SA-MLP: Enhancing Point Cloud Classification with Efficient Addition and Shift Operations in MLP Architectures

0
Sign in to get full access
Overview
- The paper proposes a new architecture called SA-MLP (Shift-Add Multilayer Perceptron) that enhances point cloud classification by efficiently incorporating addition and shift operations.
- The authors demonstrate that their approach outperforms state-of-the-art MLP-based models on various point cloud classification benchmarks.
- The core idea is to replace the computationally expensive matrix multiplication in traditional MLPs with a combination of efficient addition and shift operations.
Plain English Explanation
The paper introduces a new type of neural network architecture called SA-MLP that is designed to work well with point cloud data. Point clouds are 3D representations of objects or environments, often used in applications like self-driving cars and robotics.
Traditional neural networks, called multilayer perceptrons (MLPs), use matrix multiplication as a key operation. However, matrix multiplication can be slow and computationally expensive, especially for large inputs like point clouds. The researchers behind SA-MLP found a way to replace the matrix multiplication with simpler, more efficient operations - addition and bit-shifting.
Bit-shifting is a basic operation in computer science that quickly moves the bits in a number to the left or right. By using addition and bit-shifting instead of matrix multiplication, the SA-MLP architecture can process point cloud data more efficiently.
The researchers show that their SA-MLP model outperforms other state-of-the-art MLP-based models on several standard benchmarks for point cloud classification. This means SA-MLP is better at correctly identifying and categorizing 3D objects represented as point clouds.
Technical Explanation
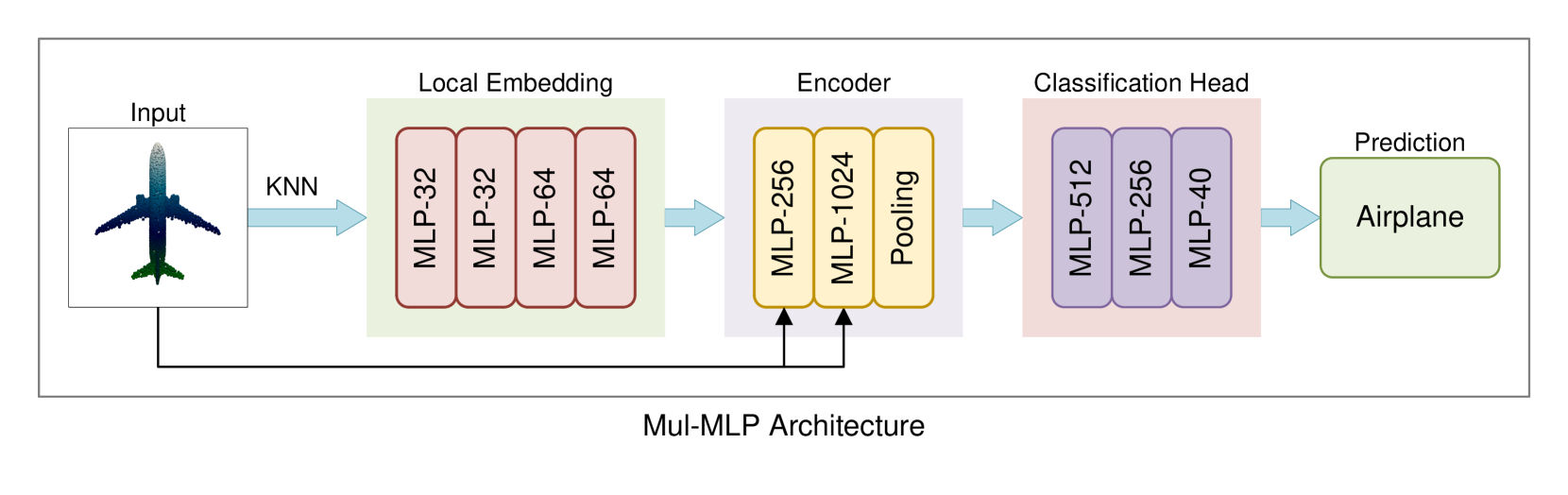
The key innovation in the SA-MLP architecture is the replacement of computationally expensive matrix multiplication with a combination of addition and shift operations. Specifically, the authors propose the following modifications to the traditional MLP:
-
Shift-Add Layer: This layer replaces the standard linear layer (which uses matrix multiplication) with a shift-add operation. The input features are first split into multiple branches, each of which is shifted by a learnable amount and then summed together.
-
Shift-Add Attention: The authors also introduce a shift-add attention mechanism, where the attention weights are computed using shift-add operations instead of matrix multiplication.
These efficient shift-add operations allow the SA-MLP model to achieve better performance compared to standard MLPs, especially on large-scale point cloud datasets, while being more computationally efficient.
The authors evaluate their SA-MLP architecture on several point cloud classification benchmarks, including ModelNet40, ShapeNet, and ScanObjectNN. They demonstrate that SA-MLP outperforms state-of-the-art MLP-based models like PointMLP and ShiftAddVIT in terms of classification accuracy, while also being more efficient in terms of inference time and model size.
Critical Analysis
The authors thoroughly evaluate their SA-MLP architecture and provide a detailed analysis of its performance. However, there are a few potential limitations and areas for further research:
-
Generalization to other tasks: The paper focuses solely on point cloud classification, and it's unclear how well the shift-add operations would generalize to other point cloud-related tasks, such as segmentation or registration.
-
Comparison to other efficient architectures: While the authors compare SA-MLP to other MLP-based models, it would be interesting to see how it performs against more recent efficient neural network architectures, such as ShiftAddAug or PointMT, which also aim to reduce computational complexity.
-
Potential limitations of shift-add operations: The authors do not discuss any potential limitations or drawbacks of the shift-add operations, such as their ability to capture more complex feature interactions compared to standard linear layers.
Overall, the SA-MLP architecture presents an interesting and efficient approach to point cloud classification, but further research is needed to understand its broader applicability and potential limitations.
Conclusion
The SA-MLP architecture proposed in this paper demonstrates a novel way to enhance point cloud classification by replacing the computationally expensive matrix multiplication in traditional MLPs with efficient addition and shift operations. The authors show that their approach outperforms state-of-the-art MLP-based models on various benchmarks, making it a promising solution for efficient processing of 3D point cloud data in applications like robotics, autonomous vehicles, and augmented reality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SA-MLP: Enhancing Point Cloud Classification with Efficient Addition and Shift Operations in MLP Architectures
Qiang Zheng, Chao Zhang, Jian Sun
This study addresses the computational inefficiencies in point cloud classification by introducing novel MLP-based architectures inspired by recent advances in CNN optimization. Traditional neural networks heavily rely on multiplication operations, which are computationally expensive. To tackle this, we propose Add-MLP and Shift-MLP, which replace multiplications with addition and shift operations, respectively, significantly enhancing computational efficiency. Building on this, we introduce SA-MLP, a hybrid model that intermixes alternately distributed shift and adder layers to replace MLP layers, maintaining the original number of layers without freezing shift layer weights. This design contrasts with the ShiftAddNet model from previous literature, which replaces convolutional layers with shift and adder layers, leading to a doubling of the number of layers and limited representational capacity due to frozen shift weights. Moreover, SA-MLP optimizes learning by setting distinct learning rates and optimizers specifically for the adder and shift layers, fully leveraging their complementary strengths. Extensive experiments demonstrate that while Add-MLP and Shift-MLP achieve competitive performance, SA-MLP significantly surpasses the multiplication-based baseline MLP model and achieves performance comparable to state-of-the-art MLP-based models. This study offers an efficient and effective solution for point cloud classification, balancing performance with computational efficiency.
Read more9/4/2024
0
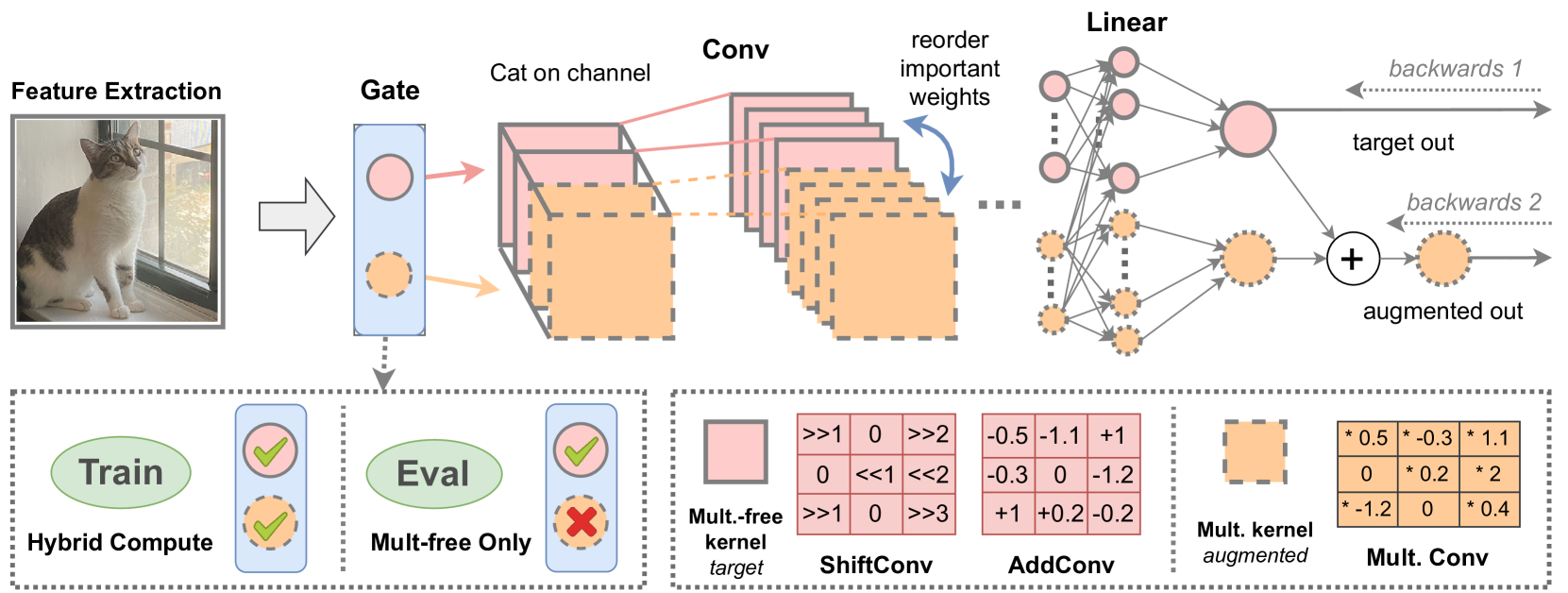
ShiftAddAug: Augment Multiplication-Free Tiny Neural Network with Hybrid Computation
Yipin Guo, Zihao Li, Yilin Lang, Qinyuan Ren
Operators devoid of multiplication, such as Shift and Add, have gained prominence for their compatibility with hardware. However, neural networks (NNs) employing these operators typically exhibit lower accuracy compared to conventional NNs with identical structures. ShiftAddAug uses costly multiplication to augment efficient but less powerful multiplication-free operators, improving performance without any inference overhead. It puts a ShiftAdd tiny NN into a large multiplicative model and encourages it to be trained as a sub-model to obtain additional supervision. In order to solve the weight discrepancy problem between hybrid operators, a new weight sharing method is proposed. Additionally, a novel two stage neural architecture search is used to obtain better augmentation effects for smaller but stronger multiplication-free tiny neural networks. The superiority of ShiftAddAug is validated through experiments in image classification and semantic segmentation, consistently delivering noteworthy enhancements. Remarkably, it secures up to a 4.95% increase in accuracy on the CIFAR100 compared to its directly trained counterparts, even surpassing the performance of multiplicative NNs.
Read more7/4/2024

0
PointMT: Efficient Point Cloud Analysis with Hybrid MLP-Transformer Architecture
Qiang Zheng, Chao Zhang, Jian Sun
In recent years, point cloud analysis methods based on the Transformer architecture have made significant progress, particularly in the context of multimedia applications such as 3D modeling, virtual reality, and autonomous systems. However, the high computational resource demands of the Transformer architecture hinder its scalability, real-time processing capabilities, and deployment on mobile devices and other platforms with limited computational resources. This limitation remains a significant obstacle to its practical application in scenarios requiring on-device intelligence and multimedia processing. To address this challenge, we propose an efficient point cloud analysis architecture, textbf{Point} textbf{M}LP-textbf{T}ransformer (PointMT). This study tackles the quadratic complexity of the self-attention mechanism by introducing a linear complexity local attention mechanism for effective feature aggregation. Additionally, to counter the Transformer's focus on token differences while neglecting channel differences, we introduce a parameter-free channel temperature adaptation mechanism that adaptively adjusts the attention weight distribution in each channel, enhancing the precision of feature aggregation. To improve the Transformer's slow convergence speed due to the limited scale of point cloud datasets, we propose an MLP-Transformer hybrid module, which significantly enhances the model's convergence speed. Furthermore, to boost the feature representation capability of point tokens, we refine the classification head, enabling point tokens to directly participate in prediction. Experimental results on multiple evaluation benchmarks demonstrate that PointMT achieves performance comparable to state-of-the-art methods while maintaining an optimal balance between performance and accuracy.
Read more9/17/2024
🖼️
0
Caterpillar: A Pure-MLP Architecture with Shifted-Pillars-Concatenation
Jin Sun, Xiaoshuang Shi, Zhiyuan Wang, Kaidi Xu, Heng Tao Shen, Xiaofeng Zhu
Modeling in Computer Vision has evolved to MLPs. Vision MLPs naturally lack local modeling capability, to which the simplest treatment is combined with convolutional layers. Convolution, famous for its sliding window scheme, also suffers from this scheme of redundancy and lower parallel computation. In this paper, we seek to dispense with the windowing scheme and introduce a more elaborate and parallelizable method to exploit locality. To this end, we propose a new MLP module, namely Shifted-Pillars-Concatenation (SPC), that consists of two steps of processes: (1) Pillars-Shift, which generates four neighboring maps by shifting the input image along four directions, and (2) Pillars-Concatenation, which applies linear transformations and concatenation on the maps to aggregate local features. SPC module offers superior local modeling power and performance gains, making it a promising alternative to the convolutional layer. Then, we build a pure-MLP architecture called Caterpillar by replacing the convolutional layer with the SPC module in a hybrid model of sMLPNet. Extensive experiments show Caterpillar's excellent performance on both small-scale and ImageNet-1k classification benchmarks, with remarkable scalability and transfer capability possessed as well. The code is available at https://github.com/sunjin19126/Caterpillar.
Read more9/11/2024