Sharif-MGTD at SemEval-2024 Task 8: A Transformer-Based Approach to Detect Machine Generated Text

0

Sign in to get full access
Overview
- This paper describes a transformer-based approach developed by the Sharif-MGTD team for the SemEval-2024 Task 8, which focuses on detecting machine-generated text.
- The team leveraged the capabilities of transformer models, like BERT and GPT, to build a robust system for identifying whether a given text was produced by a human or a machine.
- The paper outlines the team's methodology, experiments, and key findings, providing insights into the performance and potential of their approach.
Plain English Explanation
The Sharif-MGTD team developed a machine learning system that can detect whether a piece of text was written by a human or generated by a computer. They used a type of AI model called a "transformer," which is good at understanding the context and meaning of language. The team trained their system on a large dataset of human-written and machine-generated text, so it could learn the patterns and differences between the two.
When given a new piece of text, their system can analyze it and determine whether it was likely written by a person or produced by a computer program. This is an important task, as there is a growing concern about the increasing use of AI systems to generate realistic-looking text, which could be used to spread misinformation or impersonate real people.
The team's approach was evaluated as part of the SemEval-2024 Task 8 competition, which focused on machine-generated text detection. Their results showed that their transformer-based system performed well, with strong accuracy in identifying both human-written and machine-generated text. This suggests that their approach could be a valuable tool for fighting the spread of AI-generated content and maintaining the integrity of online information.
Technical Explanation
The Sharif-MGTD team's approach to detecting machine-generated text (MGT) is based on the use of transformer-based models. Transformer models, such as BERT and GPT, have shown impressive performance in a wide range of natural language processing tasks, including text generation and classification. The team leveraged the capabilities of these models to build a robust system for identifying whether a given text was produced by a human or a machine.
The team's system takes a piece of text as input and feeds it into a transformer-based model, which generates a set of hidden representations that capture the semantic and syntactic features of the text. These representations are then passed through additional neural network layers to produce a binary classification output, indicating whether the text is human-written or machine-generated.
The team experimented with different transformer-based architectures and fine-tuning strategies to optimize the performance of their system. They evaluated their approach as part of the SemEval-2024 Task 8 competition, which provides a standardized benchmark for evaluating MGT detection systems. The results of their experiments demonstrate the effectiveness of their transformer-based approach, with the system achieving strong accuracy in identifying both human-written and machine-generated text.
Critical Analysis
The Sharif-MGTD team's paper provides a valuable contribution to the field of machine-generated text detection, showcasing the potential of transformer-based models for this task. However, the paper also highlights some limitations and areas for further research.
One potential limitation is the reliance on a specific benchmark dataset (SemEval-2024 Task 8) for evaluation. While this provides a standardized testing environment, it is important to assess the system's performance on a wider range of datasets and real-world scenarios to ensure its robustness and generalizability.
Additionally, the paper does not provide much insight into the interpretability and explainability of the team's system. As transformer-based models can be complex and difficult to interpret, it would be valuable to understand the specific features and patterns the system uses to distinguish human-written and machine-generated text.
Future research could also explore the potential of combining the team's transformer-based approach with other techniques, such as stylometric analysis or hybrid models, to further improve the detection of machine-generated text. This could lead to even more accurate and robust systems for addressing the growing challenge of AI-generated content.
Conclusion
The Sharif-MGTD team's transformer-based approach to detecting machine-generated text represents an important step forward in this critical area of research. By leveraging the capabilities of transformer models, the team has developed a system that demonstrates strong performance in identifying both human-written and machine-generated text.
These findings have significant implications for combating the spread of misinformation and maintaining the integrity of online information, as the increasing use of AI-generated content poses a significant threat to the credibility and trustworthiness of digital communication. The Sharif-MGTD team's work provides a valuable foundation for further research and development in this field, with the potential to contribute to the development of more robust and effective tools for detecting and mitigating the impact of machine-generated text.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Sharif-MGTD at SemEval-2024 Task 8: A Transformer-Based Approach to Detect Machine Generated Text
Seyedeh Fatemeh Ebrahimi, Karim Akhavan Azari, Amirmasoud Iravani, Arian Qazvini, Pouya Sadeghi, Zeinab Sadat Taghavi, Hossein Sameti
Detecting Machine-Generated Text (MGT) has emerged as a significant area of study within Natural Language Processing. While language models generate text, they often leave discernible traces, which can be scrutinized using either traditional feature-based methods or more advanced neural language models. In this research, we explore the effectiveness of fine-tuning a RoBERTa-base transformer, a powerful neural architecture, to address MGT detection as a binary classification task. Focusing specifically on Subtask A (Monolingual-English) within the SemEval-2024 competition framework, our proposed system achieves an accuracy of 78.9% on the test dataset, positioning us at 57th among participants. Our study addresses this challenge while considering the limited hardware resources, resulting in a system that excels at identifying human-written texts but encounters challenges in accurately discerning MGTs.
Read more7/17/2024
0
PetKaz at SemEval-2024 Task 8: Can Linguistics Capture the Specifics of LLM-generated Text?
Kseniia Petukhova, Roman Kazakov, Ekaterina Kochmar
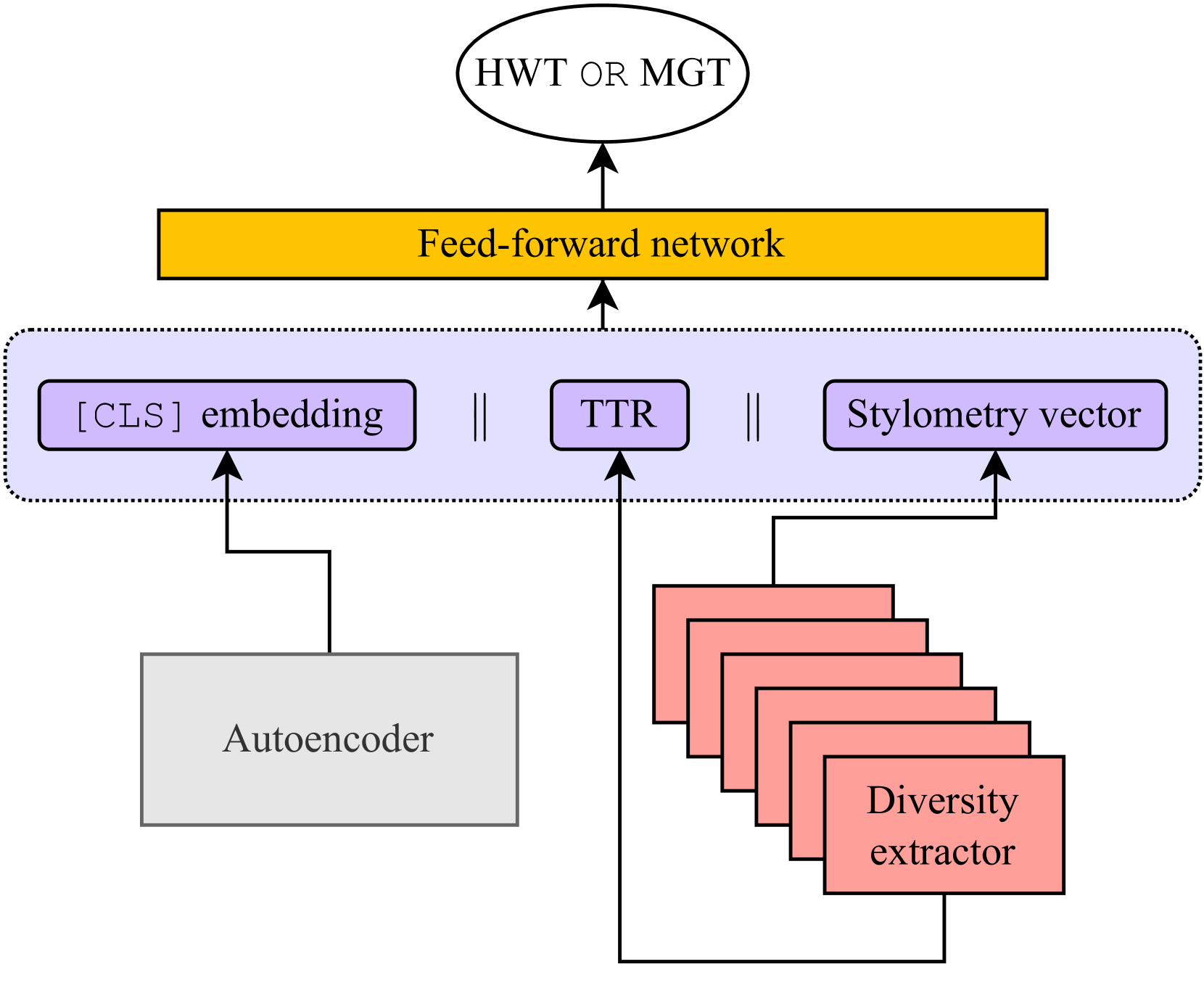
In this paper, we present our submission to the SemEval-2024 Task 8 Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection, focusing on the detection of machine-generated texts (MGTs) in English. Specifically, our approach relies on combining embeddings from the RoBERTa-base with diversity features and uses a resampled training set. We score 12th from 124 in the ranking for Subtask A (monolingual track), and our results show that our approach is generalizable across unseen models and domains, achieving an accuracy of 0.91.
Read more4/9/2024
0
MasonTigers at SemEval-2024 Task 8: Performance Analysis of Transformer-based Models on Machine-Generated Text Detection
Sadiya Sayara Chowdhury Puspo, Md Nishat Raihan, Dhiman Goswami, Al Nahian Bin Emran, Amrita Ganguly, Ozlem Uzuner
This paper presents the MasonTigers entry to the SemEval-2024 Task 8 - Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection. The task encompasses Binary Human-Written vs. Machine-Generated Text Classification (Track A), Multi-Way Machine-Generated Text Classification (Track B), and Human-Machine Mixed Text Detection (Track C). Our best performing approaches utilize mainly the ensemble of discriminator transformer models along with sentence transformer and statistical machine learning approaches in specific cases. Moreover, zero-shot prompting and fine-tuning of FLAN-T5 are used for Track A and B.
Read more4/8/2024

0
Transformer and Hybrid Deep Learning Based Models for Machine-Generated Text Detection
Teodor-George Marchitan, Claudiu Creanga, Liviu P. Dinu
This paper describes the approach of the UniBuc - NLP team in tackling the SemEval 2024 Task 8: Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection. We explored transformer-based and hybrid deep learning architectures. For subtask B, our transformer-based model achieved a strong textbf{second-place} out of $77$ teams with an accuracy of textbf{86.95%}, demonstrating the architecture's suitability for this task. However, our models showed overfitting in subtask A which could potentially be fixed with less fine-tunning and increasing maximum sequence length. For subtask C (token-level classification), our hybrid model overfit during training, hindering its ability to detect transitions between human and machine-generated text.
Read more5/29/2024