GPT-HateCheck: Can LLMs Write Better Functional Tests for Hate Speech Detection?

0
Sign in to get full access
Overview
- This paper explores whether large language models (LLMs) like GPT can be used to generate better functional tests for hate speech detection models.
- The researchers develop a system called GPT-HateCheck that uses GPT to automatically generate diverse test cases for evaluating the performance of hate speech detection models.
- They compare the effectiveness of GPT-HateCheck against manually curated test sets and find that the GPT-generated tests are more challenging and better at exposing weaknesses in hate speech detectors.
Plain English Explanation
The paper addresses an important problem in the field of hate speech detection. Hate speech detection models are AI systems that try to automatically identify harmful or abusive language online. However, these models often struggle with more nuanced or ambiguous cases of hate speech.
The researchers behind this paper wondered if large language models like GPT could be used to help improve hate speech detection. They developed a system called GPT-HateCheck that uses GPT to automatically generate diverse test cases for evaluating the performance of hate speech detectors. These test cases cover a wide range of linguistic patterns and edge cases that the detectors may struggle with.
When they compared GPT-HateCheck to manually curated test sets, they found that the GPT-generated tests were more challenging and better at exposing weaknesses in the hate speech detection models. This suggests that AI-generated tests could be a powerful tool for building more robust and reliable hate speech detectors.
Overall, this research demonstrates the potential for large language models to assist in the development of more effective and interpretable hate speech detection systems. By automatically generating diverse and challenging test cases, GPT-HateCheck could help drive progress in this important area of AI safety and ethics.
Technical Explanation
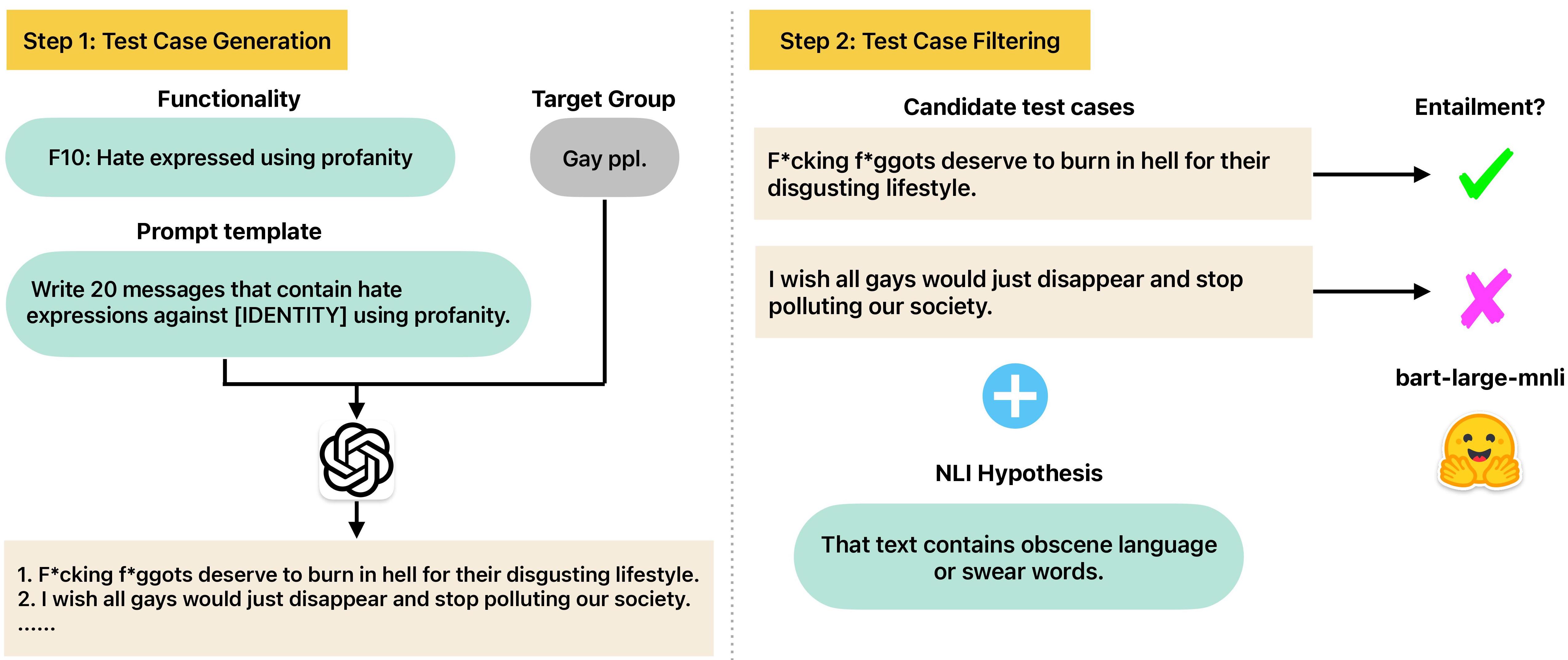
The paper presents GPT-HateCheck, a system that leverages the language generation capabilities of large language models (LLMs) like GPT to automatically produce diverse and challenging test cases for evaluating hate speech detection models.
The researchers first trained GPT on a large corpus of online comments, including both hateful and non-hateful text. They then used this pre-trained GPT model to generate new test cases, prompting it with templates that capture different linguistic patterns associated with hate speech (e.g., insults, stereotypes, implicit biases).
To evaluate the effectiveness of the GPT-generated test cases, the researchers compared them to manually curated test sets used in prior research on hate speech detection. They found that the GPT-HateCheck test cases were more challenging for existing hate speech detectors, exposing more weaknesses and inconsistencies in the models' performance.
Further analysis revealed that the GPT-generated test cases exhibited greater lexical and semantic diversity compared to the manual tests. The researchers also found that GPT-HateCheck was able to produce test cases that were more linguistically complex and incorporated more subtle forms of hate speech, which are often difficult for rule-based or dictionary-based detectors to identify.
Overall, the results suggest that leveraging the language generation capabilities of LLMs like GPT can be a effective strategy for developing more comprehensive and robust functional tests for hate speech detection models. This could lead to significant improvements in the reliability and safety of such systems.
Critical Analysis
The GPT-HateCheck research represents an important step forward in the development of more effective hate speech detection systems. By using an AI-powered approach to generate diverse and challenging test cases, the researchers have shown that LLMs can be a valuable tool for exposing the weaknesses of existing hate speech detectors.
However, the paper does acknowledge some limitations and areas for further research. For instance, the authors note that the GPT-generated test cases may not fully capture the nuances of real-world hate speech, which can often be highly context-dependent. There are also concerns about the potential for LLMs to perpetuate or amplify harmful biases, which could be reflected in the generated test cases.
Additionally, while the GPT-HateCheck system demonstrated strong performance in exposing model weaknesses, the paper does not provide a comprehensive evaluation of how well the generated test cases translate to improved real-world hate speech detection. Further research would be needed to fully understand the practical impact of this approach.
Overall, the GPT-HateCheck paper is a valuable contribution to the field of hate speech detection, showcasing the potential for LLMs to assist in the development of more robust and reliable systems. However, ongoing work is needed to address the limitations and ensure that these technologies are deployed safely and ethically.
Conclusion
The GPT-HateCheck paper presents an innovative approach to improving hate speech detection models by leveraging the language generation capabilities of large language models. By automatically producing diverse and challenging test cases, the researchers have shown that AI-powered techniques can be a valuable tool for exposing the weaknesses of existing hate speech detectors.
This research represents an important step forward in the ongoing effort to build more effective and trustworthy hate speech detection systems. By continuously improving the testing and evaluation of these critical AI systems, we can work towards more reliable and interpretable hate speech detection that can better protect vulnerable communities online. The insights from this paper can also inform the development of other AI safety and ethics applications that require comprehensive testing and evaluation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GPT-HateCheck: Can LLMs Write Better Functional Tests for Hate Speech Detection?
Yiping Jin, Leo Wanner, Alexander Shvets
Online hate detection suffers from biases incurred in data sampling, annotation, and model pre-training. Therefore, measuring the averaged performance over all examples in held-out test data is inadequate. Instead, we must identify specific model weaknesses and be informed when it is more likely to fail. A recent proposal in this direction is HateCheck, a suite for testing fine-grained model functionalities on synthesized data generated using templates of the kind You are just a [slur] to me. However, despite enabling more detailed diagnostic insights, the HateCheck test cases are often generic and have simplistic sentence structures that do not match the real-world data. To address this limitation, we propose GPT-HateCheck, a framework to generate more diverse and realistic functional tests from scratch by instructing large language models (LLMs). We employ an additional natural language inference (NLI) model to verify the generations. Crowd-sourced annotation demonstrates that the generated test cases are of high quality. Using the new functional tests, we can uncover model weaknesses that would be overlooked using the original HateCheck dataset.
Read more5/28/2024
🗣️
0
SGHateCheck: Functional Tests for Detecting Hate Speech in Low-Resource Languages of Singapore
Ri Chi Ng, Nirmalendu Prakash, Ming Shan Hee, Kenny Tsu Wei Choo, Roy Ka-Wei Lee
To address the limitations of current hate speech detection models, we introduce textsf{SGHateCheck}, a novel framework designed for the linguistic and cultural context of Singapore and Southeast Asia. It extends the functional testing approach of HateCheck and MHC, employing large language models for translation and paraphrasing into Singapore's main languages, and refining these with native annotators. textsf{SGHateCheck} reveals critical flaws in state-of-the-art models, highlighting their inadequacy in sensitive content moderation. This work aims to foster the development of more effective hate speech detection tools for diverse linguistic environments, particularly for Singapore and Southeast Asia contexts.
Read more5/6/2024

0
Investigating Annotator Bias in Large Language Models for Hate Speech Detection
Amit Das, Zheng Zhang, Fatemeh Jamshidi, Vinija Jain, Aman Chadha, Nilanjana Raychawdhary, Mary Sandage, Lauramarie Pope, Gerry Dozier, Cheryl Seals
Data annotation, the practice of assigning descriptive labels to raw data, is pivotal in optimizing the performance of machine learning models. However, it is a resource-intensive process susceptible to biases introduced by annotators. The emergence of sophisticated Large Language Models (LLMs), like ChatGPT presents a unique opportunity to modernize and streamline this complex procedure. While existing research extensively evaluates the efficacy of LLMs, as annotators, this paper delves into the biases present in LLMs, specifically GPT 3.5 and GPT 4o when annotating hate speech data. Our research contributes to understanding biases in four key categories: gender, race, religion, and disability. Specifically targeting highly vulnerable groups within these categories, we analyze annotator biases. Furthermore, we conduct a comprehensive examination of potential factors contributing to these biases by scrutinizing the annotated data. We introduce our custom hate speech detection dataset, HateSpeechCorpus, to conduct this research. Additionally, we perform the same experiments on the ETHOS (Mollas et al., 2022) dataset also for comparative analysis. This paper serves as a crucial resource, guiding researchers and practitioners in harnessing the potential of LLMs for dataannotation, thereby fostering advancements in this critical field. The HateSpeechCorpus dataset is available here: https://github.com/AmitDasRup123/HateSpeechCorpus
Read more6/19/2024
🗣️
0
HateTinyLLM : Hate Speech Detection Using Tiny Large Language Models
Tanmay Sen, Ansuman Das, Mrinmay Sen
Hate speech encompasses verbal, written, or behavioral communication that targets derogatory or discriminatory language against individuals or groups based on sensitive characteristics. Automated hate speech detection plays a crucial role in curbing its propagation, especially across social media platforms. Various methods, including recent advancements in deep learning, have been devised to address this challenge. In this study, we introduce HateTinyLLM, a novel framework based on fine-tuned decoder-only tiny large language models (tinyLLMs) for efficient hate speech detection. Our experimental findings demonstrate that the fine-tuned HateTinyLLM outperforms the pretrained mixtral-7b model by a significant margin. We explored various tiny LLMs, including PY007/TinyLlama-1.1B-step-50K-105b, Microsoft/phi-2, and facebook/opt-1.3b, and fine-tuned them using LoRA and adapter methods. Our observations indicate that all LoRA-based fine-tuned models achieved over 80% accuracy.
Read more5/6/2024