various scenarios, especially out-of-distribution. These challenges are due to the decreasing linguistic distinctions between the two sources. Despite challenges, the top-performing detector can identify 86.54% out-of-domain texts generated by a new LLM, indicating the feasibility for application scenarios. We release our resources at https://github.com/yafuly/MAGE.
5/22/2024