Concept-Based Interpretable Reinforcement Learning with Limited to No Human Labels

0
Sign in to get full access
Overview
- The paper introduces a concept-based interpretable reinforcement learning (RL) approach that can learn from limited to no human labels.
- It aims to improve the interpretability and sample-efficiency of RL agents by leveraging high-level concepts.
- The method learns a concept-based policy that maps states to actions through an interpretable concept representation.
Plain English Explanation
The research paper presents a new approach to reinforcement learning that focuses on using high-level concepts to help the agent learn more efficiently and in a more interpretable way.
In typical reinforcement learning, the agent learns to map states (the current situation) directly to actions (what to do). This can be a complex process, especially when the environment is complex. The researchers' idea is to have the agent first learn to recognize high-level concepts in the environment, and then use those concepts to decide on the best actions to take.
For example, imagine a robot learning to navigate a room. Instead of just trying to learn how to map every possible sensor reading to the right motor commands, the robot might first learn concepts like "wall," "open space," "obstacle," etc. It can then use those concepts to plan its movements in a more interpretable way, like "avoid obstacles," "move towards open space," etc.
By basing the decision-making on these higher-level concepts, the reinforcement learning agent can learn more efficiently, using fewer training examples. It also becomes easier for humans to understand and debug the agent's behavior, since the concepts provide a layer of interpretability.
The key innovation in this paper is the ability to learn these interpretable concepts with limited or no human-provided labels. This makes the approach more practical and scalable, as gathering large amounts of labeled data can be challenging.
Technical Explanation
The paper proposes a concept-based RL framework that learns an interpretable concept representation and a concept-based policy simultaneously.
The agent's decision-making process is structured as follows:
- Perceive the current state of the environment
- Recognize relevant high-level concepts in the state
- Use the recognized concepts to select the best action to take
The concept recognition and policy learning are trained end-to-end using a novel objective function that encourages the concepts to be both predictive of the optimal actions and interpretable to humans.
Crucially, the method can learn the concept representations with limited or no human-provided labels. This is achieved by leveraging self-supervised learning techniques to discover the relevant concepts from the environment dynamics alone.
The paper evaluates the concept-based RL approach on several reinforcement learning benchmarks and shows improvements in sample efficiency and interpretability compared to standard RL methods.
Critical Analysis
The paper presents a promising direction for making reinforcement learning more interpretable and sample-efficient. The ability to learn useful concepts with minimal human supervision is a valuable capability, as it reduces the burden of data collection and annotation.
However, the paper does not fully address the potential limitations of the concept-based approach. For example, the learned concepts may not always align with human intuitions, and it's not clear how to ensure the concepts remain interpretable as the agent becomes more complex.
Additionally, the evaluation is limited to relatively simple environments, and it's unclear how well the approach would scale to larger, more realistic problems. Further research is needed to understand the broader applicability and potential pitfalls of this concept-based RL framework.
Conclusion
This paper introduces an innovative concept-based reinforcement learning approach that can learn interpretable representations and policies from limited to no human labels. By basing decision-making on high-level concepts, the agents can learn more efficiently and in a more transparent manner.
While the initial results are promising, further research is needed to fully understand the capabilities and limitations of this approach. Nonetheless, the work represents an important step towards developing more interpretable and sample-efficient RL systems, which could have significant implications for real-world applications of reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Concept-Based Interpretable Reinforcement Learning with Limited to No Human Labels
Zhuorui Ye, Stephanie Milani, Geoffrey J. Gordon, Fei Fang
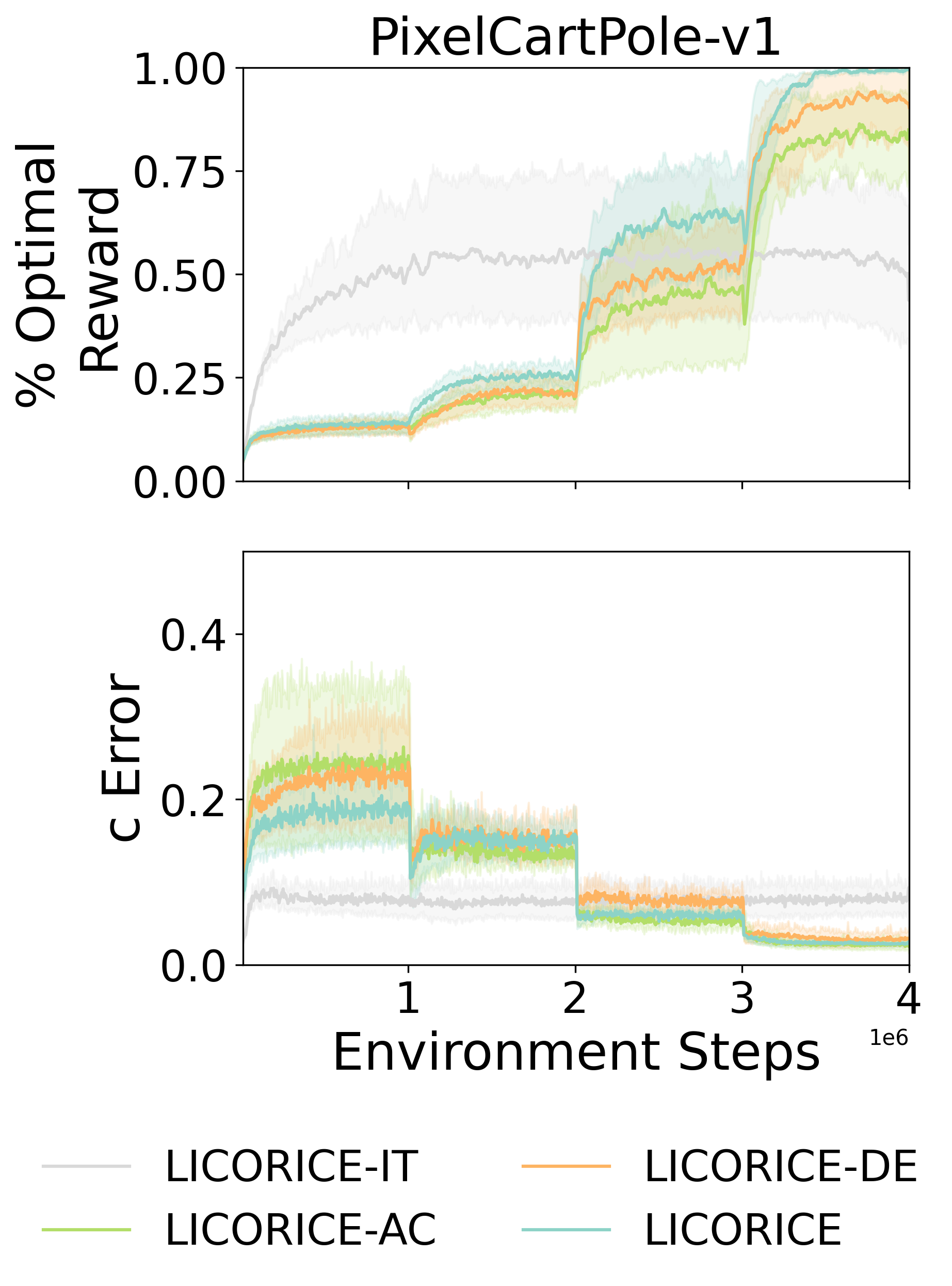
Recent advances in reinforcement learning (RL) have predominantly leveraged neural network-based policies for decision-making, yet these models often lack interpretability, posing challenges for stakeholder comprehension and trust. Concept bottleneck models offer an interpretable alternative by integrating human-understandable concepts into neural networks. However, a significant limitation in prior work is the assumption that human annotations for these concepts are readily available during training, necessitating continuous real-time input from human annotators. To overcome this limitation, we introduce a novel training scheme that enables RL algorithms to efficiently learn a concept-based policy by only querying humans to label a small set of data, or in the extreme case, without any human labels. Our algorithm, LICORICE, involves three main contributions: interleaving concept learning and RL training, using a concept ensembles to actively select informative data points for labeling, and decorrelating the concept data with a simple strategy. We show how LICORICE reduces manual labeling efforts to to 500 or fewer concept labels in three environments. Finally, we present an initial study to explore how we can use powerful vision-language models to infer concepts from raw visual inputs without explicit labels at minimal cost to performance.
Read more7/23/2024

0
Interpretable Concept Bottlenecks to Align Reinforcement Learning Agents
Quentin Delfosse, Sebastian Sztwiertnia, Mark Rothermel, Wolfgang Stammer, Kristian Kersting
Goal misalignment, reward sparsity and difficult credit assignment are only a few of the many issues that make it difficult for deep reinforcement learning (RL) agents to learn optimal policies. Unfortunately, the black-box nature of deep neural networks impedes the inclusion of domain experts for inspecting the model and revising suboptimal policies. To this end, we introduce *Successive Concept Bottleneck Agents* (SCoBots), that integrate consecutive concept bottleneck (CB) layers. In contrast to current CB models, SCoBots do not just represent concepts as properties of individual objects, but also as relations between objects which is crucial for many RL tasks. Our experimental results provide evidence of SCoBots' competitive performances, but also of their potential for domain experts to understand and regularize their behavior. Among other things, SCoBots enabled us to identify a previously unknown misalignment problem in the iconic video game, Pong, and resolve it. Overall, SCoBots thus result in more human-aligned RL agents. Our code is available at https://github.com/k4ntz/SCoBots .
Read more5/28/2024
💬
0
Policy Learning with a Language Bottleneck
Megha Srivastava, Cedric Colas, Dorsa Sadigh, Jacob Andreas
Modern AI systems such as self-driving cars and game-playing agents achieve superhuman performance, but often lack human-like features such as generalization, interpretability and human inter-operability. Inspired by the rich interactions between language and decision-making in humans, we introduce Policy Learning with a Language Bottleneck (PLLB), a framework enabling AI agents to generate linguistic rules that capture the strategies underlying their most rewarding behaviors. PLLB alternates between a rule generation step guided by language models, and an update step where agents learn new policies guided by rules. In a two-player communication game, a maze solving task, and two image reconstruction tasks, we show that PLLB agents are not only able to learn more interpretable and generalizable behaviors, but can also share the learned rules with human users, enabling more effective human-AI coordination.
Read more5/8/2024
🏅
0
Vision-Language Models Provide Promptable Representations for Reinforcement Learning
William Chen, Oier Mees, Aviral Kumar, Sergey Levine
Humans can quickly learn new behaviors by leveraging background world knowledge. In contrast, agents trained with reinforcement learning (RL) typically learn behaviors from scratch. We thus propose a novel approach that uses the vast amounts of general and indexable world knowledge encoded in vision-language models (VLMs) pre-trained on Internet-scale data for embodied RL. We initialize policies with VLMs by using them as promptable representations: embeddings that encode semantic features of visual observations based on the VLM's internal knowledge and reasoning capabilities, as elicited through prompts that provide task context and auxiliary information. We evaluate our approach on visually-complex, long horizon RL tasks in Minecraft and robot navigation in Habitat. We find that our policies trained on embeddings from off-the-shelf, general-purpose VLMs outperform equivalent policies trained on generic, non-promptable image embeddings. We also find our approach outperforms instruction-following methods and performs comparably to domain-specific embeddings. Finally, we show that our approach can use chain-of-thought prompting to produce representations of common-sense semantic reasoning, improving policy performance in novel scenes by 1.5 times.
Read more5/24/2024