ShiftAddAug: Augment Multiplication-Free Tiny Neural Network with Hybrid Computation

0
Sign in to get full access
Overview
- This paper introduces ShiftAddAug, a technique to augment tiny neural networks with hybrid computation, focusing on multiplication-free operations.
- ShiftAddAug combines multiple efficient primitives like bit-shift, addition, and activation functions to create a powerful yet compact model.
- The authors demonstrate the effectiveness of ShiftAddAug on various vision tasks, showing it can achieve competitive performance compared to more complex models, while being extremely efficient.
Plain English Explanation
The research paper presents a new technique called ShiftAddAug that can make tiny neural networks more powerful without significantly increasing their size or complexity. Tiny neural networks are very efficient and can run on low-power devices, but they often struggle to match the performance of larger, more complex models.
ShiftAddAug tackles this problem by combining simple mathematical operations like bit-shifting and addition, along with activation functions, to create a hybrid computation approach. Bit-shifting and addition are much faster and more energy-efficient than traditional multiplication, which is commonly used in neural networks.
By leveraging this hybrid computation, the authors show that ShiftAddAug can achieve competitive performance on various computer vision tasks, such as image classification, while keeping the neural network small and efficient. This makes ShiftAddAug particularly useful for deploying AI models on devices with limited computing power, like smartphones or IoT sensors.
The key idea behind ShiftAddAug is to find the right balance between simplicity and effectiveness, allowing tiny neural networks to punch above their weight without becoming too bloated or power-hungry. This aligns with ongoing research efforts to create more efficient and robust AI models, accelerate large language models, and improve the robustness of AI systems.
Technical Explanation
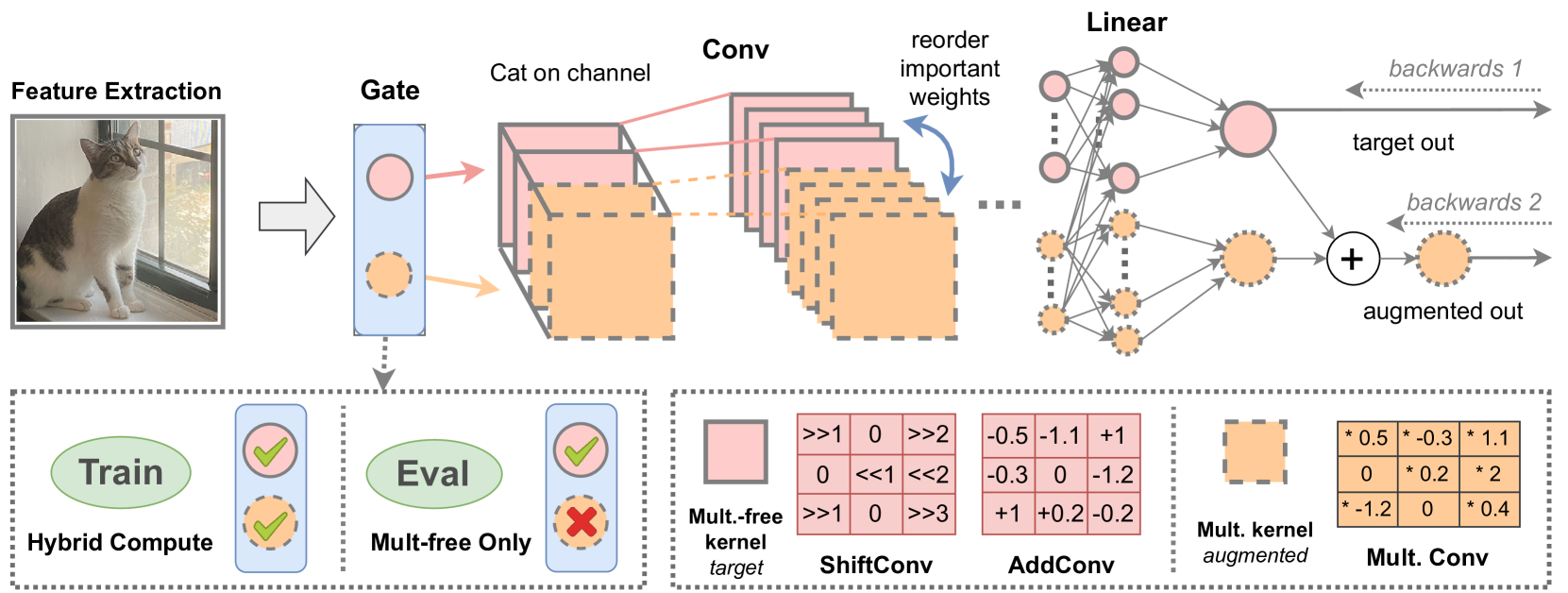
The core of ShiftAddAug is a hybrid computation approach that combines bit-shift, addition, and activation functions to perform operations typically done with more expensive multiplication.
The authors first design a baseline multiplication-free tiny neural network (MFTNN) that uses only bit-shift and addition operations. To further boost the performance of this MFTNN, they introduce ShiftAddAug, which applies a series of augmentation techniques:
- Shift-Add Block: Replacing standard convolution layers with a custom block that uses bit-shift and addition instead of multiplication.
- Activation Function Augmentation: Introducing a new activation function called ShiftMax that is suitable for the bit-shift and addition operations.
- Weight Quantization: Quantizing the network weights to reduce memory footprint and computation.
The authors evaluate ShiftAddAug on several computer vision tasks, including image classification and object detection. They show that ShiftAddAug can match or even outperform larger, more complex models like ResNet and EfficientNet, while being significantly more efficient in terms of model size and inference time.
Critical Analysis
The key strength of ShiftAddAug is its ability to enhance the performance of tiny neural networks without significantly increasing their complexity or resource requirements. This is a valuable contribution, as efficient AI models are crucial for deployment on resource-constrained devices.
However, the paper does not discuss the potential limitations or drawbacks of the ShiftAddAug approach. For example, it is unclear how the hybrid computation affects the model's representational capacity or its ability to learn more complex features. Additionally, the authors only evaluate ShiftAddAug on standard computer vision tasks, and it would be interesting to see how it performs on more diverse or challenging problems.
Further research could explore the generalization of ShiftAddAug to other domains, such as natural language processing or speech recognition, and investigate its suitability for more advanced neural network architectures. Comparing ShiftAddAug to other efficient model design techniques, like depthwise separable convolutions or sparse attention, could also provide valuable insights.
Conclusion
The ShiftAddAug technique presented in this paper offers a promising approach to enhancing the performance of tiny neural networks without significantly increasing their complexity or resource requirements. By leveraging efficient hybrid computation primitives like bit-shift and addition, ShiftAddAug can achieve competitive results on various computer vision tasks while maintaining a compact model size and fast inference.
This work aligns with ongoing efforts to create more efficient and robust AI systems, which is crucial for deploying advanced machine learning models on resource-constrained devices. As the demand for edge computing and embedded AI continues to grow, techniques like ShiftAddAug will likely play an increasingly important role in the development of practical and impactful AI applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ShiftAddAug: Augment Multiplication-Free Tiny Neural Network with Hybrid Computation
Yipin Guo, Zihao Li, Yilin Lang, Qinyuan Ren
Operators devoid of multiplication, such as Shift and Add, have gained prominence for their compatibility with hardware. However, neural networks (NNs) employing these operators typically exhibit lower accuracy compared to conventional NNs with identical structures. ShiftAddAug uses costly multiplication to augment efficient but less powerful multiplication-free operators, improving performance without any inference overhead. It puts a ShiftAdd tiny NN into a large multiplicative model and encourages it to be trained as a sub-model to obtain additional supervision. In order to solve the weight discrepancy problem between hybrid operators, a new weight sharing method is proposed. Additionally, a novel two stage neural architecture search is used to obtain better augmentation effects for smaller but stronger multiplication-free tiny neural networks. The superiority of ShiftAddAug is validated through experiments in image classification and semantic segmentation, consistently delivering noteworthy enhancements. Remarkably, it secures up to a 4.95% increase in accuracy on the CIFAR100 compared to its directly trained counterparts, even surpassing the performance of multiplicative NNs.
Read more7/4/2024
👀
0
ShiftAddViT: Mixture of Multiplication Primitives Towards Efficient Vision Transformer
Haoran You (Celine), Huihong Shi (Celine), Yipin Guo (Celine), Yingyan (Celine), Lin
Vision Transformers (ViTs) have shown impressive performance and have become a unified backbone for multiple vision tasks. However, both the attention mechanism and multi-layer perceptrons (MLPs) in ViTs are not sufficiently efficient due to dense multiplications, leading to costly training and inference. To this end, we propose to reparameterize pre-trained ViTs with a mixture of multiplication primitives, e.g., bitwise shifts and additions, towards a new type of multiplication-reduced model, dubbed $textbf{ShiftAddViT}$, which aims to achieve end-to-end inference speedups on GPUs without requiring training from scratch. Specifically, all $texttt{MatMuls}$ among queries, keys, and values are reparameterized using additive kernels, after mapping queries and keys to binary codes in Hamming space. The remaining MLPs or linear layers are then reparameterized with shift kernels. We utilize TVM to implement and optimize those customized kernels for practical hardware deployment on GPUs. We find that such a reparameterization on attention maintains model accuracy, while inevitably leading to accuracy drops when being applied to MLPs. To marry the best of both worlds, we further propose a new mixture of experts (MoE) framework to reparameterize MLPs by taking multiplication or its primitives as experts, e.g., multiplication and shift, and designing a new latency-aware load-balancing loss. Such a loss helps to train a generic router for assigning a dynamic amount of input tokens to different experts according to their latency. Extensive experiments on various 2D/3D Transformer-based vision tasks consistently validate the effectiveness of our proposed ShiftAddViT, achieving up to $textbf{5.18$times$}$ latency reductions on GPUs and $textbf{42.9}$% energy savings, while maintaining a comparable accuracy as original or efficient ViTs.
Read more6/12/2024

0
ShiftAddLLM: Accelerating Pretrained LLMs via Post-Training Multiplication-Less Reparameterization
Haoran You, Yipin Guo, Yichao Fu, Wei Zhou, Huihong Shi, Xiaofan Zhang, Souvik Kundu, Amir Yazdanbakhsh, Yingyan Celine Lin
Large language models (LLMs) have shown impressive performance on language tasks but face challenges when deployed on resource-constrained devices due to their extensive parameters and reliance on dense multiplications, resulting in high memory demands and latency bottlenecks. Shift-and-add reparameterization offers a promising solution by replacing costly multiplications with hardware-friendly primitives in both the attention and multi-layer perceptron (MLP) layers of an LLM. However, current reparameterization techniques require training from scratch or full parameter fine-tuning to restore accuracy, which is resource-intensive for LLMs. To address this, we propose accelerating pretrained LLMs through post-training shift-and-add reparameterization, creating efficient multiplication-free models, dubbed ShiftAddLLM. Specifically, we quantize each weight matrix into binary matrices paired with group-wise scaling factors. The associated multiplications are reparameterized into (1) shifts between activations and scaling factors and (2) queries and adds according to the binary matrices. To reduce accuracy loss, we present a multi-objective optimization method to minimize both weight and output activation reparameterization errors. Additionally, based on varying sensitivity across layers to reparameterization, we develop an automated bit allocation strategy to further reduce memory usage and latency. Experiments on five LLM families and eight tasks consistently validate the effectiveness of ShiftAddLLM, achieving average perplexity improvements of 5.6 and 22.7 points at comparable or lower latency compared to the most competitive quantized LLMs at 3 and 2 bits, respectively, and more than 80% memory and energy reductions over the original LLMs. Codes and models are available at https://github.com/GATECH-EIC/ShiftAddLLM.
Read more7/26/2024
0
SA-MLP: Enhancing Point Cloud Classification with Efficient Addition and Shift Operations in MLP Architectures
Qiang Zheng, Chao Zhang, Jian Sun
This study addresses the computational inefficiencies in point cloud classification by introducing novel MLP-based architectures inspired by recent advances in CNN optimization. Traditional neural networks heavily rely on multiplication operations, which are computationally expensive. To tackle this, we propose Add-MLP and Shift-MLP, which replace multiplications with addition and shift operations, respectively, significantly enhancing computational efficiency. Building on this, we introduce SA-MLP, a hybrid model that intermixes alternately distributed shift and adder layers to replace MLP layers, maintaining the original number of layers without freezing shift layer weights. This design contrasts with the ShiftAddNet model from previous literature, which replaces convolutional layers with shift and adder layers, leading to a doubling of the number of layers and limited representational capacity due to frozen shift weights. Moreover, SA-MLP optimizes learning by setting distinct learning rates and optimizers specifically for the adder and shift layers, fully leveraging their complementary strengths. Extensive experiments demonstrate that while Add-MLP and Shift-MLP achieve competitive performance, SA-MLP significantly surpasses the multiplication-based baseline MLP model and achieves performance comparable to state-of-the-art MLP-based models. This study offers an efficient and effective solution for point cloud classification, balancing performance with computational efficiency.
Read more9/4/2024