Short-Long Policy Evaluation with Novel Actions

0
Sign in to get full access
Overview
- Evaluates short-term and long-term policy performance in environments with novel actions
- Introduces a framework for jointly optimizing short-term and long-term rewards
- Demonstrates how this approach outperforms existing methods on various benchmarks
Plain English Explanation
The paper addresses the challenge of evaluating policy performance in environments where agents can take novel actions that were not seen during training. This is an important problem, as real-world decision-making often involves responding to unexpected situations.
The key idea is to jointly optimize for both short-term and long-term rewards, rather than focusing only on immediate payoffs. This allows the agent to make decisions that balance near-term gains with longer-term strategic considerations. The authors introduce a framework that can handle novel actions and demonstrate its advantages over existing approaches on a variety of benchmarks.
Technical Explanation
The paper formalizes the short-long policy evaluation problem, where an agent must decide how to act in an environment that may include previously unseen "novel" actions. The authors propose a new objective function that aims to optimize a weighted sum of short-term and long-term rewards.
To operationalize this, they develop a
Critical Analysis
The paper makes a valuable contribution by addressing the realistic challenge of novel actions in policy evaluation. However, the authors acknowledge several limitations, such as the need for a pre-defined action space and the assumption that novel actions can be sampled from a particular distribution.
Additionally, the experiments are conducted in relatively simple simulated environments, so further research is needed to understand how this framework would scale to real-world decision-making problems with high stakes and complex dynamics. Broader validation across diverse domains would also strengthen the generalizability of the findings.
Conclusion
This work introduces a novel framework for jointly optimizing short-term and long-term rewards in the presence of novel actions. By taking a more holistic view of policy performance, the approach can lead to more robust and strategic decision-making, with potential applications in areas like robotics, healthcare, and finance. The technical contributions and empirical results provide a solid foundation for further research in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Short-Long Policy Evaluation with Novel Actions
Hyunji Alex Nam, Yash Chandak, Emma Brunskill
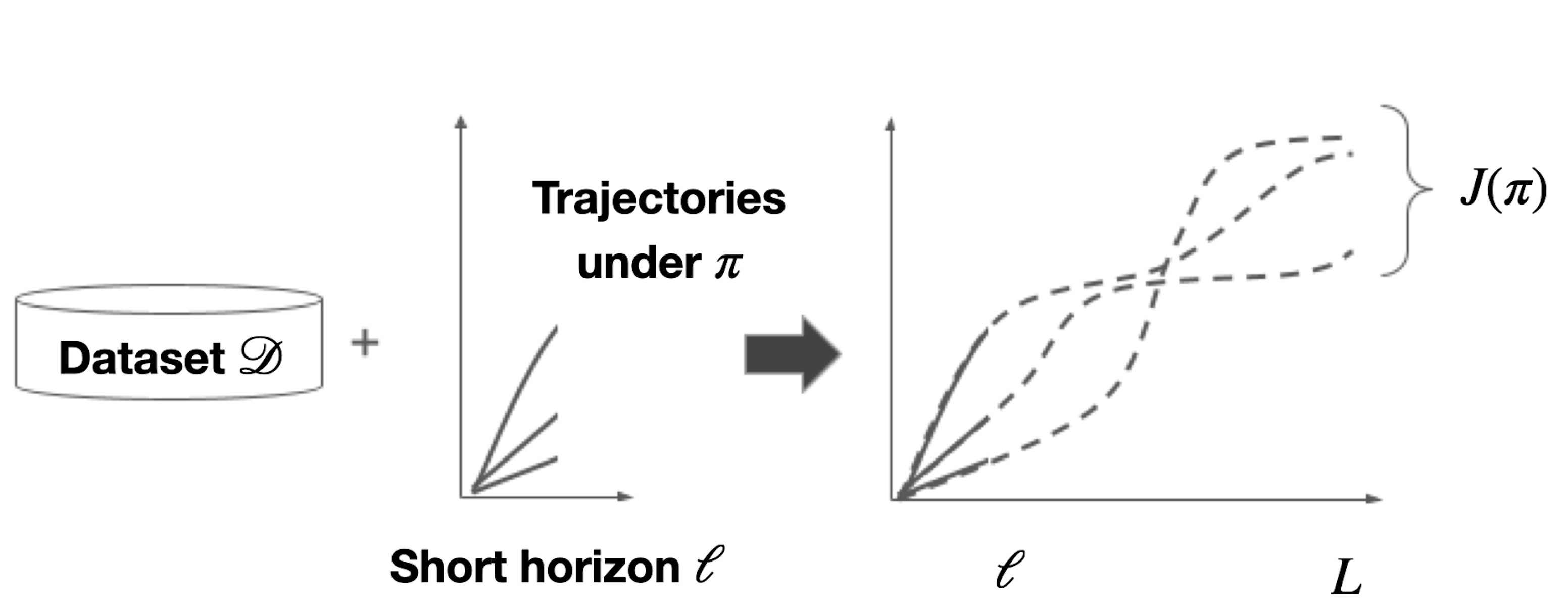
From incorporating LLMs in education, to identifying new drugs and improving ways to charge batteries, innovators constantly try new strategies in search of better long-term outcomes for students, patients and consumers. One major bottleneck in this innovation cycle is the amount of time it takes to observe the downstream effects of a decision policy that incorporates new interventions. The key question is whether we can quickly evaluate long-term outcomes of a new decision policy without making long-term observations. Organizations often have access to prior data about past decision policies and their outcomes, evaluated over the full horizon of interest. Motivated by this, we introduce a new setting for short-long policy evaluation for sequential decision making tasks. Our proposed methods significantly outperform prior results on simulators of HIV treatment, kidney dialysis and battery charging. We also demonstrate that our methods can be useful for applications in AI safety by quickly identifying when a new decision policy is likely to have substantially lower performance than past policies.
Read more7/11/2024

0
Policy Learning for Balancing Short-Term and Long-Term Rewards
Peng Wu, Ziyu Shen, Feng Xie, Zhongyao Wang, Chunchen Liu, Yan Zeng
Empirical researchers and decision-makers spanning various domains frequently seek profound insights into the long-term impacts of interventions. While the significance of long-term outcomes is undeniable, an overemphasis on them may inadvertently overshadow short-term gains. Motivated by this, this paper formalizes a new framework for learning the optimal policy that effectively balances both long-term and short-term rewards, where some long-term outcomes are allowed to be missing. In particular, we first present the identifiability of both rewards under mild assumptions. Next, we deduce the semiparametric efficiency bounds, along with the consistency and asymptotic normality of their estimators. We also reveal that short-term outcomes, if associated, contribute to improving the estimator of the long-term reward. Based on the proposed estimators, we develop a principled policy learning approach and further derive the convergence rates of regret and estimation errors associated with the learned policy. Extensive experiments are conducted to validate the effectiveness of the proposed method, demonstrating its practical applicability.
Read more9/17/2024
0
Long and Short-Term Constraints Driven Safe Reinforcement Learning for Autonomous Driving
Xuemin Hu, Pan Chen, Yijun Wen, Bo Tang, Long Chen
Reinforcement learning (RL) has been widely used in decision-making and control tasks, but the risk is very high for the agent in the training process due to the requirements of interaction with the environment, which seriously limits its industrial applications such as autonomous driving systems. Safe RL methods are developed to handle this issue by constraining the expected safety violation costs as a training objective, but the occurring probability of an unsafe state is still high, which is unacceptable in autonomous driving tasks. Moreover, these methods are difficult to achieve a balance between the cost and return expectations, which leads to learning performance degradation for the algorithms. In this paper, we propose a novel algorithm based on the long and short-term constraints (LSTC) for safe RL. The short-term constraint aims to enhance the short-term state safety that the vehicle explores, while the long-term constraint enhances the overall safety of the vehicle throughout the decision-making process, both of which are jointly used to enhance the vehicle safety in the training process. In addition, we develop a safe RL method with dual-constraint optimization based on the Lagrange multiplier to optimize the training process for end-to-end autonomous driving. Comprehensive experiments were conducted on the MetaDrive simulator. Experimental results demonstrate that the proposed method achieves higher safety in continuous state and action tasks, and exhibits higher exploration performance in long-distance decision-making tasks compared with state-of-the-art methods.
Read more9/14/2024

0
Long-Term Fairness in Sequential Multi-Agent Selection with Positive Reinforcement
Bhagyashree Puranik, Ozgur Guldogan, Upamanyu Madhow, Ramtin Pedarsani
While much of the rapidly growing literature on fair decision-making focuses on metrics for one-shot decisions, recent work has raised the intriguing possibility of designing sequential decision-making to positively impact long-term social fairness. In selection processes such as college admissions or hiring, biasing slightly towards applicants from under-represented groups is hypothesized to provide positive feedback that increases the pool of under-represented applicants in future selection rounds, thus enhancing fairness in the long term. In this paper, we examine this hypothesis and its consequences in a setting in which multiple agents are selecting from a common pool of applicants. We propose the Multi-agent Fair-Greedy policy, that balances greedy score maximization and fairness. Under this policy, we prove that the resource pool and the admissions converge to a long-term fairness target set by the agents when the score distributions across the groups in the population are identical. We provide empirical evidence of existence of equilibria under non-identical score distributions through synthetic and adapted real-world datasets. We then sound a cautionary note for more complex applicant pool evolution models, under which uncoordinated behavior by the agents can cause negative reinforcement, leading to a reduction in the fraction of under-represented applicants. Our results indicate that, while positive reinforcement is a promising mechanism for long-term fairness, policies must be designed carefully to be robust to variations in the evolution model, with a number of open issues that remain to be explored by algorithm designers, social scientists, and policymakers.
Read more7/11/2024