SequenceMatch: Imitation Learning for Autoregressive Sequence Modelling with Backtracking
2306.05426
82
0
🔗
Abstract
In many domains, autoregressive models can attain high likelihood on the task of predicting the next observation. However, this maximum-likelihood (MLE) objective does not necessarily match a downstream use-case of autoregressively generating high-quality sequences. The MLE objective weights sequences proportionally to their frequency under the data distribution, with no guidance for the model's behaviour out of distribution (OOD): leading to compounding error during autoregressive generation. In order to address this compounding error problem, we formulate sequence generation as an imitation learning (IL) problem. This allows us to minimize a variety of divergences between the distribution of sequences generated by an autoregressive model and sequences from a dataset, including divergences with weight on OOD generated sequences. The IL framework also allows us to incorporate backtracking by introducing a backspace action into the generation process. This further mitigates the compounding error problem by allowing the model to revert a sampled token if it takes the sequence OOD. Our resulting method, SequenceMatch, can be implemented without adversarial training or architectural changes. We identify the SequenceMatch-$chi^2$ divergence as a more suitable training objective for autoregressive models which are used for generation. We show that empirically, SequenceMatch training leads to improvements over MLE on text generation with language models and arithmetic.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Autoregressive models can predict the next observation well, but this maximum-likelihood (MLE) objective does not necessarily lead to high-quality sequence generation.
- The MLE objective focuses on sequence frequency, without guidance for behavior outside the training distribution, leading to compounding errors during generation.
- To address this, the paper formulates sequence generation as an imitation learning (IL) problem, minimizing divergences between the generated and training distributions, including for out-of-distribution (OOD) sequences.
- The IL framework also allows incorporating backtracking, where the model can revert a sampled token if it takes the sequence OOD.
- The resulting method, SequenceMatch, can be implemented without adversarial training or architectural changes.
- The SequenceMatch-$\chi^2$ divergence is identified as a more suitable training objective for autoregressive generation models.
Plain English Explanation
Autoregressive models are good at predicting the next piece of a sequence, like the next word in a sentence. However, this doesn't necessarily mean they can generate high-quality, coherent sequences. The standard training objective, called maximum-likelihood estimation (MLE), focuses on how likely each sequence is in the training data. This can lead to issues when the model tries to generate sequences that are very different from the training data, as the errors can compound over time.
To address this, the paper proposes formulating sequence generation as an "imitation learning" problem. This means training the model to mimic the distribution of sequences in the training data, including penalizing sequences that are very different. The imitation learning framework also allows the model to "backtrack" and undo previous decisions if it starts generating poor sequences.
The resulting method, called SequenceMatch, can be implemented without complex changes to the model architecture or training process. The authors identify a specific type of divergence measure, called the SequenceMatch-$\chi^2$ divergence, as particularly well-suited for training autoregressive models for generation tasks.
Technical Explanation
The paper proposes addressing the compounding error problem in autoregressive generation by formulating the task as an "imitation learning" problem. This allows minimizing a variety of divergences between the distribution of sequences generated by the autoregressive model and the distribution of sequences in the training data.
Importantly, this includes divergences that place weight on out-of-distribution (OOD) generated sequences, which the standard maximum-likelihood estimation (MLE) objective does not. The imitation learning framework also enables incorporating a "backspace" action, where the model can revert a previously sampled token if it takes the sequence OOD.
The resulting method, called SequenceMatch, can be implemented without adversarial training or architectural changes to the autoregressive model. The authors identify the SequenceMatch-$\chi^2$ divergence as a particularly suitable training objective, as it focuses on matching the broader characteristics of the data distribution rather than just the highest-likelihood sequences.
The paper demonstrates empirical improvements of SequenceMatch over MLE training on text generation tasks using language models, as well as on an arithmetic task.
Critical Analysis
The paper presents a novel approach to training autoregressive models for high-quality sequence generation, addressing a key limitation of the standard MLE objective. The imitation learning framework and incorporation of backtracking are interesting technical contributions.
However, the paper does not deeply explore the limitations of the SequenceMatch approach. For example, it is not clear how the method would scale to very large or diverse datasets, or how sensitive the performance is to hyperparameter choices. Additionally, the relationship between the internal language model and sequence-discriminative objectives could be further investigated.
The robustness of the SequenceMatch objectives to distributional shift or adversarial perturbations is also an open question. Lastly, the paper does not situate the SequenceMatch approach within the broader context of sequence-to-sequence generation methods, which could provide additional insight.
Overall, the paper presents a promising direction for improving autoregressive generation, but more research is needed to fully understand the strengths, weaknesses, and scope of applicability of the SequenceMatch approach.
Conclusion
This paper proposes a novel approach to training autoregressive models for high-quality sequence generation, formulating the task as an imitation learning problem. By minimizing divergences between the generated and training distributions, including for out-of-distribution sequences, and incorporating a backtracking mechanism, the SequenceMatch method can outperform standard maximum-likelihood training.
The key insight is that the MLE objective, while effective for predicting the next observation, does not necessarily align with generating coherent, high-quality sequences. The imitation learning framework provides a principled way to address this mismatch, with the potential for broader applicability in other generative modeling domains.
While the paper demonstrates promising empirical results, further research is needed to fully understand the strengths, limitations, and best practices for applying the SequenceMatch approach. Nonetheless, this work represents an important step forward in improving the sequence generation capabilities of autoregressive models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
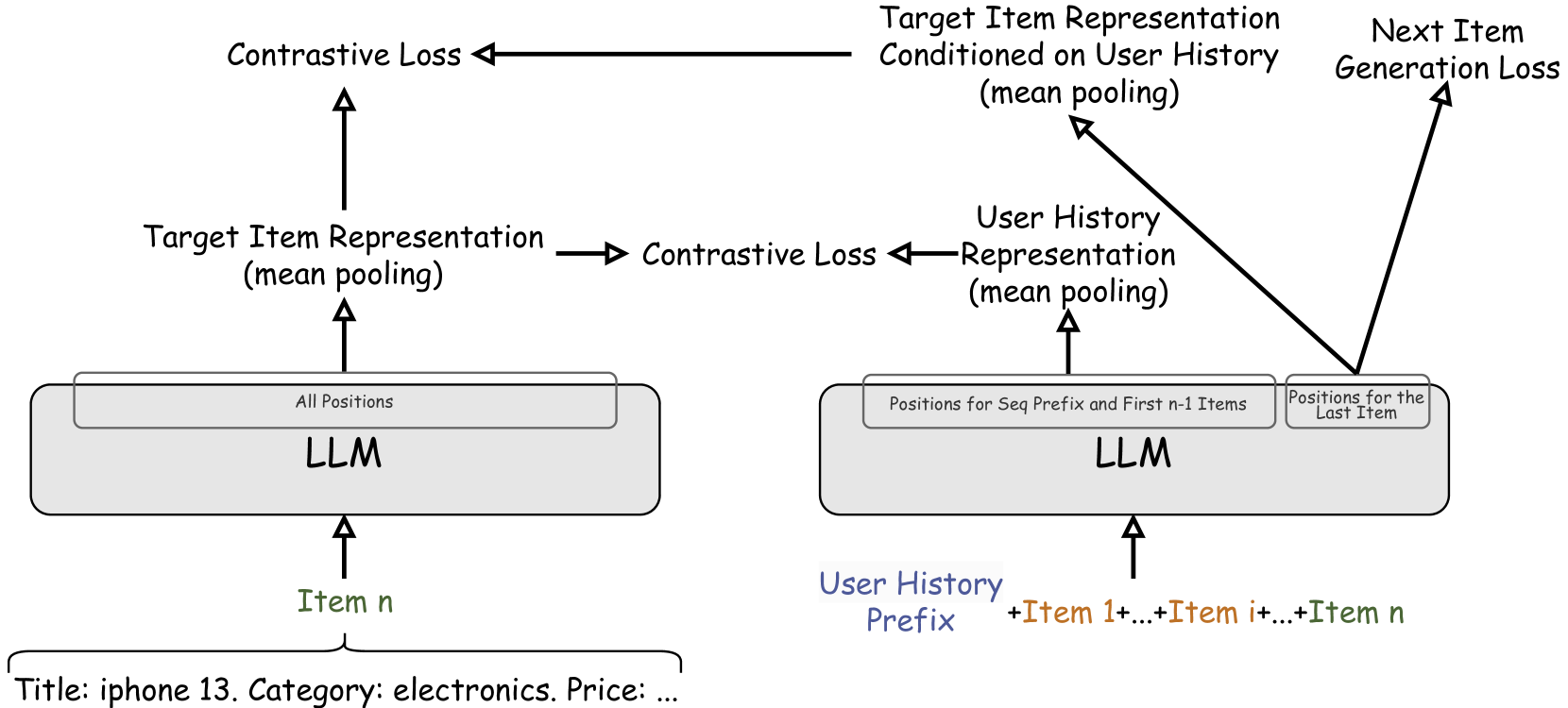
CALRec: Contrastive Alignment of Generative LLMs For Sequential Recommendation
Yaoyiran Li, Xiang Zhai, Moustafa Alzantot, Keyi Yu, Ivan Vuli'c, Anna Korhonen, Mohamed Hammad
0
0
Traditional recommender systems such as matrix factorization methods rely on learning a shared dense embedding space to represent both items and user preferences. Sequence models such as RNN, GRUs, and, recently, Transformers have also excelled in the task of sequential recommendation. This task requires understanding the sequential structure present in users' historical interactions to predict the next item they may like. Building upon the success of Large Language Models (LLMs) in a variety of tasks, researchers have recently explored using LLMs that are pretrained on vast corpora of text for sequential recommendation. To use LLMs in sequential recommendations, both the history of user interactions and the model's prediction of the next item are expressed in text form. We propose CALRec, a two-stage LLM finetuning framework that finetunes a pretrained LLM in a two-tower fashion using a mixture of two contrastive losses and a language modeling loss: the LLM is first finetuned on a data mixture from multiple domains followed by another round of target domain finetuning. Our model significantly outperforms many state-of-the-art baselines (+37% in Recall@1 and +24% in NDCG@10) and systematic ablation studies reveal that (i) both stages of finetuning are crucial, and, when combined, we achieve improved performance, and (ii) contrastive alignment is effective among the target domains explored in our experiments.
5/7/2024

Reinforcement Learning for Edit-Based Non-Autoregressive Neural Machine Translation
Hao Wang, Tetsuro Morimura, Ukyo Honda, Daisuke Kawahara
0
0
Non-autoregressive (NAR) language models are known for their low latency in neural machine translation (NMT). However, a performance gap exists between NAR and autoregressive models due to the large decoding space and difficulty in capturing dependency between target words accurately. Compounding this, preparing appropriate training data for NAR models is a non-trivial task, often exacerbating exposure bias. To address these challenges, we apply reinforcement learning (RL) to Levenshtein Transformer, a representative edit-based NAR model, demonstrating that RL with self-generated data can enhance the performance of edit-based NAR models. We explore two RL approaches: stepwise reward maximization and episodic reward maximization. We discuss the respective pros and cons of these two approaches and empirically verify them. Moreover, we experimentally investigate the impact of temperature setting on performance, confirming the importance of proper temperature setting for NAR models' training.
5/3/2024
💬
On the Relation between Internal Language Model and Sequence Discriminative Training for Neural Transducers
Zijian Yang, Wei Zhou, Ralf Schluter, Hermann Ney
0
0
Internal language model (ILM) subtraction has been widely applied to improve the performance of the RNN-Transducer with external language model (LM) fusion for speech recognition. In this work, we show that sequence discriminative training has a strong correlation with ILM subtraction from both theoretical and empirical points of view. Theoretically, we derive that the global optimum of maximum mutual information (MMI) training shares a similar formula as ILM subtraction. Empirically, we show that ILM subtraction and sequence discriminative training achieve similar effects across a wide range of experiments on Librispeech, including both MMI and minimum Bayes risk (MBR) criteria, as well as neural transducers and LMs of both full and limited context. The benefit of ILM subtraction also becomes much smaller after sequence discriminative training. We also provide an in-depth study to show that sequence discriminative training has a minimal effect on the commonly used zero-encoder ILM estimation, but a joint effect on both encoder and prediction + joint network for posterior probability reshaping including both ILM and blank suppression.
4/16/2024
🏅
Robust Reinforcement Learning Objectives for Sequential Recommender Systems
Melissa Mozifian, Tristan Sylvain, Dave Evans, Lili Meng
0
0
Attention-based sequential recommendation methods have shown promise in accurately capturing users' evolving interests from their past interactions. Recent research has also explored the integration of reinforcement learning (RL) into these models, in addition to generating superior user representations. By framing sequential recommendation as an RL problem with reward signals, we can develop recommender systems that incorporate direct user feedback in the form of rewards, enhancing personalization for users. Nonetheless, employing RL algorithms presents challenges, including off-policy training, expansive combinatorial action spaces, and the scarcity of datasets with sufficient reward signals. Contemporary approaches have attempted to combine RL and sequential modeling, incorporating contrastive-based objectives and negative sampling strategies for training the RL component. In this work, we further emphasize the efficacy of contrastive-based objectives paired with augmentation to address datasets with extended horizons. Additionally, we recognize the potential instability issues that may arise during the application of negative sampling. These challenges primarily stem from the data imbalance prevalent in real-world datasets, which is a common issue in offline RL contexts. Furthermore, we introduce an enhanced methodology aimed at providing a more effective solution to these challenges. Experimental results across several real datasets show our method with increased robustness and state-of-the-art performance.
4/19/2024