SHIRE: Enhancing Sample Efficiency using Human Intuition in REinforcement Learning

0

Sign in to get full access
Overview
- The paper presents SHIRE, a method for enhancing sample efficiency in reinforcement learning using human intuition.
- SHIRE aims to accelerate reinforcement learning by incorporating human knowledge and preferences into the learning process.
- The approach involves learning a reward function from human feedback and using it to guide the agent's exploration and policy learning.
Plain English Explanation
What is reinforcement learning? Reinforcement learning is a type of machine learning where an agent interacts with an environment, taking actions and receiving rewards or penalties. The agent's goal is to learn the best actions to maximize its cumulative reward.
Why is sample efficiency important? Reinforcement learning often requires a large number of training samples or interactions with the environment to achieve good performance. This can be costly, time-consuming, and impractical for many real-world applications. Enhancing sample efficiency is crucial to make reinforcement learning more practical and widely applicable.
How does SHIRE work? SHIRE aims to leverage human intuition and feedback to guide the reinforcement learning process and make it more sample-efficient. The key idea is to learn a reward function from human preferences and use it to shape the agent's exploration and policy learning. This allows the agent to focus on discovering high-reward actions and strategies more quickly, without having to blindly explore the entire environment.
What are the benefits of SHIRE? By incorporating human intuition, SHIRE can help reinforcement learning agents learn more efficiently and achieve better performance with fewer training samples. This can make reinforcement learning more practical and widely applicable, especially in domains where data collection is costly or time-consuming.
Technical Explanation
SHIRE consists of two main components:
-
Reward Learning from Human Feedback: The method learns a reward function from human feedback on the agent's actions or trajectories. This allows the human to express their preferences and guide the agent towards desirable behaviors.
-
Sample-Efficient Reinforcement Learning: The learned reward function is then used to shape the agent's exploration and policy learning, enabling it to focus on discovering high-reward actions and strategies more quickly.
The key elements of the SHIRE approach are:
- Human Feedback Collection: Humans provide feedback on the agent's actions or trajectories, indicating their preferences and evaluation of the agent's behavior.
- Reward Function Learning: A neural network-based model is trained to learn a reward function that best matches the human feedback.
- Guided Exploration: The learned reward function is used to guide the agent's exploration, biasing it towards actions and states that are more likely to be rewarding according to the human's preferences.
- Policy Learning: The agent's policy is then learned using the guided exploration and the learned reward function, allowing it to discover high-performing strategies more efficiently.
The paper presents experiments in several reinforcement learning domains, including simulated robotics tasks and Atari games, demonstrating the effectiveness of SHIRE in improving sample efficiency and performance compared to standard reinforcement learning approaches.
Critical Analysis
The paper provides a thorough evaluation of the SHIRE method and acknowledges several limitations and areas for future research:
- Generalization to Novel Tasks: While SHIRE demonstrates improvements in the evaluated tasks, the authors note that the method's ability to generalize to completely novel tasks or environments is an open question that requires further investigation.
- Scalability and Robustness: The performance of SHIRE may be sensitive to the quality and quantity of human feedback, and the authors suggest exploring ways to make the method more robust and scalable to handle diverse human inputs.
- Interpretability and Transparency: The paper does not extensively discuss the interpretability of the learned reward function or the agent's decision-making process, which could be an important consideration for real-world applications.
Overall, the SHIRE approach represents a promising step towards enhancing the sample efficiency of reinforcement learning by leveraging human intuition and preferences. However, further research is needed to address the identified limitations and explore the broader applicability and implications of this technique.
Conclusion
The SHIRE method presented in this paper offers a novel approach to improving the sample efficiency of reinforcement learning by incorporating human intuition and feedback. By learning a reward function from human preferences and using it to guide the agent's exploration and policy learning, SHIRE can help reinforcement learning agents discover high-performing strategies more quickly, without requiring as many training samples.
The results demonstrate the effectiveness of this approach in various reinforcement learning domains, but also highlight the need for further research to address the limitations, such as generalization to novel tasks, scalability, and interpretability. As reinforcement learning continues to advance, techniques like SHIRE that can leverage human knowledge and intuition could play an important role in making these powerful AI systems more practical and widely applicable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SHIRE: Enhancing Sample Efficiency using Human Intuition in REinforcement Learning
Amogh Joshi, Adarsh Kumar Kosta, Kaushik Roy
The ability of neural networks to perform robotic perception and control tasks such as depth and optical flow estimation, simultaneous localization and mapping (SLAM), and automatic control has led to their widespread adoption in recent years. Deep Reinforcement Learning has been used extensively in these settings, as it does not have the unsustainable training costs associated with supervised learning. However, DeepRL suffers from poor sample efficiency, i.e., it requires a large number of environmental interactions to converge to an acceptable solution. Modern RL algorithms such as Deep Q Learning and Soft Actor-Critic attempt to remedy this shortcoming but can not provide the explainability required in applications such as autonomous robotics. Humans intuitively understand the long-time-horizon sequential tasks common in robotics. Properly using such intuition can make RL policies more explainable while enhancing their sample efficiency. In this work, we propose SHIRE, a novel framework for encoding human intuition using Probabilistic Graphical Models (PGMs) and using it in the Deep RL training pipeline to enhance sample efficiency. Our framework achieves 25-78% sample efficiency gains across the environments we evaluate at negligible overhead cost. Additionally, by teaching RL agents the encoded elementary behavior, SHIRE enhances policy explainability. A real-world demonstration further highlights the efficacy of policies trained using our framework.
Read more9/17/2024
0
Concept-Based Interpretable Reinforcement Learning with Limited to No Human Labels
Zhuorui Ye, Stephanie Milani, Geoffrey J. Gordon, Fei Fang
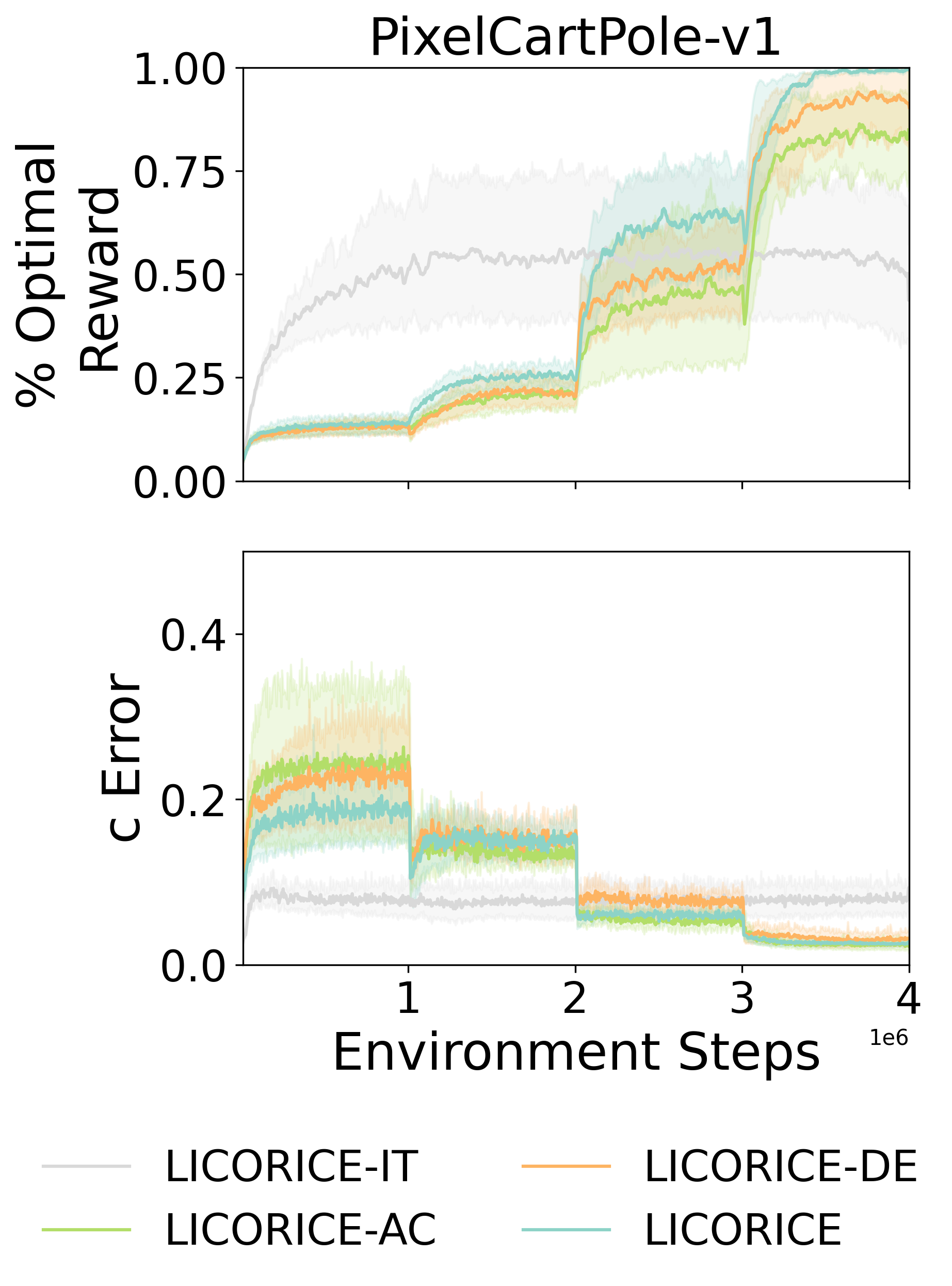
Recent advances in reinforcement learning (RL) have predominantly leveraged neural network-based policies for decision-making, yet these models often lack interpretability, posing challenges for stakeholder comprehension and trust. Concept bottleneck models offer an interpretable alternative by integrating human-understandable concepts into neural networks. However, a significant limitation in prior work is the assumption that human annotations for these concepts are readily available during training, necessitating continuous real-time input from human annotators. To overcome this limitation, we introduce a novel training scheme that enables RL algorithms to efficiently learn a concept-based policy by only querying humans to label a small set of data, or in the extreme case, without any human labels. Our algorithm, LICORICE, involves three main contributions: interleaving concept learning and RL training, using a concept ensembles to actively select informative data points for labeling, and decorrelating the concept data with a simple strategy. We show how LICORICE reduces manual labeling efforts to to 500 or fewer concept labels in three environments. Finally, we present an initial study to explore how we can use powerful vision-language models to infer concepts from raw visual inputs without explicit labels at minimal cost to performance.
Read more7/23/2024

0
ViSaRL: Visual Reinforcement Learning Guided by Human Saliency
Anthony Liang, Jesse Thomason, Erdem B{i}y{i}k
Training robots to perform complex control tasks from high-dimensional pixel input using reinforcement learning (RL) is sample-inefficient, because image observations are comprised primarily of task-irrelevant information. By contrast, humans are able to visually attend to task-relevant objects and areas. Based on this insight, we introduce Visual Saliency-Guided Reinforcement Learning (ViSaRL). Using ViSaRL to learn visual representations significantly improves the success rate, sample efficiency, and generalization of an RL agent on diverse tasks including DeepMind Control benchmark, robot manipulation in simulation and on a real robot. We present approaches for incorporating saliency into both CNN and Transformer-based encoders. We show that visual representations learned using ViSaRL are robust to various sources of visual perturbations including perceptual noise and scene variations. ViSaRL nearly doubles success rate on the real-robot tasks compared to the baseline which does not use saliency.
Read more9/11/2024
0
Efficient Reinforcement Learning via Large Language Model-based Search
Siddhant Bhambri, Amrita Bhattacharjee, Huan Liu, Subbarao Kambhampati
Reinforcement Learning (RL) suffers from sample inefficiency in sparse reward domains, and the problem is pronounced if there are stochastic transitions. To improve the sample efficiency, reward shaping is a well-studied approach to introduce intrinsic rewards that can help the RL agent converge to an optimal policy faster. However, designing a useful reward shaping function specific to each problem is challenging, even for domain experts. They would either have to rely on task-specific domain knowledge or provide an expert demonstration independently for each task. Given, that Large Language Models (LLMs) have rapidly gained prominence across a magnitude of natural language tasks, we aim to answer the following question: Can we leverage LLMs to construct a reward shaping function that can boost the sample efficiency of an RL agent? In this work, we aim to leverage off-the-shelf LLMs to generate a guide policy by solving a simpler deterministic abstraction of the original problem that can then be used to construct the reward shaping function for the downstream RL agent. Given the ineffectiveness of directly prompting LLMs, we propose MEDIC: a framework that augments LLMs with a Model-based feEDback critIC, which verifies LLM-generated outputs, to generate a possibly sub-optimal but valid plan for the abstract problem. Our experiments across domains from the BabyAI environment suite show 1) the effectiveness of augmenting LLMs with MEDIC, 2) a significant improvement in the sample complexity of PPO and A2C-based RL agents when guided by our LLM-generated plan, and finally, 3) pave the direction for further explorations of how these models can be used to augment existing RL pipelines.
Read more5/27/2024