SGHateCheck: Functional Tests for Detecting Hate Speech in Low-Resource Languages of Singapore

0
🗣️
Sign in to get full access
Overview
- Introduces a new framework called SGHateCheck for detecting hate speech in the linguistic and cultural context of Singapore and Southeast Asia
- Extends the functional testing approach of previous frameworks like HateCheck and MHC
- Employs large language models for translation and paraphrasing into Singapore's main languages, then refines these with native annotators
- Reveals critical flaws in state-of-the-art hate speech detection models, highlighting their inadequacy for sensitive content moderation in diverse linguistic environments
Plain English Explanation
The researchers developed a new framework called SGHateCheck to detect hate speech, specifically tailored for the languages and cultures of Singapore and Southeast Asia. It builds on previous approaches like HateCheck and MHC, using large language models to translate and rephrase content into Singapore's main languages, then having native speakers review and refine the results.
This is important because current hate speech detection models often struggle to accurately identify problematic content in diverse linguistic and cultural contexts. The researchers found that these state-of-the-art models have critical flaws when it comes to moderating sensitive content, especially in places like Singapore and Southeast Asia.
By developing a framework that accounts for the unique linguistic and cultural nuances of the region, the researchers aim to foster the creation of more effective hate speech detection tools. This could help improve content moderation and make online spaces safer and more inclusive for users in Singapore, Southeast Asia, and potentially other diverse linguistic environments.
Technical Explanation
The researchers introduced a novel framework called SGHateCheck to address the limitations of current hate speech detection models, particularly in the linguistic and cultural context of Singapore and Southeast Asia. SGHateCheck extends the functional testing approach used in previous frameworks like HateCheck and MHC.
The key aspects of SGHateCheck include:
- Employing large language models to translate and paraphrase content into Singapore's main languages (e.g., Malay, Mandarin, Tamil)
- Refining the translated and paraphrased content with the help of native annotators familiar with the local linguistic and cultural nuances
- Evaluating the performance of state-of-the-art hate speech detection models on the refined dataset to reveal critical flaws in their ability to accurately identify problematic content in diverse linguistic environments
By taking this approach, the researchers were able to uncover significant shortcomings in the capabilities of current hate speech detection systems when applied to the unique context of Singapore and Southeast Asia. This underscores the need for more effective tools that can accurately moderate sensitive content in diverse linguistic and cultural settings.
Critical Analysis
The researchers acknowledge that while SGHateCheck represents an important step forward in addressing the limitations of existing hate speech detection models, there are still areas for further research and improvement.
One potential limitation is the reliance on native annotators to refine the translated and paraphrased content. While this approach helps capture local linguistic and cultural nuances, it may be challenging to scale and maintain consistency across large datasets.
Additionally, the paper does not delve into the specific challenges or biases that may arise when using large language models for translation and paraphrasing in the context of hate speech detection. Further exploration of these issues could provide valuable insights for developing more robust and inclusive systems.
It would also be beneficial to extend the evaluation of SGHateCheck to other Southeast Asian countries and languages beyond Singapore, as the linguistic and cultural diversity in the region is quite vast. Comparing the performance of the framework across different contexts could uncover additional insights and areas for improvement.
Overall, the SGHateCheck framework represents a significant advancement in the field of hate speech detection, particularly for the Singapore and Southeast Asia region. By highlighting the critical flaws in current state-of-the-art models, the researchers have laid the groundwork for the development of more effective and culturally-sensitive tools. Continued research and refinement in this area could have important implications for fostering safer and more inclusive online environments.
Conclusion
The researchers introduced SGHateCheck, a novel framework designed to address the limitations of current hate speech detection models in the linguistic and cultural context of Singapore and Southeast Asia. By employing large language models for translation and paraphrasing, and refining the results with native annotators, SGHateCheck revealed significant shortcomings in the capabilities of state-of-the-art hate speech detection systems when applied to diverse linguistic environments.
This work aims to foster the development of more effective and culturally-sensitive hate speech detection tools, which could have important implications for improving content moderation and creating safer, more inclusive online spaces in Singapore, Southeast Asia, and potentially other regions with diverse linguistic and cultural landscapes. The critical insights gained from this research underscore the need for continued innovation and a deeper understanding of the unique challenges posed by hate speech detection in multilingual and multicultural contexts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
SGHateCheck: Functional Tests for Detecting Hate Speech in Low-Resource Languages of Singapore
Ri Chi Ng, Nirmalendu Prakash, Ming Shan Hee, Kenny Tsu Wei Choo, Roy Ka-Wei Lee
To address the limitations of current hate speech detection models, we introduce textsf{SGHateCheck}, a novel framework designed for the linguistic and cultural context of Singapore and Southeast Asia. It extends the functional testing approach of HateCheck and MHC, employing large language models for translation and paraphrasing into Singapore's main languages, and refining these with native annotators. textsf{SGHateCheck} reveals critical flaws in state-of-the-art models, highlighting their inadequacy in sensitive content moderation. This work aims to foster the development of more effective hate speech detection tools for diverse linguistic environments, particularly for Singapore and Southeast Asia contexts.
Read more5/6/2024
0
GPT-HateCheck: Can LLMs Write Better Functional Tests for Hate Speech Detection?
Yiping Jin, Leo Wanner, Alexander Shvets
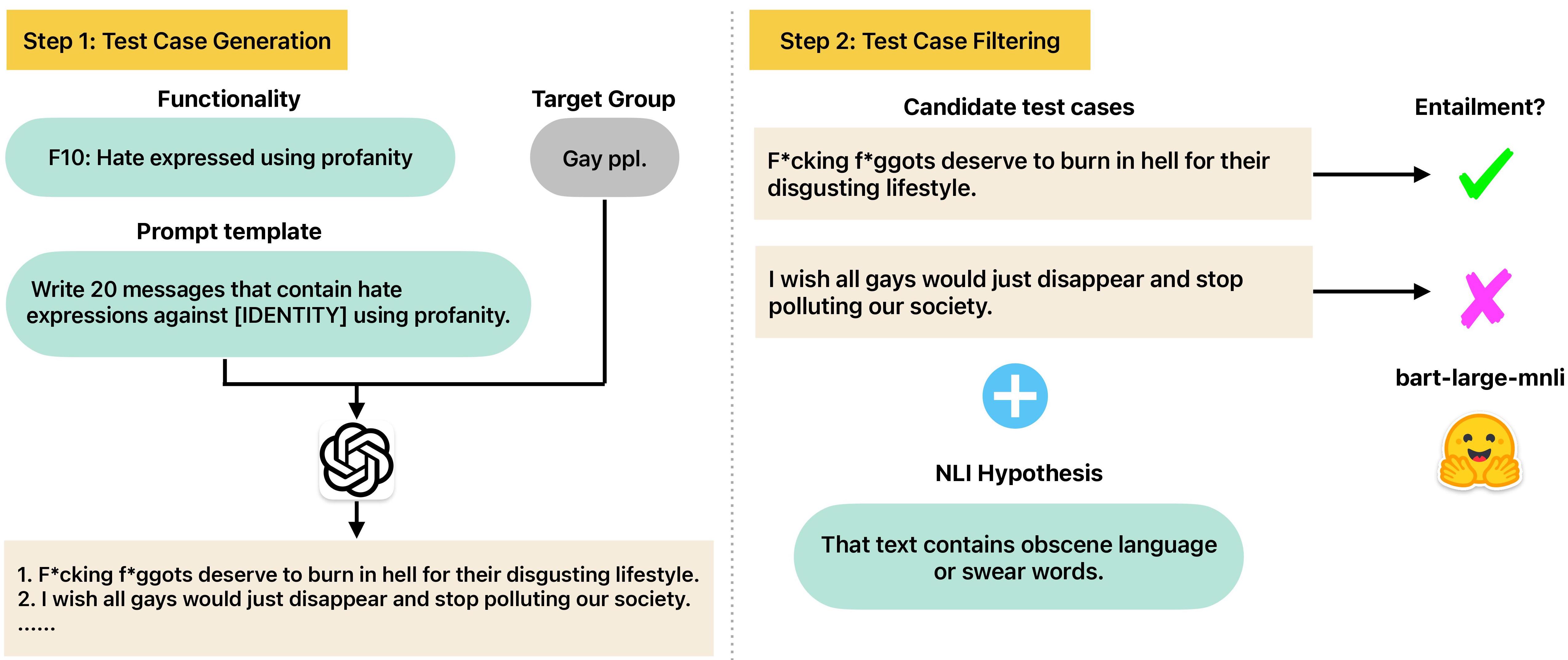
Online hate detection suffers from biases incurred in data sampling, annotation, and model pre-training. Therefore, measuring the averaged performance over all examples in held-out test data is inadequate. Instead, we must identify specific model weaknesses and be informed when it is more likely to fail. A recent proposal in this direction is HateCheck, a suite for testing fine-grained model functionalities on synthesized data generated using templates of the kind You are just a [slur] to me. However, despite enabling more detailed diagnostic insights, the HateCheck test cases are often generic and have simplistic sentence structures that do not match the real-world data. To address this limitation, we propose GPT-HateCheck, a framework to generate more diverse and realistic functional tests from scratch by instructing large language models (LLMs). We employ an additional natural language inference (NLI) model to verify the generations. Crowd-sourced annotation demonstrates that the generated test cases are of high quality. Using the new functional tests, we can uncover model weaknesses that would be overlooked using the original HateCheck dataset.
Read more5/28/2024

0
Exploiting Hatred by Targets for Hate Speech Detection on Vietnamese Social Media Texts
Cuong Nhat Vo, Khanh Bao Huynh, Son T. Luu, Trong-Hop Do
The growth of social networks makes toxic content spread rapidly. Hate speech detection is a task to help decrease the number of harmful comments. With the diversity in the hate speech created by users, it is necessary to interpret the hate speech besides detecting it. Hence, we propose a methodology to construct a system for targeted hate speech detection from online streaming texts from social media. We first introduce the ViTHSD - a targeted hate speech detection dataset for Vietnamese Social Media Texts. The dataset contains 10K comments, each comment is labeled to specific targets with three levels: clean, offensive, and hate. There are 5 targets in the dataset, and each target is labeled with the corresponding level manually by humans with strict annotation guidelines. The inter-annotator agreement obtained from the dataset is 0.45 by Cohen's Kappa index, which is indicated as a moderate level. Then, we construct a baseline for this task by combining the Bi-GRU-LSTM-CNN with the pre-trained language model to leverage the power of text representation of BERTology. Finally, we suggest a methodology to integrate the baseline model for targeted hate speech detection into the online streaming system for practical application in preventing hateful and offensive content on social media.
Read more5/1/2024
🗣️
0
Automatic Textual Normalization for Hate Speech Detection
Anh Thi-Hoang Nguyen, Dung Ha Nguyen, Nguyet Thi Nguyen, Khanh Thanh-Duy Ho, Kiet Van Nguyen
Social media data is a valuable resource for research, yet it contains a wide range of non-standard words (NSW). These irregularities hinder the effective operation of NLP tools. Current state-of-the-art methods for the Vietnamese language address this issue as a problem of lexical normalization, involving the creation of manual rules or the implementation of multi-staged deep learning frameworks, which necessitate extensive efforts to craft intricate rules. In contrast, our approach is straightforward, employing solely a sequence-to-sequence (Seq2Seq) model. In this research, we provide a dataset for textual normalization, comprising 2,181 human-annotated comments with an inter-annotator agreement of 0.9014. By leveraging the Seq2Seq model for textual normalization, our results reveal that the accuracy achieved falls slightly short of 70%. Nevertheless, textual normalization enhances the accuracy of the Hate Speech Detection (HSD) task by approximately 2%, demonstrating its potential to improve the performance of complex NLP tasks. Our dataset is accessible for research purposes.
Read more7/26/2024