Aggregation of expert advice, revisited

0
🔄
Sign in to get full access
Overview
- This paper revisits the problem of aggregating expert advice, building on previous research.
- The authors propose a new technique for combining the predictions of multiple experts to improve overall accuracy.
- Key topics covered include definitions, background, a technical explanation of the proposed method, critical analysis, and potential implications.
Plain English Explanation
The paper examines the challenge of combining the opinions of multiple experts to make the best overall decision. This is an important problem in many fields, like healthcare, finance, and policymaking, where experts may have different views.
The authors introduce a new technique for aggregating expert advice that aims to improve the final prediction accuracy. Their approach builds on previous research in this area.
The key idea is to find the optimal way to weigh each expert's opinion, taking into account factors like their past performance and the diversity of the group. This is done through a mathematical optimization process.
The technical details of the proposed method are quite complex, involving advanced statistical and computational concepts. But the core goal is to combine expert judgments in a principled way to arrive at the most accurate final prediction.
The authors also critically analyze some potential limitations of their approach and suggest areas for further research. For example, the method may be sensitive to the quality and diversity of the experts involved.
Overall, this work advances our understanding of how to best leverage expert knowledge to make important decisions. While the technical details are intricate, the fundamental aim is to improve decision-making in high-stakes domains by combining diverse perspectives in a systematic way.
Technical Explanation
The paper introduces a new technique for aggregating expert advice to improve the overall accuracy of predictions or decisions.
The key idea is to find an optimal way to weigh each expert's opinion, taking into account factors like their past performance and the diversity of the group. This is formulated as a mathematical optimization problem, where the goal is to minimize the expected error of the aggregated prediction.
The technical approach involves modeling the experts' predictions as random variables and deriving an expression for the aggregated prediction that minimizes the mean squared error. This requires making assumptions about the statistical properties of the experts' predictions and errors.
The authors prove theoretical guarantees on the performance of their aggregation method, showing that it can outperform simpler approaches like equal weighting. They also provide guidelines for tuning the hyperparameters of the algorithm.
The empirical evaluation on both synthetic and real-world datasets demonstrates the effectiveness of the proposed technique compared to alternative methods. The authors analyze the impact of factors like the number of experts, their individual accuracies, and the degree of diversity in the group.
Critical Analysis
The authors acknowledge several limitations of their approach that could be addressed in future research:
- The method relies on strong assumptions about the statistical properties of the experts' predictions and errors, which may not always hold in practice.
- The optimization process can be computationally expensive for large numbers of experts, limiting scalability.
- The performance of the aggregation method may be sensitive to the quality and diversity of the expert pool, which can be difficult to control in real-world settings.
Additionally, the paper does not explore the robustness of the technique to potential biases or manipulations by the experts. In high-stakes decision-making scenarios, it would be important to understand how the method might be affected by strategic behavior from the experts.
Overall, the proposed approach represents an interesting advancement in the field of expert advice aggregation. However, the authors' critical reflection on the limitations and potential extensions of their work suggests that there is still room for further research and refinement of the technique.
Conclusion
This paper revisits the problem of aggregating expert advice, proposing a new technique that aims to improve the overall accuracy of predictions or decisions. The key idea is to find an optimal way to weigh each expert's opinion, taking into account factors like their past performance and the diversity of the group.
The authors provide a detailed technical explanation of their approach, including theoretical guarantees and empirical evaluations. They also critically analyze the limitations of their method and suggest areas for future research.
While the technical details are complex, the fundamental goal of the work is to enhance decision-making in high-stakes domains by systematically combining diverse expert perspectives. The proposed approach represents an interesting advancement in this important area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
Aggregation of expert advice, revisited
Aryeh Kontorovich
We revisit the classic problem of aggregating binary advice from conditionally independent experts, also known as the Naive Bayes setting. Our quantity of interest is the error probability of the optimal decision rule. In the case of symmetric errors (sensitivity = specificity), reasonably tight bounds on the optimal error probability are known. In the general asymmetric case, we are not aware of any nontrivial estimates on this quantity. Our contribution consists of sharp upper and lower bounds on the optimal error probability in the general case, which recover and sharpen the best known results in the symmetric special case. Since this turns out to be equivalent to estimating the total variation distance between two product distributions, our results also have bearing on this important and challenging problem.
Read more9/17/2024

0
A naive aggregation algorithm for improving generalization in a class of learning problems
Getachew K Befekadu
In this brief paper, we present a naive aggregation algorithm for a typical learning problem with expert advice setting, in which the task of improving generalization, i.e., model validation, is embedded in the learning process as a sequential decision-making problem. In particular, we consider a class of learning problem of point estimations for modeling high-dimensional nonlinear functions, where a group of experts update their parameter estimates using the discrete-time version of gradient systems, with small additive noise term, guided by the corresponding subsample datasets obtained from the original dataset. Here, our main objective is to provide conditions under which such an algorithm will sequentially determine a set of mixing distribution strategies used for aggregating the experts' estimates that ultimately leading to an optimal parameter estimate, i.e., as a consensus solution for all experts, which is better than any individual expert's estimate in terms of improved generalization or learning performances. Finally, as part of this work, we present some numerical results for a typical case of nonlinear regression problem.
Read more9/9/2024
0
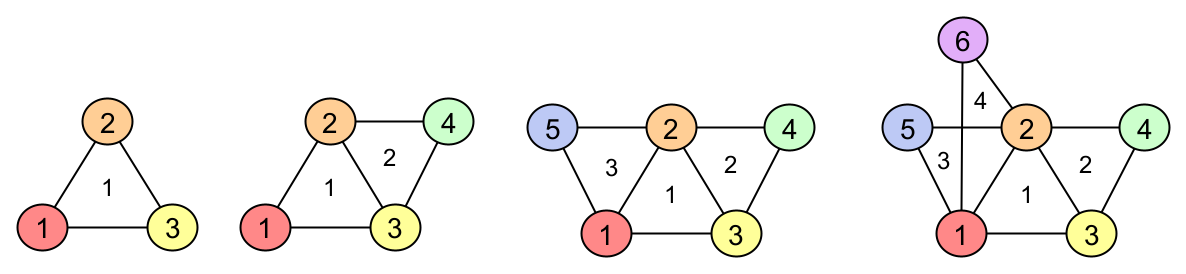
Generalized Naive Bayes
Edith Alice Kov'acs, Anna Orsz'ag, D'aniel Pfeifer, Andr'as Bencz'ur
In this paper we introduce the so-called Generalized Naive Bayes structure as an extension of the Naive Bayes structure. We give a new greedy algorithm that finds a good fitting Generalized Naive Bayes (GNB) probability distribution. We prove that this fits the data at least as well as the probability distribution determined by the classical Naive Bayes (NB). Then, under a not very restrictive condition, we give a second algorithm for which we can prove that it finds the optimal GNB probability distribution, i.e. best fitting structure in the sense of KL divergence. Both algorithms are constructed to maximize the information content and aim to minimize redundancy. Based on these algorithms, new methods for feature selection are introduced. We discuss the similarities and differences to other related algorithms in terms of structure, methodology, and complexity. Experimental results show, that the algorithms introduced outperform the related algorithms in many cases.
Read more8/29/2024
0
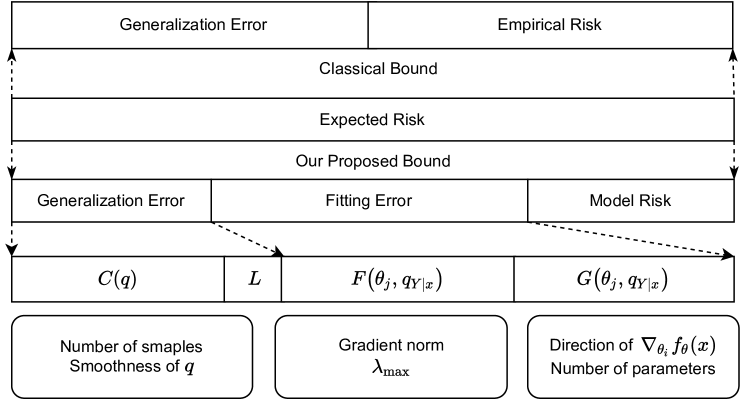
Error Bounds of Supervised Classification from Information-Theoretic Perspective
Binchuan Qi, Wei Gong, Li Li
There remains a list of unanswered research questions on deep learning (DL), including the remarkable generalization power of overparametrized neural networks, the efficient optimization performance despite the non-convexity, and the mechanisms behind flat minima in generalization. In this paper, we adopt an information-theoretic perspective to explore the theoretical foundations of supervised classification using deep neural networks (DNNs). Our analysis introduces the concepts of fitting error and model risk, which, together with generalization error, constitute an upper bound on the expected risk. We demonstrate that the generalization errors are bounded by the complexity, influenced by both the smoothness of distribution and the sample size. Consequently, task complexity serves as a reliable indicator of the dataset's quality, guiding the setting of regularization hyperparameters. Furthermore, the derived upper bound fitting error links the back-propagated gradient, Neural Tangent Kernel (NTK), and the model's parameter count with the fitting error. Utilizing the triangle inequality, we establish an upper bound on the expected risk. This bound offers valuable insights into the effects of overparameterization, non-convex optimization, and the flat minima in DNNs.Finally, empirical verification confirms a significant positive correlation between the derived theoretical bounds and the practical expected risk, confirming the practical relevance of the theoretical findings.
Read more6/28/2024