Sequence-to-Sequence Multi-Modal Speech In-Painting

0

Sign in to get full access
Overview
- This paper proposes a novel sequence-to-sequence multi-modal speech in-painting model that can fill in missing speech segments using both audio and visual information.
- The model leverages self-supervised representation learning and cross-modal conditional audio-visual relationships to achieve state-of-the-art performance on speech in-painting tasks.
- The approach combines advancements in robust multi-modal speech painting, self-supervised representation learning, and cross-modal conditional audio-visual modeling.
Plain English Explanation
The paper introduces a new AI model that can fill in missing parts of spoken audio using both the audio itself and related visual information. This is useful for applications like video conferencing, where someone's audio might drop out briefly.
The model works by learning rich representations of the audio and visual data through self-supervised training - that is, learning patterns in the data without explicit labels. It then uses these learned representations, along with the relationship between the audio and visual modalities, to predict what the missing audio should be.
This approach builds on previous work in robust multi-modal speech painting, self-supervised representation learning, and cross-modal conditional audio-visual modeling. By combining these techniques, the model can accurately fill in gaps in speech data using both the audio and visual information available.
Technical Explanation
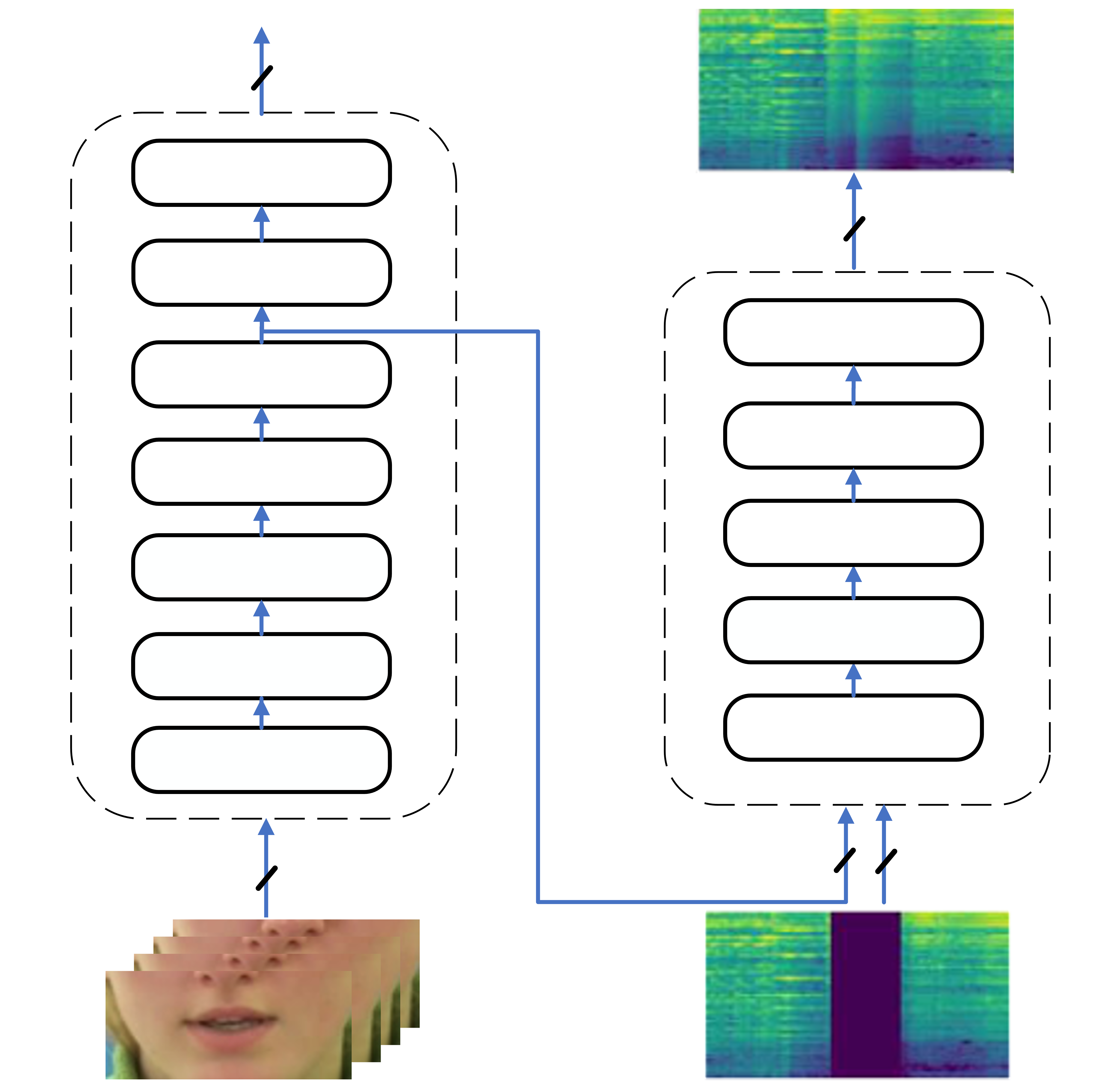
The proposed model uses a sequence-to-sequence architecture to perform speech in-painting. It takes as input a sequence of audio frames and corresponding video frames, with some audio frames missing. The model then predicts the missing audio frames using the available audio and visual information.
The key components of the model are:
- Audio and Visual Encoders: These encode the input audio and video sequences into rich latent representations.
- Cross-Modal Conditional Model: This module models the relationship between the audio and visual modalities, allowing the model to leverage visual information to predict missing audio.
- Sequence-to-Sequence Decoder: This decodes the latent representations to predict the missing audio frames.
The model is trained using a combination of self-supervised learning on large-scale audio-visual data, as well as supervised fine-tuning on speech in-painting tasks. This allows the model to learn powerful representations of the audio and visual data, as well as the relationships between them.
Experiments on benchmark speech in-painting datasets show that this approach outperforms previous state-of-the-art methods, demonstrating the power of combining self-supervised representation learning and cross-modal conditional modeling for this task.
Critical Analysis
The paper presents a compelling approach to the problem of speech in-painting, leveraging advancements in multi-modal representation learning and cross-modal conditional modeling. The proposed model achieves strong performance on benchmark tasks, suggesting its potential usefulness for real-world applications.
However, the paper does not address certain limitations and caveats of the approach. For example, the model may struggle with more complex or noisy audio-visual data, or in scenarios where the visual information is not sufficiently informative to predict the missing audio. Additionally, the computational and memory requirements of the model are not discussed, which could be a concern for deployment in resource-constrained settings.
Further research could explore ways to make the model more robust to noise and variability, as well as investigate its performance in a wider range of real-world scenarios. Incorporating techniques like versatile image outpainting or audio synthesis from silent video could also be a fruitful avenue for extending the capabilities of this speech in-painting approach.
Conclusion
This paper presents a novel sequence-to-sequence multi-modal speech in-painting model that can effectively fill in missing speech segments using both audio and visual information. By leveraging self-supervised representation learning and cross-modal conditional modeling, the model achieves state-of-the-art performance on benchmark speech in-painting tasks.
The proposed approach represents an important advancement in the field of multi-modal speech processing and could have significant implications for real-world applications, such as improving the quality of video conferencing and other communication technologies. While the model has some limitations, the core ideas and techniques introduced in this paper pave the way for further research and development in this exciting area of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Sequence-to-Sequence Multi-Modal Speech In-Painting
Mahsa Kadkhodaei Elyaderani, Shahram Shirani
Speech in-painting is the task of regenerating missing audio contents using reliable context information. Despite various recent studies in multi-modal perception of audio in-painting, there is still a need for an effective infusion of visual and auditory information in speech in-painting. In this paper, we introduce a novel sequence-to-sequence model that leverages the visual information to in-paint audio signals via an encoder-decoder architecture. The encoder plays the role of a lip-reader for facial recordings and the decoder takes both encoder outputs as well as the distorted audio spectrograms to restore the original speech. Our model outperforms an audio-only speech in-painting model and has comparable results with a recent multi-modal speech in-painter in terms of speech quality and intelligibility metrics for distortions of 300 ms to 1500 ms duration, which proves the effectiveness of the introduced multi-modality in speech in-painting.
Read more6/4/2024
0
Robust Multi-Modal Speech In-Painting: A Sequence-to-Sequence Approach
Mahsa Kadkhodaei Elyaderani, Shahram Shirani
The process of reconstructing missing parts of speech audio from context is called speech in-painting. Human perception of speech is inherently multi-modal, involving both audio and visual (AV) cues. In this paper, we introduce and study a sequence-to-sequence (seq2seq) speech in-painting model that incorporates AV features. Our approach extends AV speech in-painting techniques to scenarios where both audio and visual data may be jointly corrupted. To achieve this, we employ a multi-modal training paradigm that boosts the robustness of our model across various conditions involving acoustic and visual distortions. This makes our distortion-aware model a plausible solution for real-world challenging environments. We compare our method with existing transformer-based and recurrent neural network-based models, which attempt to reconstruct missing speech gaps ranging from a few milliseconds to over a second. Our experimental results demonstrate that our novel seq2seq architecture outperforms the state-of-the-art transformer solution by 38.8% in terms of enhancing speech quality and 7.14% in terms of improving speech intelligibility. We exploit a multi-task learning framework that simultaneously performs lip-reading (transcribing video components to text) while reconstructing missing parts of the associated speech.
Read more6/4/2024
0
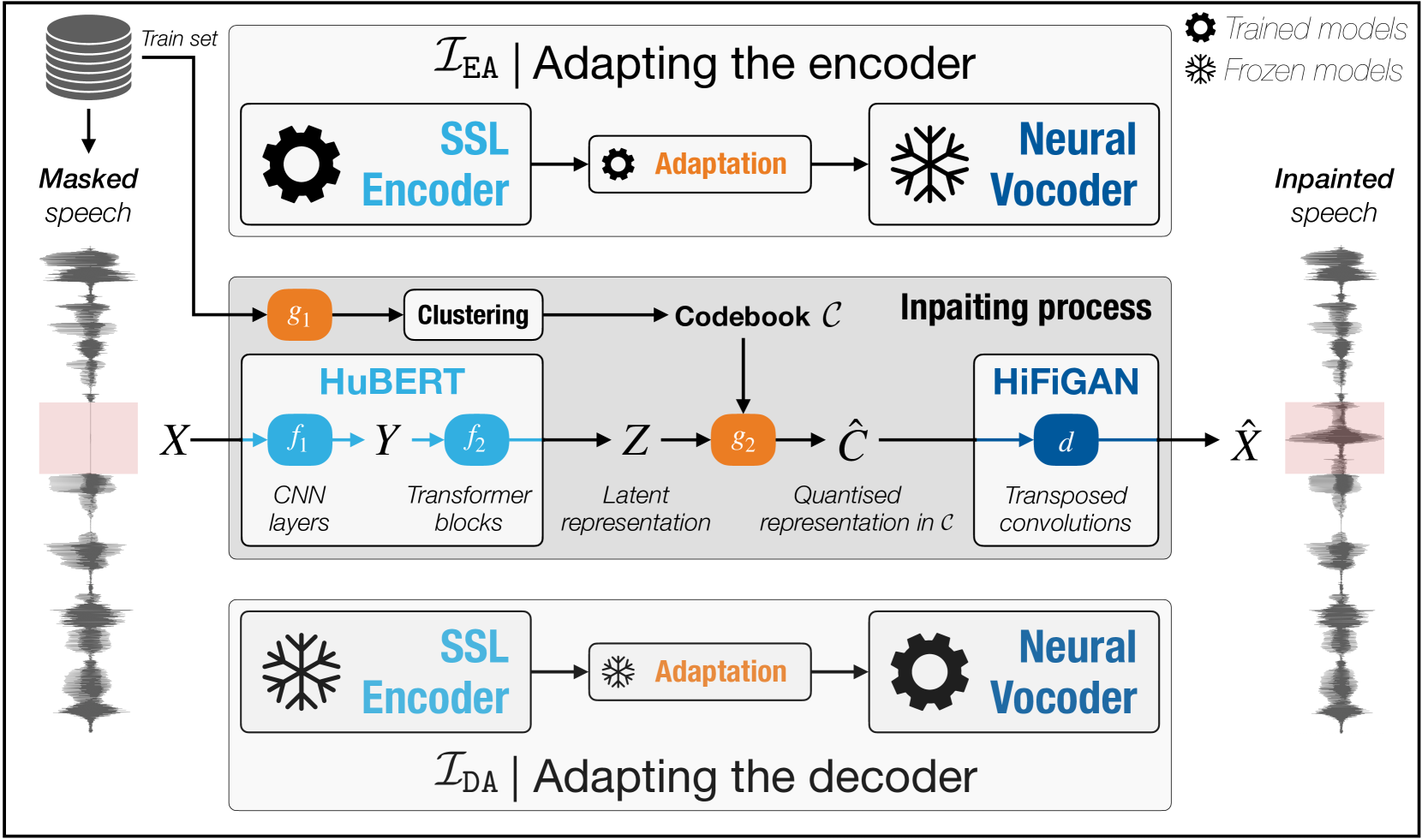
Fill in the Gap! Combining Self-supervised Representation Learning with Neural Audio Synthesis for Speech Inpainting
Ihab Asaad, Maxime Jacquelin, Olivier Perrotin, Laurent Girin, Thomas Hueber
Most speech self-supervised learning (SSL) models are trained with a pretext task which consists in predicting missing parts of the input signal, either future segments (causal prediction) or segments masked anywhere within the input (non-causal prediction). Learned speech representations can then be efficiently transferred to downstream tasks (e.g., automatic speech or speaker recognition). In the present study, we investigate the use of a speech SSL model for speech inpainting, that is reconstructing a missing portion of a speech signal from its surrounding context, i.e., fulfilling a downstream task that is very similar to the pretext task. To that purpose, we combine an SSL encoder, namely HuBERT, with a neural vocoder, namely HiFiGAN, playing the role of a decoder. In particular, we propose two solutions to match the HuBERT output with the HiFiGAN input, by freezing one and fine-tuning the other, and vice versa. Performance of both approaches was assessed in single- and multi-speaker settings, for both informed and blind inpainting configurations (i.e., the position of the mask is known or unknown, respectively), with different objective metrics and a perceptual evaluation. Performances show that if both solutions allow to correctly reconstruct signal portions up to the size of 200ms (and even 400ms in some cases), fine-tuning the SSL encoder provides a more accurate signal reconstruction in the single-speaker setting case, while freezing it (and training the neural vocoder instead) is a better strategy when dealing with multi-speaker data.
Read more5/31/2024
0
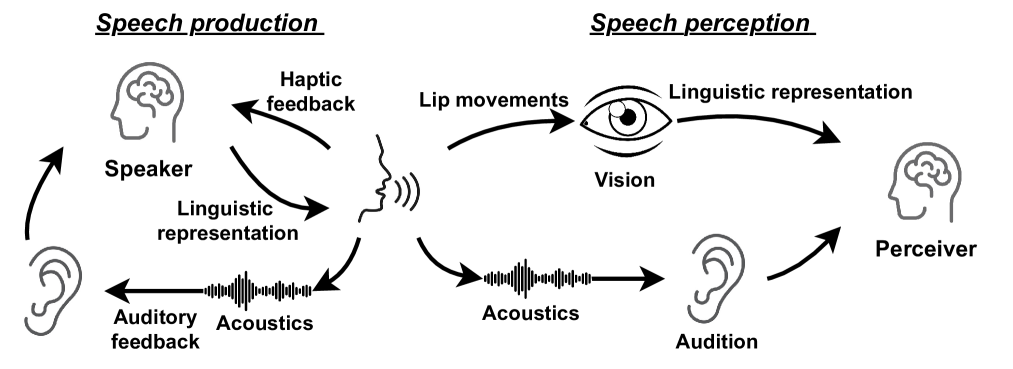
Separate in the Speech Chain: Cross-Modal Conditional Audio-Visual Target Speech Extraction
Zhaoxi Mu, Xinyu Yang
The integration of visual cues has revitalized the performance of the target speech extraction task, elevating it to the forefront of the field. Nevertheless, this multi-modal learning paradigm often encounters the challenge of modality imbalance. In audio-visual target speech extraction tasks, the audio modality tends to dominate, potentially overshadowing the importance of visual guidance. To tackle this issue, we propose AVSepChain, drawing inspiration from the speech chain concept. Our approach partitions the audio-visual target speech extraction task into two stages: speech perception and speech production. In the speech perception stage, audio serves as the dominant modality, while visual information acts as the conditional modality. Conversely, in the speech production stage, the roles are reversed. This transformation of modality status aims to alleviate the problem of modality imbalance. Additionally, we introduce a contrastive semantic matching loss to ensure that the semantic information conveyed by the generated speech aligns with the semantic information conveyed by lip movements during the speech production stage. Through extensive experiments conducted on multiple benchmark datasets for audio-visual target speech extraction, we showcase the superior performance achieved by our proposed method.
Read more5/7/2024