Shaking Up VLMs: Comparing Transformers and Structured State Space Models for Vision & Language Modeling

0

Sign in to get full access
Overview
- Compares transformers and structured state space models for vision and language modeling
- Explores the capabilities and tradeoffs of these two approaches
- Provides insights into the strengths and limitations of each modeling strategy
Plain English Explanation
This paper examines two different approaches to building machine learning models for tasks like image recognition and language understanding: transformers and structured state space models.
Transformers have become very popular in recent years, but structured state space models offer an alternative that may have some advantages. The researchers in this paper wanted to better understand the relative merits of these two modeling techniques.
They conducted experiments to see how well transformers and state space models perform on various vision and language tasks. The goal was to identify the strengths and weaknesses of each approach, and provide insights that can help researchers and developers choose the right tool for their particular needs.
Technical Explanation
The paper begins by providing background on transformers and structured state space models, explaining the key differences in their architectural design and underlying mathematical formulations.
The researchers then describe a series of experiments comparing the two approaches on several benchmark tasks, including image classification, language modeling, and vision-language tasks like image captioning. They evaluate metrics like accuracy, efficiency, and sample complexity to gain a comprehensive understanding of the tradeoffs.
The results show that while transformers generally achieve higher raw performance, structured state space models can offer advantages in terms of sample efficiency, interpretability, and computational cost. The paper discusses how the inductive biases built into the state space models may be beneficial for certain types of problems.
Additionally, the researchers explore hybrid models that combine aspects of transformers and state space models, finding that these can sometimes outperform either approach in isolation.
Critical Analysis
The paper provides a thorough and rigorous comparison of transformers and state space models, with a diverse set of experiments covering a range of tasks and metrics. The authors are careful to acknowledge limitations and avenues for future work.
One potential weakness is that the experiments are conducted on somewhat narrow benchmarks, and it's unclear how the results would generalize to real-world, large-scale applications. Further testing on more complex, open-ended tasks would help validate the insights.
Additionally, the paper does not delve deeply into the theoretical underpinnings that could explain the observed performance differences. A more detailed analysis of the inductive biases and architectural advantages/disadvantages of each approach could strengthen the paper's contributions.
Overall, this work provides a valuable contribution to the ongoing debate around the appropriate role of transformers versus structured models in machine learning. The insights can help guide model selection and motivate further research into hybrid architectures.
Conclusion
This paper offers a comprehensive comparison of transformers and structured state space models for vision and language tasks. The results suggest that while transformers generally achieve higher raw performance, state space models can provide advantages in terms of sample efficiency, interpretability, and computational cost.
These findings have important implications for the development of next-generation AI systems, as researchers and engineers must carefully weigh the tradeoffs between different modeling approaches to select the most appropriate tools for their specific applications. The insights from this paper can help inform these decisions and inspire further innovation in machine learning architectures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Shaking Up VLMs: Comparing Transformers and Structured State Space Models for Vision & Language Modeling
Georgios Pantazopoulos, Malvina Nikandrou, Alessandro Suglia, Oliver Lemon, Arash Eshghi
This study explores replacing Transformers in Visual Language Models (VLMs) with Mamba, a recent structured state space model (SSM) that demonstrates promising performance in sequence modeling. We test models up to 3B parameters under controlled conditions, showing that Mamba-based VLMs outperforms Transformers-based VLMs in captioning, question answering, and reading comprehension. However, we find that Transformers achieve greater performance in visual grounding and the performance gap widens with scale. We explore two hypotheses to explain this phenomenon: 1) the effect of task-agnostic visual encoding on the updates of the hidden states, and 2) the difficulty in performing visual grounding from the perspective of in-context multimodal retrieval. Our results indicate that a task-aware encoding yields minimal performance gains on grounding, however, Transformers significantly outperform Mamba at in-context multimodal retrieval. Overall, Mamba shows promising performance on tasks where the correct output relies on a summary of the image but struggles when retrieval of explicit information from the context is required.
Read more9/10/2024
30
An Empirical Study of Mamba-based Language Models
Roger Waleffe, Wonmin Byeon, Duncan Riach, Brandon Norick, Vijay Korthikanti, Tri Dao, Albert Gu, Ali Hatamizadeh, Sudhakar Singh, Deepak Narayanan, Garvit Kulshreshtha, Vartika Singh, Jared Casper, Jan Kautz, Mohammad Shoeybi, Bryan Catanzaro
Selective state-space models (SSMs) like Mamba overcome some of the shortcomings of Transformers, such as quadratic computational complexity with sequence length and large inference-time memory requirements from the key-value cache. Moreover, recent studies have shown that SSMs can match or exceed the language modeling capabilities of Transformers, making them an attractive alternative. In a controlled setting (e.g., same data), however, studies so far have only presented small scale experiments comparing SSMs to Transformers. To understand the strengths and weaknesses of these architectures at larger scales, we present a direct comparison between 8B-parameter Mamba, Mamba-2, and Transformer models trained on the same datasets of up to 3.5T tokens. We also compare these models to a hybrid architecture consisting of 43% Mamba-2, 7% attention, and 50% MLP layers (Mamba-2-Hybrid). Using a diverse set of tasks, we answer the question of whether Mamba models can match Transformers at larger training budgets. Our results show that while pure SSMs match or exceed Transformers on many tasks, they lag behind Transformers on tasks which require strong copying or in-context learning abilities (e.g., 5-shot MMLU, Phonebook) or long-context reasoning. In contrast, we find that the 8B Mamba-2-Hybrid exceeds the 8B Transformer on all 12 standard tasks we evaluated (+2.65 points on average) and is predicted to be up to 8x faster when generating tokens at inference time. To validate long-context capabilities, we provide additional experiments evaluating variants of the Mamba-2-Hybrid and Transformer extended to support 16K, 32K, and 128K sequences. On an additional 23 long-context tasks, the hybrid model continues to closely match or exceed the Transformer on average. To enable further study, we release the checkpoints as well as the code used to train our models as part of NVIDIA's Megatron-LM project.
Read more6/13/2024
🧠
1
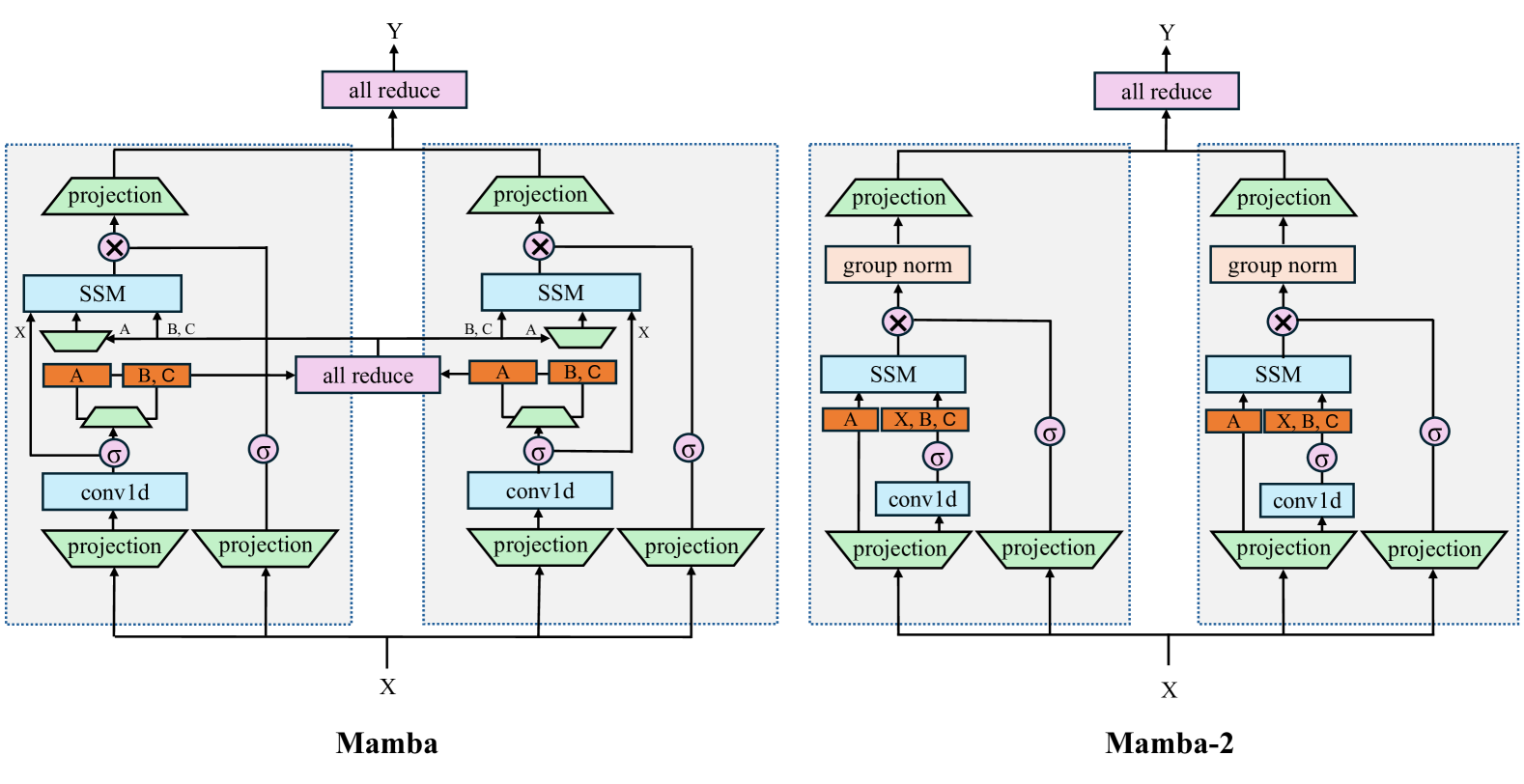
Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality
Tri Dao, Albert Gu
While Transformers have been the main architecture behind deep learning's success in language modeling, state-space models (SSMs) such as Mamba have recently been shown to match or outperform Transformers at small to medium scale. We show that these families of models are actually quite closely related, and develop a rich framework of theoretical connections between SSMs and variants of attention, connected through various decompositions of a well-studied class of structured semiseparable matrices. Our state space duality (SSD) framework allows us to design a new architecture (Mamba-2) whose core layer is an a refinement of Mamba's selective SSM that is 2-8X faster, while continuing to be competitive with Transformers on language modeling.
Read more6/3/2024

0
New!Mamba Fusion: Learning Actions Through Questioning
Zhikang Dong, Apoorva Beedu, Jason Sheinkopf, Irfan Essa
Video Language Models (VLMs) are crucial for generalizing across diverse tasks and using language cues to enhance learning. While transformer-based architectures have been the de facto in vision-language training, they face challenges like quadratic computational complexity, high GPU memory usage, and difficulty with long-term dependencies. To address these limitations, we introduce MambaVL, a novel model that leverages recent advancements in selective state space modality fusion to efficiently capture long-range dependencies and learn joint representations for vision and language data. MambaVL utilizes a shared state transition matrix across both modalities, allowing the model to capture information about actions from multiple perspectives within the scene. Furthermore, we propose a question-answering task that helps guide the model toward relevant cues. These questions provide critical information about actions, objects, and environmental context, leading to enhanced performance. As a result, MambaVL achieves state-of-the-art performance in action recognition on the Epic-Kitchens-100 dataset and outperforms baseline methods in action anticipation.
Read more9/19/2024