Share Your Secrets for Privacy! Confidential Forecasting with Vertical Federated Learning

0

Sign in to get full access
Background
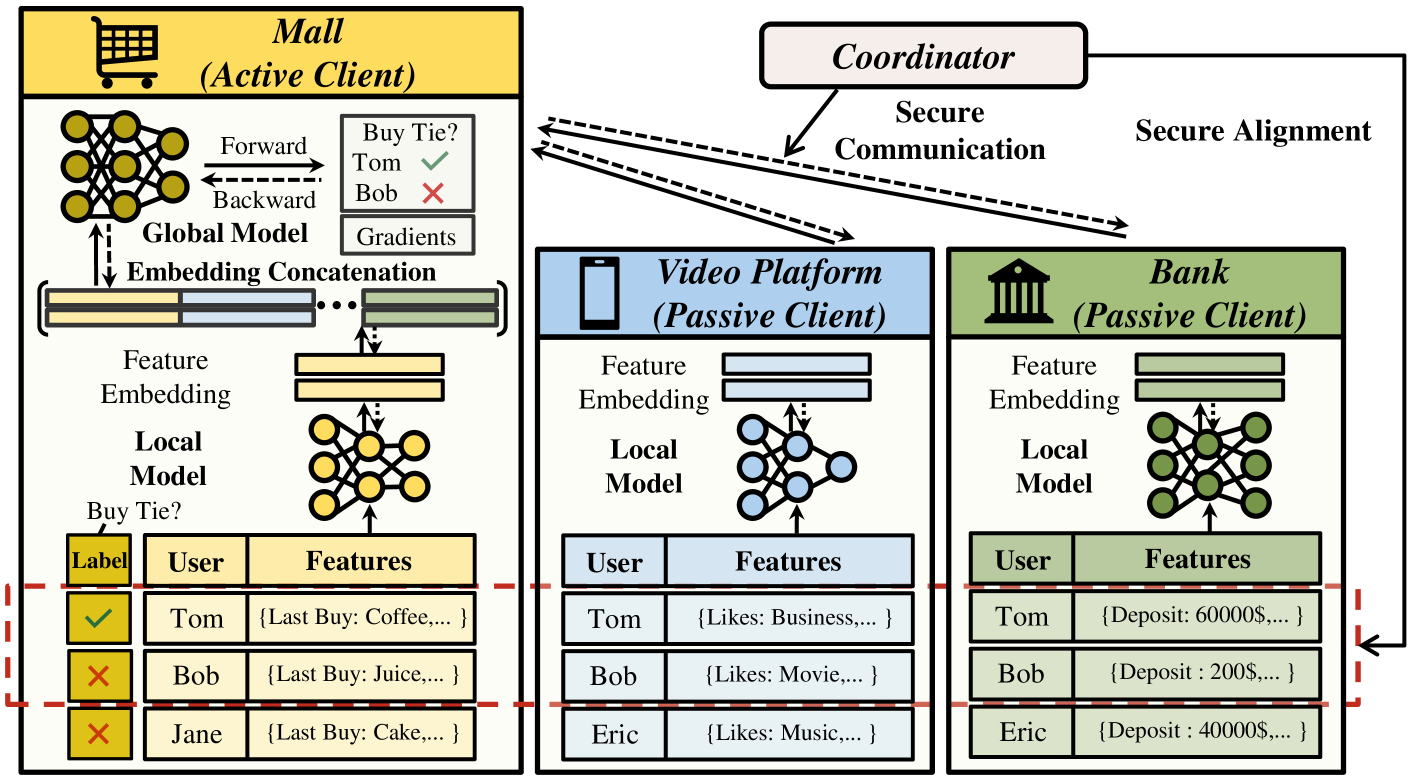
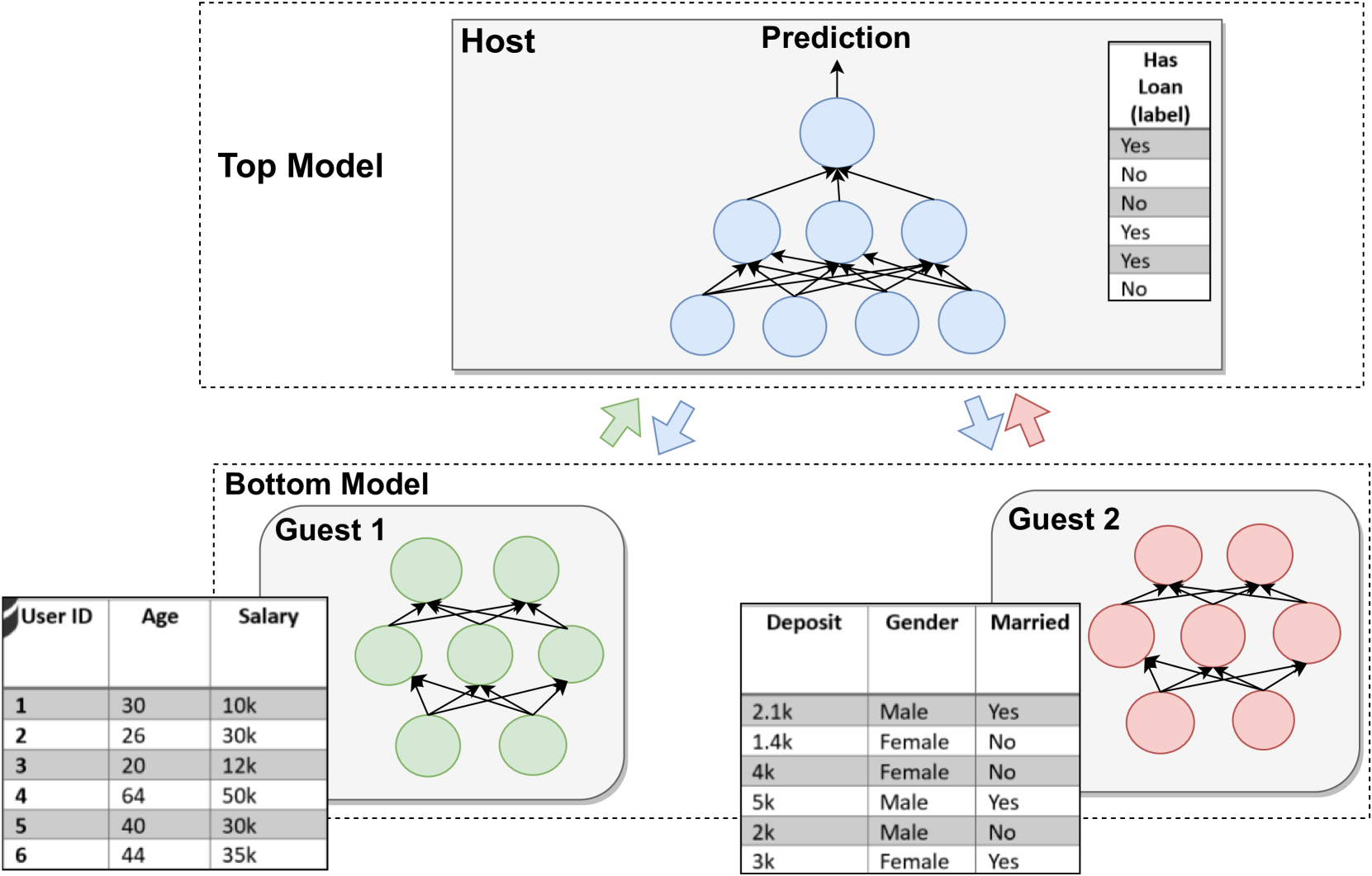
Vertical Federated Learning
Vertical Federated Learning is a machine learning technique that allows multiple organizations to train a shared model without directly sharing their data. In this approach, each organization contributes features or attributes about the same set of data samples, but the full data samples are not shared between them.
This is in contrast to the more common Horizontal Federated Learning, where the organizations have different data samples but the same feature set. Vertical Federated Learning enables collaboration and model building across organizations with complementary data, while preserving the privacy of sensitive information.
Challenges in Vertical Federated Learning
Implementing Vertical Federated Learning effectively poses several challenges:
- Latent Representation Learning: Effectively combining the different feature sets from the organizations into a unified representation for the shared model can be difficult.
- Privacy Preservation: Ensuring the privacy of the sensitive data contributed by each organization is critical, as there are risks of data leakage or reconstruction.
- Scalability: As the number of participating organizations increases, the complexity and communication overhead of the Vertical Federated Learning process grows, requiring scalable approaches.
Researchers have proposed various techniques to address these challenges, including data augmentation, hybrid local pre-training, and privacy-preserving mechanisms.
Plain English Explanation
Vertical Federated Learning is a way for different organizations to work together on a machine learning model without fully sharing their private data. In this approach, each organization contributes specific features or attributes about the same set of data samples, rather than sharing the entire data.
This is different from the more common Horizontal Federated Learning, where the organizations have different data samples but the same set of features.
Vertical Federated Learning allows organizations with complementary data to collaborate and build a shared model, while still protecting the privacy of their sensitive information. However, implementing this effectively presents several challenges:
- Latent Representation Learning: Combining the different feature sets from the organizations into a unified representation for the shared model can be difficult.
- Privacy Preservation: Ensuring the privacy of the sensitive data contributed by each organization is critical, as there are risks of data leakage or reconstruction.
- Scalability: As more organizations participate, the complexity and communication overhead of the Vertical Federated Learning process increases, requiring scalable approaches.
Researchers have developed various techniques to address these challenges, such as data augmentation, hybrid local pre-training, and privacy-preserving mechanisms. These advancements aim to make Vertical Federated Learning more practical and effective for real-world applications.
Technical Explanation
The paper proposes a confidential forecasting framework using Vertical Federated Learning. The key elements of the framework include:
-
Vertical Federated Learning Architecture: The framework involves multiple organizations, each contributing a subset of features about the same set of data samples. A shared model is trained in a federated manner, without directly sharing the raw data.
-
Latent Representation Learning: The framework leverages a hybrid local pre-training approach to learn a unified latent representation from the heterogeneous feature sets provided by the organizations.
-
Privacy-Preserving Mechanisms: The framework incorporates privacy-preserving techniques, such as differential privacy and secure multi-party computation, to protect the sensitive data contributed by the organizations.
-
Scalable Implementation: The framework addresses the scalability challenge by leveraging data augmentation techniques to increase the effective sample size and reduce the communication overhead during the Vertical Federated Learning process.
The paper evaluates the proposed framework on real-world datasets and demonstrates its effectiveness in terms of prediction accuracy, privacy preservation, and scalability, compared to alternative approaches.
Critical Analysis
The paper presents a comprehensive framework for confidential forecasting using Vertical Federated Learning, addressing several key challenges in this domain. The authors have drawn upon relevant prior work and incorporated state-of-the-art techniques to tackle issues such as latent representation learning, privacy preservation, and scalability.
One potential limitation of the research is the reliance on specific assumptions and constraints, such as the availability of certain types of auxiliary data or the ability to perform secure multi-party computation. In real-world scenarios, these assumptions may not always hold, and the framework may require further adaptations to be widely applicable.
Additionally, the paper does not provide a detailed analysis of the computational and communication overhead associated with the proposed approach, which could be an important consideration for practical deployments, especially as the number of participating organizations increases.
Further research could explore the robustness of the framework to various types of data distributions, feature correlations, and potential adversarial attacks. Additionally, investigating the practical implications and barriers to adoption in different industry sectors could provide valuable insights for future improvements and deployments.
Conclusion
The paper presents a confidential forecasting framework that leverages Vertical Federated Learning to enable multiple organizations to collaborate on a shared model without directly sharing their sensitive data. The framework addresses key challenges in Vertical Federated Learning, such as latent representation learning, privacy preservation, and scalability, through the use of advanced techniques like hybrid local pre-training, differential privacy, and data augmentation.
The evaluation results demonstrate the effectiveness of the proposed approach in terms of prediction accuracy, privacy preservation, and scalability, making it a promising solution for real-world applications that require collaborative machine learning while maintaining data confidentiality. As Vertical Federated Learning continues to evolve, this research contributes to the growing body of work that explores the potential of this paradigm to unlock new opportunities for privacy-preserving data sharing and model development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Share Your Secrets for Privacy! Confidential Forecasting with Vertical Federated Learning
Aditya Shankar, Lydia Y. Chen, J'er'emie Decouchant, Dimitra Gkorou, Rihan Hai
Vertical federated learning (VFL) is a promising area for time series forecasting in industrial applications, such as predictive maintenance and machine control. Critical challenges to address in manufacturing include data privacy and over-fitting on small and noisy datasets during both training and inference. Additionally, to increase industry adaptability, such forecasting models must scale well with the number of parties while ensuring strong convergence and low-tuning complexity. We address those challenges and propose 'Secret-shared Time Series Forecasting with VFL' (STV), a novel framework that exhibits the following key features: i) a privacy-preserving algorithm for forecasting with SARIMAX and autoregressive trees on vertically partitioned data; ii) serverless forecasting using secret sharing and multi-party computation; iii) novel N-party algorithms for matrix multiplication and inverse operations for direct parameter optimization, giving strong convergence with minimal hyperparameter tuning complexity. We conduct evaluations on six representative datasets from public and industry-specific contexts. Our results demonstrate that STV's forecasting accuracy is comparable to those of centralized approaches. They also show that our direct optimization can outperform centralized methods, which include state-of-the-art diffusion models and long-short-term memory, by 23.81% on forecasting accuracy. We also conduct a scalability analysis by examining the communication costs of direct and iterative optimization to navigate the choice between the two. Code and appendix are available: https://github.com/adis98/STV
Read more6/3/2024
📊
0
Scalable Vertical Federated Learning via Data Augmentation and Amortized Inference
Conor Hassan, Matthew Sutton, Antonietta Mira, Kerrie Mengersen
Vertical federated learning (VFL) has emerged as a paradigm for collaborative model estimation across multiple clients, each holding a distinct set of covariates. This paper introduces the first comprehensive framework for fitting Bayesian models in the VFL setting. We propose a novel approach that leverages data augmentation techniques to transform VFL problems into a form compatible with existing Bayesian federated learning algorithms. We present an innovative model formulation for specific VFL scenarios where the joint likelihood factorizes into a product of client-specific likelihoods. To mitigate the dimensionality challenge posed by data augmentation, which scales with the number of observations and clients, we develop a factorized amortized variational approximation that achieves scalability independent of the number of observations. We showcase the efficacy of our framework through extensive numerical experiments on logistic regression, multilevel regression, and a novel hierarchical Bayesian split neural net model. Our work paves the way for privacy-preserving, decentralized Bayesian inference in vertically partitioned data scenarios, opening up new avenues for research and applications in various domains.
Read more5/8/2024
0
Vertical Federated Learning for Effectiveness, Security, Applicability: A Survey
Mang Ye, Wei Shen, Bo Du, Eduard Snezhko, Vassili Kovalev, Pong C. Yuen
Vertical Federated Learning (VFL) is a privacy-preserving distributed learning paradigm where different parties collaboratively learn models using partitioned features of shared samples, without leaking private data. Recent research has shown promising results addressing various challenges in VFL, highlighting its potential for practical applications in cross-domain collaboration. However, the corresponding research is scattered and lacks organization. To advance VFL research, this survey offers a systematic overview of recent developments. First, we provide a history and background introduction, along with a summary of the general training protocol of VFL. We then revisit the taxonomy in recent reviews and analyze limitations in-depth. For a comprehensive and structured discussion, we synthesize recent research from three fundamental perspectives: effectiveness, security, and applicability. Finally, we discuss several critical future research directions in VFL, which will facilitate the developments in this field. We provide a collection of research lists and periodically update them at https://github.com/shentt67/VFL_Survey.
Read more6/5/2024
0
TabVFL: Improving Latent Representation in Vertical Federated Learning
Mohamed Rashad, Zilong Zhao, Jeremie Decouchant, Lydia Y. Chen
Autoencoders are popular neural networks that are able to compress high dimensional data to extract relevant latent information. TabNet is a state-of-the-art neural network model designed for tabular data that utilizes an autoencoder architecture for training. Vertical Federated Learning (VFL) is an emerging distributed machine learning paradigm that allows multiple parties to train a model collaboratively on vertically partitioned data while maintaining data privacy. The existing design of training autoencoders in VFL is to train a separate autoencoder in each participant and aggregate the latent representation later. This design could potentially break important correlations between feature data of participating parties, as each autoencoder is trained on locally available features while disregarding the features of others. In addition, traditional autoencoders are not specifically designed for tabular data, which is ubiquitous in VFL settings. Moreover, the impact of client failures during training on the model robustness is under-researched in the VFL scene. In this paper, we propose TabVFL, a distributed framework designed to improve latent representation learning using the joint features of participants. The framework (i) preserves privacy by mitigating potential data leakage with the addition of a fully-connected layer, (ii) conserves feature correlations by learning one latent representation vector, and (iii) provides enhanced robustness against client failures during training phase. Extensive experiments on five classification datasets show that TabVFL can outperform the prior work design, with 26.12% of improvement on f1-score.
Read more4/30/2024