Fill in the Gap! Combining Self-supervised Representation Learning with Neural Audio Synthesis for Speech Inpainting
2405.20101
0
0
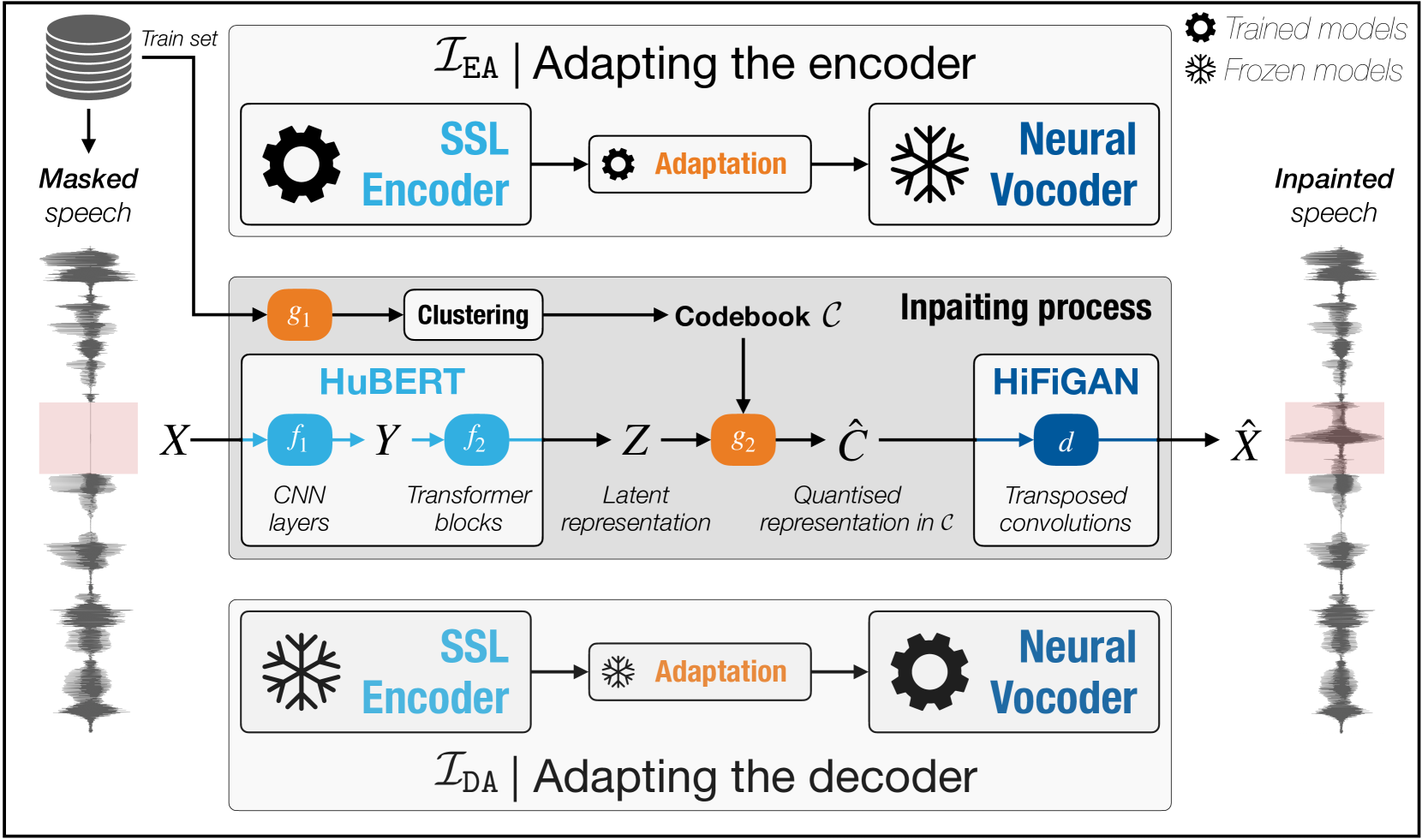
Abstract
Most speech self-supervised learning (SSL) models are trained with a pretext task which consists in predicting missing parts of the input signal, either future segments (causal prediction) or segments masked anywhere within the input (non-causal prediction). Learned speech representations can then be efficiently transferred to downstream tasks (e.g., automatic speech or speaker recognition). In the present study, we investigate the use of a speech SSL model for speech inpainting, that is reconstructing a missing portion of a speech signal from its surrounding context, i.e., fulfilling a downstream task that is very similar to the pretext task. To that purpose, we combine an SSL encoder, namely HuBERT, with a neural vocoder, namely HiFiGAN, playing the role of a decoder. In particular, we propose two solutions to match the HuBERT output with the HiFiGAN input, by freezing one and fine-tuning the other, and vice versa. Performance of both approaches was assessed in single- and multi-speaker settings, for both informed and blind inpainting configurations (i.e., the position of the mask is known or unknown, respectively), with different objective metrics and a perceptual evaluation. Performances show that if both solutions allow to correctly reconstruct signal portions up to the size of 200ms (and even 400ms in some cases), fine-tuning the SSL encoder provides a more accurate signal reconstruction in the single-speaker setting case, while freezing it (and training the neural vocoder instead) is a better strategy when dealing with multi-speaker data.
Create account to get full access
Overview
- This paper proposes a novel approach to speech inpainting, which involves filling in missing or corrupted segments of audio data.
- The key idea is to combine self-supervised representation learning with neural audio synthesis to enable high-quality speech reconstruction.
- The authors leverage a self-supervised model to extract robust speech features, which are then used to drive a neural vocoder for realistic speech synthesis.
- This approach allows for effective restoration of missing speech content, with applications in areas like speech enhancement and audio editing.
Plain English Explanation
In this research, the authors present a new way to "fill in the gaps" in speech recordings. When you have an audio file with parts of the speech missing or damaged, it can be challenging to reconstruct the full, high-quality audio. The researchers' solution is to combine two powerful machine learning techniques: self-supervised representation learning and neural audio synthesis.
First, they use a self-supervised model to analyze the speech features in the available audio data. This allows the model to learn what natural, high-quality speech sounds like, without being explicitly trained on complete speech samples. Then, they feed these learned speech representations into a neural network that can generate synthetic speech. This neural vocoder is able to "fill in the gaps" by producing realistic speech to replace the missing or corrupted segments.
The key innovation is bringing these two components together - the self-supervised feature extraction and the neural speech synthesis. By leveraging the strengths of both, the system can effectively restore the missing parts of the audio while maintaining natural-sounding, high-fidelity speech. This has applications in areas like speech enhancement and audio editing, where having a robust way to reconstruct corrupted speech is very valuable.
Technical Explanation
The paper presents a novel approach for speech inpainting, which aims to reconstruct missing or corrupted segments of audio data. The core idea is to combine self-supervised representation learning with neural audio synthesis to enable high-quality speech reconstruction.
The authors first employ a self-supervised model to extract robust speech features from the available audio data. This self-supervised representation learning approach allows the model to learn meaningful speech representations without the need for labeled speech samples. The learned features capture the underlying structure and characteristics of natural speech.
These speech representations are then used to drive a neural vocoder, which is a deep learning-based speech synthesis model. The neural vocoder takes the learned features as input and generates realistic, high-fidelity speech to fill in the missing or corrupted segments of the audio. This neural audio synthesis component is crucial for producing natural-sounding speech that seamlessly integrates with the available audio.
The authors evaluate their approach on several speech inpainting benchmarks, demonstrating its effectiveness in restoring high-quality speech from partially corrupted audio. The proposed method outperforms traditional speech enhancement techniques, highlighting the benefits of combining self-supervised representation learning and neural audio synthesis for this task.
Critical Analysis
The paper presents a well-designed and promising approach to speech inpainting, but there are a few areas that could be explored further:
-
Robustness and Generalization: While the authors demonstrate the effectiveness of their method on specific inpainting benchmarks, it would be valuable to assess its robustness and generalization capabilities across a wider range of speech data, including different languages, accents, and speaking styles. Further evaluating the model's performance under more diverse conditions would help establish its practical applicability.
-
Interpretability and Explainability: The paper does not provide much insight into the internal workings of the self-supervised representation learning component and how it captures the essential features of speech. Improving the interpretability and explainability of the learned representations could lead to a better understanding of the model's decision-making process and suggest avenues for further refinement.
-
Integration with Other Speech Tasks: The authors focus solely on the speech inpainting task, but it would be valuable to explore how this approach could be integrated with other speech-related tasks, such as speech recognition, speaker identification, or emotion detection. Investigating potential synergies and transfer learning opportunities could expand the practical applications of this research.
Overall, the proposed method represents a promising step forward in the field of speech inpainting, demonstrating the benefits of combining self-supervised representation learning and neural audio synthesis. Further research to address the identified areas could lead to even more robust and versatile speech restoration capabilities.
Conclusion
This paper presents a novel approach to speech inpainting that leverages self-supervised representation learning and neural audio synthesis. By extracting robust speech features from partially corrupted audio data and using them to drive a neural vocoder, the method can effectively reconstruct high-quality speech while filling in missing or damaged segments.
The key innovation is the integration of these two powerful machine learning techniques, which allows the system to capitalize on the strengths of both self-supervised feature extraction and neural speech generation. This approach outperforms traditional speech enhancement methods, demonstrating its potential for applications in areas like audio editing, speech enhancement, and audio restoration.
While the paper presents promising results, there are opportunities to further explore the robustness, interpretability, and integration of this approach with other speech-related tasks. Continued research in this direction could lead to even more advanced and versatile speech inpainting solutions, with significant practical implications for various industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Efficient infusion of self-supervised representations in Automatic Speech Recognition
Darshan Prabhu, Sai Ganesh Mirishkar, Pankaj Wasnik
0
0
Self-supervised learned (SSL) models such as Wav2vec and HuBERT yield state-of-the-art results on speech-related tasks. Given the effectiveness of such models, it is advantageous to use them in conventional ASR systems. While some approaches suggest incorporating these models as a trainable encoder or a learnable frontend, training such systems is extremely slow and requires a lot of computation cycles. In this work, we propose two simple approaches that use (1) framewise addition and (2) cross-attention mechanisms to efficiently incorporate the representations from the SSL model(s) into the ASR architecture, resulting in models that are comparable in size with standard encoder-decoder conformer systems while also avoiding the usage of SSL models during training. Our approach results in faster training and yields significant performance gains on the Librispeech and Tedlium datasets compared to baselines. We further provide detailed analysis and ablation studies that demonstrate the effectiveness of our approach.
4/22/2024
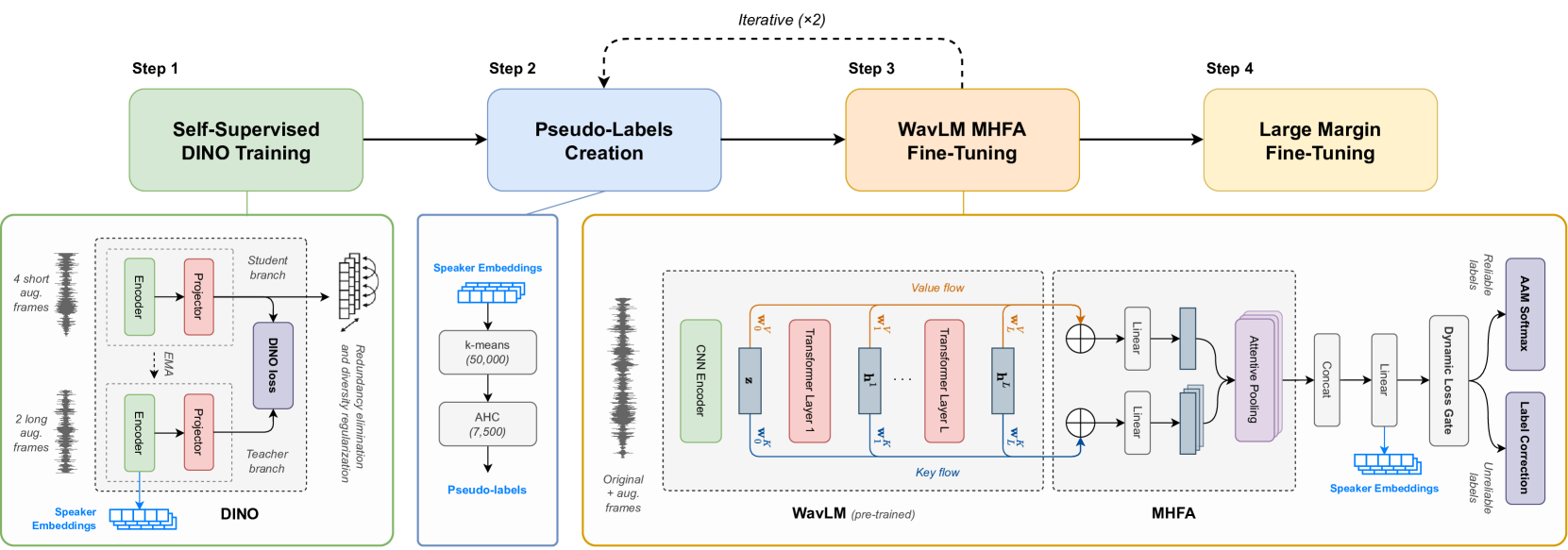
Towards Supervised Performance on Speaker Verification with Self-Supervised Learning by Leveraging Large-Scale ASR Models
Victor Miara, Theo Lepage, Reda Dehak
0
0
Recent advancements in Self-Supervised Learning (SSL) have shown promising results in Speaker Verification (SV). However, narrowing the performance gap with supervised systems remains an ongoing challenge. Several studies have observed that speech representations from large-scale ASR models contain valuable speaker information. This work explores the limitations of fine-tuning these models for SV using an SSL contrastive objective in an end-to-end approach. Then, we propose a framework to learn speaker representations in an SSL context by fine-tuning a pre-trained WavLM with a supervised loss using pseudo-labels. Initial pseudo-labels are derived from an SSL DINO-based model and are iteratively refined by clustering the model embeddings. Our method achieves 0.99% EER on VoxCeleb1-O, establishing the new state-of-the-art on self-supervised SV. As this performance is close to our supervised baseline of 0.94% EER, this contribution is a step towards supervised performance on SV with SSL.
6/5/2024
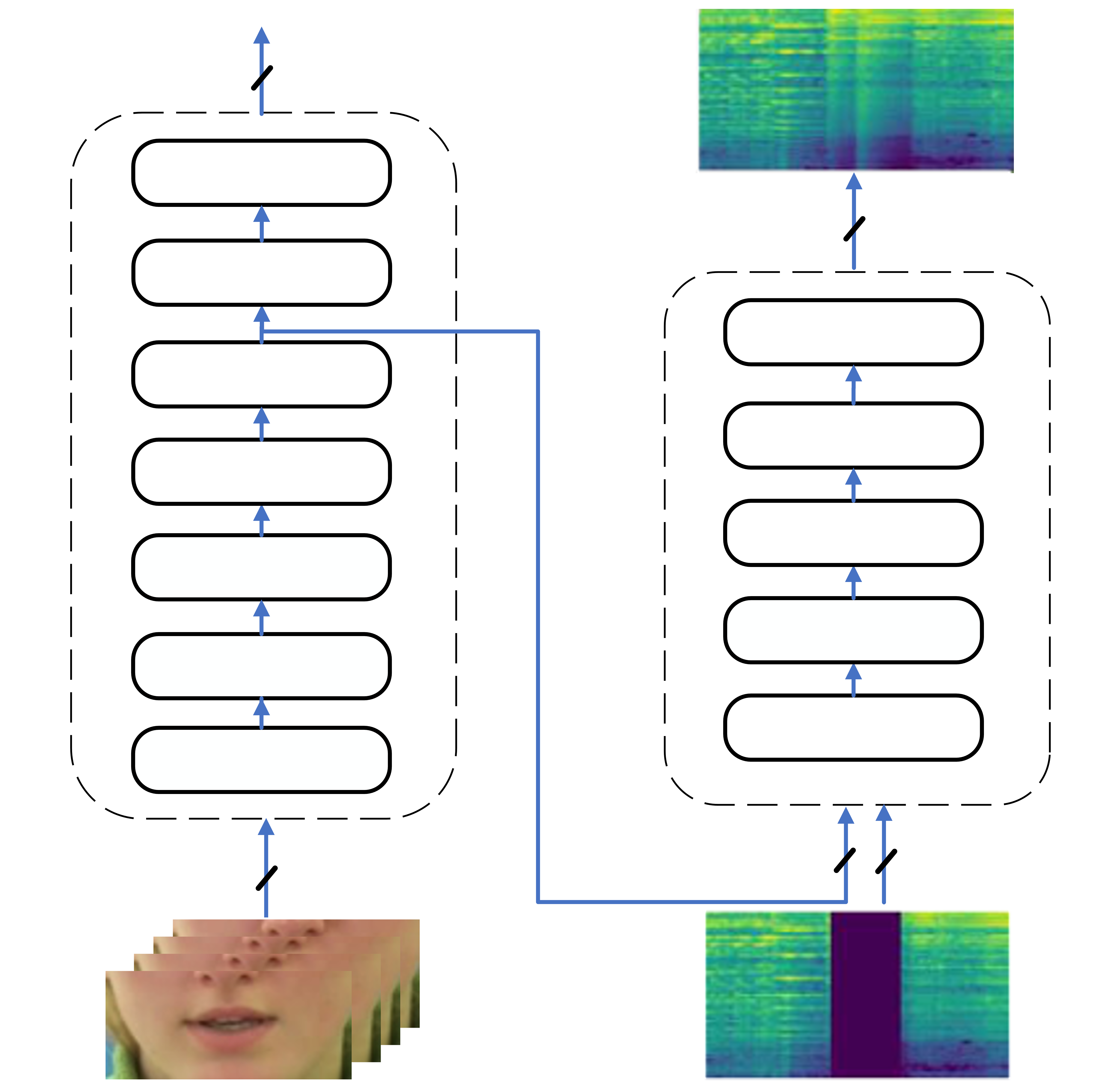
Robust Multi-Modal Speech In-Painting: A Sequence-to-Sequence Approach
Mahsa Kadkhodaei Elyaderani, Shahram Shirani
0
0
The process of reconstructing missing parts of speech audio from context is called speech in-painting. Human perception of speech is inherently multi-modal, involving both audio and visual (AV) cues. In this paper, we introduce and study a sequence-to-sequence (seq2seq) speech in-painting model that incorporates AV features. Our approach extends AV speech in-painting techniques to scenarios where both audio and visual data may be jointly corrupted. To achieve this, we employ a multi-modal training paradigm that boosts the robustness of our model across various conditions involving acoustic and visual distortions. This makes our distortion-aware model a plausible solution for real-world challenging environments. We compare our method with existing transformer-based and recurrent neural network-based models, which attempt to reconstruct missing speech gaps ranging from a few milliseconds to over a second. Our experimental results demonstrate that our novel seq2seq architecture outperforms the state-of-the-art transformer solution by 38.8% in terms of enhancing speech quality and 7.14% in terms of improving speech intelligibility. We exploit a multi-task learning framework that simultaneously performs lip-reading (transcribing video components to text) while reconstructing missing parts of the associated speech.
6/4/2024

LASER: Learning by Aligning Self-supervised Representations of Speech for Improving Content-related Tasks
Amit Meghanani, Thomas Hain
0
0
Self-supervised learning (SSL)-based speech models are extensively used for full-stack speech processing. However, it has been observed that improving SSL-based speech representations using unlabeled speech for content-related tasks is challenging and computationally expensive. Recent attempts have been made to address this issue with cost-effective self-supervised fine-tuning (SSFT) approaches. Continuing in this direction, a cost-effective SSFT method named LASER: Learning by Aligning Self-supervised Representations is presented. LASER is based on the soft-DTW alignment loss with temporal regularisation term. Experiments are conducted with HuBERT and WavLM models and evaluated on the SUPERB benchmark for two content-related tasks: automatic speech recognition (ASR) and phoneme recognition (PR). A relative improvement of 3.7% and 8.2% for HuBERT, and 4.1% and 11.7% for WavLM are observed, for the ASR and PR tasks respectively, with only < 3 hours of fine-tuning on a single GPU.
6/14/2024