SG-GS: Photo-realistic Animatable Human Avatars with Semantically-Guided Gaussian Splatting

0

Sign in to get full access
Overview
- This paper introduces a new method called SG-GS (Semantically-Guided Gaussian Splatting) for generating photo-realistic, animatable human avatars.
- The key idea is to use Gaussian splats to represent the human body and guide the generation process with semantic information.
- This allows for high-quality, detailed reconstructions that can be seamlessly animated.
Plain English Explanation
The paper presents a new way to create virtual human characters, or "avatars," that look very realistic and can be animated to move and act in a natural way. The key innovation is the use of "Gaussian splats" - a type of 3D shape that can represent the human body in detail.
These Gaussian splats are guided by semantic information, which means the system understands the different parts of the body (like the head, arms, etc.) and uses that knowledge to generate highly accurate and lifelike avatars. This semantic guidance helps produce avatars that not only look photo-realistic, but can also be smoothly animated to perform various movements and actions.
Compared to previous methods, this approach results in avatars that are both visually stunning and capable of natural, expressive motion. This could have applications in areas like video games, virtual reality, and film/TV visual effects, where realistic and animatable human characters are in high demand.
Technical Explanation
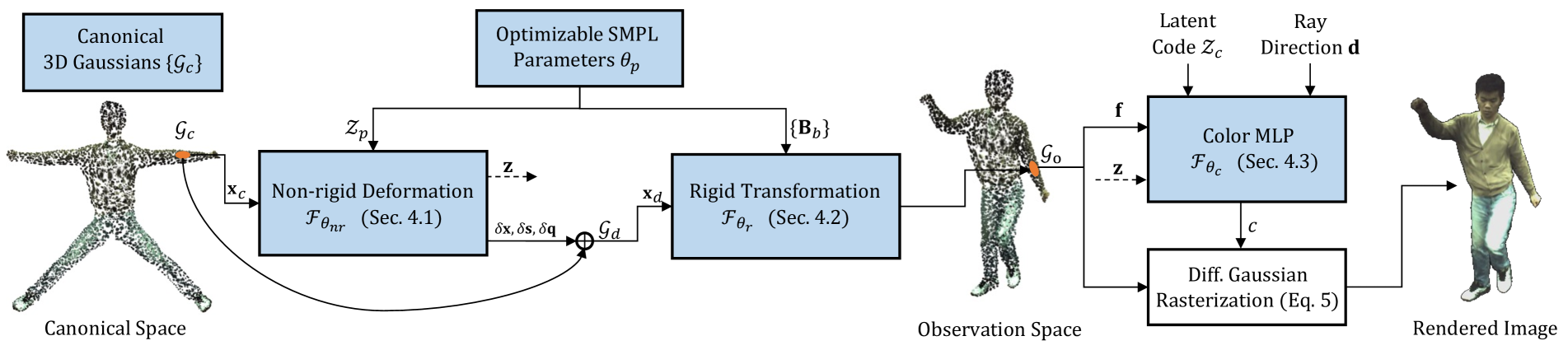
The SG-GS method represents the human body using a set of Gaussian splats, which are 3D shapes with a Gaussian distribution of density. These splats are guided by semantic information - the system understands the different anatomical parts and their relationships, and uses this knowledge to assemble the splats into a coherent, detailed human form.
The key components of the SG-GS architecture include:
- A 3D reconstruction network that takes in 2D images and outputs a set of Gaussian splats representing the body shape.
- A semantic segmentation network that identifies the different anatomical regions (head, torso, limbs, etc.) in the splat representation.
- An animation module that can deform the splats to produce realistic motion while preserving the overall shape.
By combining these components, SG-GS is able to generate high-fidelity, animatable human avatars from 2D input images. The semantic guidance ensures the avatars maintain their anatomical integrity and natural appearance during animation.
Critical Analysis
The paper presents a compelling approach for creating photo-realistic, animatable human avatars. The key strengths are the use of Gaussian splats to represent the body in detail, and the integration of semantic information to guide the reconstruction and animation processes.
One potential limitation is that the method relies on 2D input images, which may constrain the range of body shapes and poses that can be accurately reconstructed. Extending the approach to work with richer 3D data sources could help overcome this.
Additionally, while the paper demonstrates impressive results, the computational efficiency and real-time performance of the SG-GS system is not fully explored. Assessing its viability for applications that require fast, low-latency avatar generation would be an important area for further research.
Overall, this work represents an important advance in the field of photorealistic human avatar generation, and the ideas could have significant impact on diverse applications requiring high-fidelity, animatable virtual characters.
Conclusion
The SG-GS method presented in this paper offers a novel approach to generating photo-realistic, animatable human avatars. By representing the body with semantic-guided Gaussian splats, the system is able to produce detailed, anatomically-correct virtual characters that can be seamlessly animated.
This technique could have wide-ranging applications in areas such as video games, virtual reality, and film/TV visual effects, where realistic and expressive human characters are in high demand. The continued advancement of such avatar generation capabilities has the potential to significantly enhance the realism and immersion of virtual experiences across many domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SG-GS: Photo-realistic Animatable Human Avatars with Semantically-Guided Gaussian Splatting
Haoyu Zhao, Chen Yang, Hao Wang, Xingyue Zhao, Wei Shen
Reconstructing photo-realistic animatable human avatars from monocular videos remains challenging in computer vision and graphics. Recently, methods using 3D Gaussians to represent the human body have emerged, offering faster optimization and real-time rendering. However, due to ignoring the crucial role of human body semantic information which represents the intrinsic structure and connections within the human body, they fail to achieve fine-detail reconstruction of dynamic human avatars. To address this issue, we propose SG-GS, which uses semantics-embedded 3D Gaussians, skeleton-driven rigid deformation, and non-rigid cloth dynamics deformation to create photo-realistic animatable human avatars from monocular videos. We then design a Semantic Human-Body Annotator (SHA) which utilizes SMPL's semantic prior for efficient body part semantic labeling. The generated labels are used to guide the optimization of Gaussian semantic attributes. To address the limited receptive field of point-level MLPs for local features, we also propose a 3D network that integrates geometric and semantic associations for human avatar deformation. We further implement three key strategies to enhance the semantic accuracy of 3D Gaussians and rendering quality: semantic projection with 2D regularization, semantic-guided density regularization and semantic-aware regularization with neighborhood consistency. Extensive experiments demonstrate that SG-GS achieves state-of-the-art geometry and appearance reconstruction performance.
Read more8/20/2024
0
3DGS-Avatar: Animatable Avatars via Deformable 3D Gaussian Splatting
Zhiyin Qian, Shaofei Wang, Marko Mihajlovic, Andreas Geiger, Siyu Tang
We introduce an approach that creates animatable human avatars from monocular videos using 3D Gaussian Splatting (3DGS). Existing methods based on neural radiance fields (NeRFs) achieve high-quality novel-view/novel-pose image synthesis but often require days of training, and are extremely slow at inference time. Recently, the community has explored fast grid structures for efficient training of clothed avatars. Albeit being extremely fast at training, these methods can barely achieve an interactive rendering frame rate with around 15 FPS. In this paper, we use 3D Gaussian Splatting and learn a non-rigid deformation network to reconstruct animatable clothed human avatars that can be trained within 30 minutes and rendered at real-time frame rates (50+ FPS). Given the explicit nature of our representation, we further introduce as-isometric-as-possible regularizations on both the Gaussian mean vectors and the covariance matrices, enhancing the generalization of our model on highly articulated unseen poses. Experimental results show that our method achieves comparable and even better performance compared to state-of-the-art approaches on animatable avatar creation from a monocular input, while being 400x and 250x faster in training and inference, respectively.
Read more4/5/2024
⛏️
0
Animatable 3D Gaussian: Fast and High-Quality Reconstruction of Multiple Human Avatars
Yang Liu, Xiang Huang, Minghan Qin, Qinwei Lin, Haoqian Wang
Neural radiance fields are capable of reconstructing high-quality drivable human avatars but are expensive to train and render and not suitable for multi-human scenes with complex shadows. To reduce consumption, we propose Animatable 3D Gaussian, which learns human avatars from input images and poses. We extend 3D Gaussians to dynamic human scenes by modeling a set of skinned 3D Gaussians and a corresponding skeleton in canonical space and deforming 3D Gaussians to posed space according to the input poses. We introduce a multi-head hash encoder for pose-dependent shape and appearance and a time-dependent ambient occlusion module to achieve high-quality reconstructions in scenes containing complex motions and dynamic shadows. On both novel view synthesis and novel pose synthesis tasks, our method achieves higher reconstruction quality than InstantAvatar with less training time (1/60), less GPU memory (1/4), and faster rendering speed (7x). Our method can be easily extended to multi-human scenes and achieve comparable novel view synthesis results on a scene with ten people in only 25 seconds of training.
Read more7/30/2024

0
GST: Precise 3D Human Body from a Single Image with Gaussian Splatting Transformers
Lorenza Prospero, Abdullah Hamdi, Joao F. Henriques, Christian Rupprecht
Reconstructing realistic 3D human models from monocular images has significant applications in creative industries, human-computer interfaces, and healthcare. We base our work on 3D Gaussian Splatting (3DGS), a scene representation composed of a mixture of Gaussians. Predicting such mixtures for a human from a single input image is challenging, as it is a non-uniform density (with a many-to-one relationship with input pixels) with strict physical constraints. At the same time, it needs to be flexible to accommodate a variety of clothes and poses. Our key observation is that the vertices of standardized human meshes (such as SMPL) can provide an adequate density and approximate initial position for Gaussians. We can then train a transformer model to jointly predict comparatively small adjustments to these positions, as well as the other Gaussians' attributes and the SMPL parameters. We show empirically that this combination (using only multi-view supervision) can achieve fast inference of 3D human models from a single image without test-time optimization, expensive diffusion models, or 3D points supervision. We also show that it can improve 3D pose estimation by better fitting human models that account for clothes and other variations. The code is available on the project website https://abdullahamdi.com/gst/ .
Read more9/9/2024